标签:用户 持久化 管理类 模块 keep 机制 存储 配置 master
HBASE是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBASE技术可在廉价PC Server上搭建起大规模结构化存储集群。
HBASE的目标是存储并处理大型的数据,更具体来说是仅需使用普通的硬件配置,就能够处理由成千上万的行和列所组成的大型数据。
HBASE是Google Bigtable的开源实现,但是也有很多不同之处。比如:Google Bigtable利用GFS作为其文件存储系统,HBASE利用Hadoop HDFS作为其文件存储系统;Google运行MAPREDUCE来处理Bigtable中的海量数据,HBASE同样利用Hadoop MapReduce来处理HBASE中的海量数据;Google Bigtable利用Chubby作为协同服务,HBASE利用Zookeeper作为对应。
1、传统数据库遇到的问题:
1)数据量很大的时候无法存储
2)没有很好的备份机制
3)数据达到一定数量开始缓慢,很大的话基本无法支撑
2、HBASE优势:
1)线性扩展,随着数据量增多可以通过节点扩展进行支撑
2)数据存储在hdfs上,备份机制健全
3)通过zookeeper协调查找数据,访问速度块。
1、一个或者多个主节点,Hmaster
2、多个从节点,HregionServer
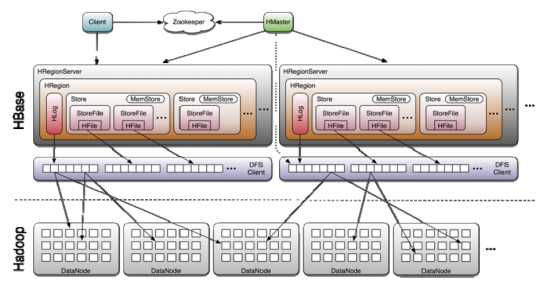
1、 client向hregionserver发送写请求。
2、 hregionserver将数据写到hlog(write ahead log)。为了数据的持久化和恢复。
3、 hregionserver将数据写到内存(memstore)
4、 反馈client写成功。
1、 当memstore数据达到阈值(默认是64M),将数据刷到硬盘,将内存中的数据删除,同时删除Hlog中的历史数据。
2、 并将数据存储到hdfs中。
3、 在hlog中做标记点。
1、 当数据块达到4块,hmaster将数据块加载到本地,进行合并
2、 当合并的数据超过256M,进行拆分,将拆分后的region分配给不同的hregionserver管理
3、 当hregionser宕机后,将hregionserver上的hlog拆分,然后分配给不同的hregionserver加载,修改.META.
4、 注意:hlog会同步到hdfs
1、 通过zookeeper和-ROOT- .META.表定位hregionserver。
2、 数据从内存和硬盘合并后返回给client
3、 数据块会缓存
1、管理用户对Table的增、删、改、查操作;
2、记录region在哪台Hregion server上
3、在Region Split后,负责新Region的分配;
4、新机器加入时,管理HRegion Server的负载均衡,调整Region分布
5、在HRegion Server宕机后,负责失效HRegion Server 上的Regions迁移。
HRegion Server主要负责响应用户I/O请求,向HDFS文件系统中读写数据,是HBASE中最核心的模块。
HRegion Server管理了很多table的分区,也就是region。
HBASE Client使用HBASE的RPC机制与HMaster和RegionServer进行通信
管理类操作:Client与HMaster进行RPC;
数据读写类操作:Client与HRegionServer进行RPC。
标签:用户 持久化 管理类 模块 keep 机制 存储 配置 master
原文地址:http://www.cnblogs.com/Smileing/p/7221221.html