标签:手工 技术分享 soft session tle with rand ges ber
tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None, data_format=None, name=None)
官方教程说明:
给定四维的input和filter tensor,计算一个二维卷积
input: A Tensor. type必须是以下几种类型之一: half, float32, float64.filter: A Tensor. type和input必须相同strides: A list of ints.一维,长度4, 在input上切片采样时,每个方向上的滑窗步长,必须和format指定的维度同阶padding: A string from: "SAME", "VALID". padding 算法的类型use_cudnn_on_gpu: An optional bool. Defaults to True.data_format: An optional string from: "NHWC", "NCHW", 默认为"NHWC"。[batch, in_height, in_width, in_channels][batch, in_channels, in_height, in_width]name: 操作名,可选.A Tensor. type与input相同
Given an input tensor of shape [batch, in_height, in_width, in_channels]
and a filter / kernel tensor of shape[filter_height, filter_width, in_channels, out_channels]
conv2d实际上执行了以下操作:
[filter_height * filter_width * in_channels, output_channels].[batch, out_height, out_width, filter_height * filter_width * in_channels].具体来讲,当data_format为NHWC时:
output[b, i, j, k] =
sum_{di, dj, q} input[b, strides[1] * i + di, strides[2] * j + dj, q] *
filter[di, dj, q, k]input 中的每个patch都作用于filter,每个patch都能获得其他patch对filter的训练
需要满足strides[0] = strides[3] = 1. 大多数水平步长和垂直步长相同的情况下:strides = [1, stride, stride, 1].
下面举例来进行说明
在最基本的例子中,没有padding和stride = 1。让我们假设你的input和kernel有:

当您的内核您将收到以下输出: ,它按以下方式计算:
,它按以下方式计算:
TF的conv2d函数批量计算卷积,并使用稍微不同的格式。对于一个输入,它是[batch, in_height, in_width, in_channels]内核的[filter_height, filter_width, in_channels, out_channels]。所以我们需要以正确的格式提供数据:
import tensorflow as tf k = tf.constant([ [1, 0, 1], [2, 1, 0], [0, 0, 1] ], dtype=tf.float32, name=‘k‘) i = tf.constant([ [4, 3, 1, 0], [2, 1, 0, 1], [1, 2, 4, 1], [3, 1, 0, 2] ], dtype=tf.float32, name=‘i‘) kernel = tf.reshape(k, [3, 3, 1, 1], name=‘kernel‘) image = tf.reshape(i, [1, 4, 4, 1], name=‘image‘)
之后,卷积用下式计算:
res = tf.squeeze(tf.nn.conv2d(image, kernel, [1, 1, 1, 1], "VALID")) # VALID means no padding with tf.Session() as sess: print sess.run(res)
并将相当于我们手工计算的,输出结果:
[[ 14. 6.]
[ 6. 12.]]
附上一张图:
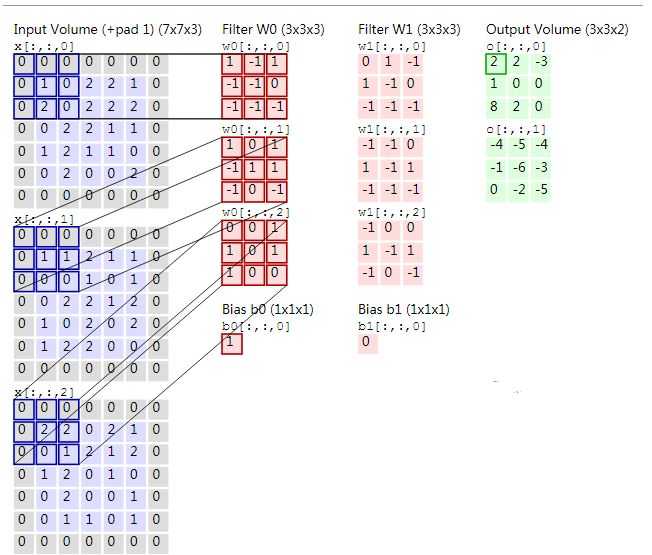
区别SAME和VALID
VALID
input = tf.Variable(tf.random_normal([1,5,5,5])) filter = tf.Variable(tf.random_normal([3,3,5,1])) op = tf.nn.conv2d(input, filter, strides=[1, 1, 1, 1], padding=‘VALID‘)
输出图形:
.....
.xxx.
.xxx.
.xxx.
.....
SAME
input = tf.Variable(tf.random_normal([1,5,5,5])) filter = tf.Variable(tf.random_normal([3,3,5,1])) op = tf.nn.conv2d(input, filter, strides=[1, 1, 1, 1], padding=‘SAME‘)
输出图形:
xxxxx
xxxxx
xxxxx
xxxxx
xxxxx
标签:手工 技术分享 soft session tle with rand ges ber
原文地址:http://www.cnblogs.com/lovephysics/p/7220111.html