标签:不同 yellow inpu width section groupby 合并 集合 系统
摘要:RDD是Spark中极为重要的数据抽象,这里总结RDD的概念,基本操作Transformation(转换)与Action,RDDs的特性,KeyValue对RDDs的Transformation(转换)。
Resilient distributed datasets(弹性分布式数据集) 。RDDs并行的分布在整个集群中,是Spark分发数据和计算的基础抽象类,一个RDD是一个不可改变的分布式集合对象,Spark中,所有的计算都是通过RDDs的创建,转换操作完成的,一个RDD内部由许多partitions(分片)组成。
分片:每个分片包括一部分数据,partitions可在集群不同节点上计算;分片是Spark并行处理的单元,Spark顺序的,并行的处理分片。
(1) 把一个存在的集合传给SparkContext的parallelize()方法,测试用
val rdd=sc.parallelize(Array(1,2,3,4),4)
第一个参数:待并行化处理的集合;第二个参数:分片个数
(2) 加载外部数据集
val rddText=sc.textFile("hellospark.txt")
从之前的RDD构建一个新的RDD,像map()和filter()
(1)逐元素Transformation
map(): 接收函数,把函数应用到RDD的每一个元素,返回新RDD。
val lines=sc.parallelize(Array("hello","spark","hello","world","!"))
val lines2=lines.map(word=>(word,1))
lines2.foreach(println)
//结果:
(hello,1)
(spark,1)
(hello,1)
(world,1)
(!,1)
filter(): 接收函数,返回只包含满足filter()函数的元素的新RDD。
val lines=sc.parallelize(Array("hello","spark","hello","world","!"))
val lines3=lines.filter(word=>word.contains("hello"))
lines3.foreach(println)
//结果:
hello
hello
flatMap(): 对每个输入元素,输出多个输出元素。flat压扁的意思,将RDD中元素压扁后返回一个新的RDD。
val inputs=sc.textFile("/home/lucy/hellospark.txt")
val lines=inputs.flatMap(line=>line.split(" "))
lines.foreach(println)
//结果
hello
spark
hello
world
hello
!
//文件内容/home/lucy/hellospark.txt
hello spark
hello world
hello !
(2)集合运算
RDDs支持数学集合的计算,例如并集,交集计算
val rdd1=sc.parallelize(Array("red","red","blue","black","white"))
val rdd2=sc.parallelize(Array("red","grey","yellow"))
//去重:
val rdd_distinct=rdd1.distinct()
//去重结果:
white
blue
red
black
//并集:
val rdd_union=rdd1.union(rdd2)
//并集结果:
red
blue
black
white
red
grey
yellow
//交集:
val rdd_inter=rdd1.intersection(rdd2)
//交集结果:
red
//包含:
val rdd_sub=rdd1.subtract(rdd2)
//包含结果:
blue
white
black
在RDD上计算出来一个结果。把结果返回给driver program或保存在文件系统,count(),save。
函数名 功能 例子 结果
collect() 返回RDD的所有元素 rdd.collect() {1,2,3,3}
count() 计数 rdd.count() 4
countByValue() 返回一个map表示唯一元素出现的个数 rdd.countByValue() {(1,1),(2,1),(3,2)}
take(num) 返回几个元素 rdd.take(2) {1,2}
top(num) 返回前几个元素 rdd.top(2) {3,3}
takeOrdered 返回基于提供的排序算法的前几个元素 rdd.takeOrdered(2)(myOrdering) {3,3}
(num)(ordering)
takeSample 取样例 rdd.takeSample(false,1) 不确定
(withReplacement,num,[seed])
reduce(func) 合并RDD中元素 rdd.reduce((x,y)=>x+y) 9
fold(zero)(func) 与reduce()相似提供zero value rdd.fold(0)((x,y)=>x+y) 9
foreach(func) 对RDD的每个元素作用函数,什么也不返回 rdd.foreach(func) 无
1.血统关系图:
Spark维护着RDDs之间的依赖关系和创建关系,叫做血统关系图,Spark使用血统关系图来计算每个RDD的需求和恢复丢失的数据
2.延迟计算
Spark对RDDs的计算是,他们第一次使用action操作的时候。Spark内部记录metadata表明transformations操作已经被响应了。加载数据也是延迟计算,数据只有 在必要的时候,才会被加载进去。
3.RDD.persist():
默认每次在RDDs上面进行action操作时,Spark都重新计算RDDs。如果想重复利用一个RDD,可以使用RDD.persist()。upersist()方法从缓存中移除。
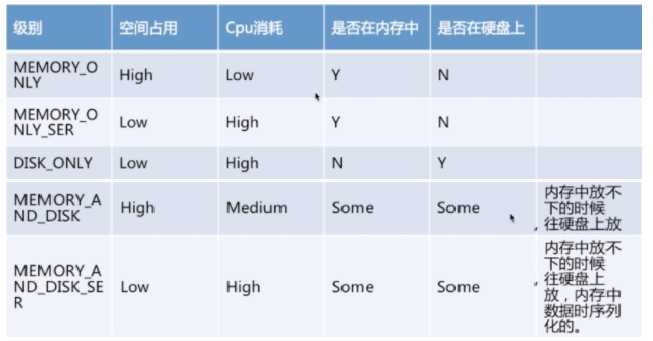
创建KeyValue对RDDs:
val rdd3=sc.parallelize(Array((1,2),(3,4),(3,6)))
KeyValue对RDDs的Transformation(转换):
(1)reduceByKey(func) 把相同key的结合
val rdd4=rdd3.reduceByKey((x,y)=>x+y)
//结果
(1,2)
(3,10)
(2)groupByKey 把相同的key的values分组
val rdd5=rdd3.groupByKey()
//结果
(1,CompactBuffer(2))
(3,CompactBuffer(4, 6))
(3)mapValues() 函数作用于pairRDD的每个元素,key不变
val rdd6=rdd3.mapValues(x=>x+1)
//结果
(1,3)
(3,5)
(3,7)
(4)keys/values
rdd3.keys.foreach(println)
1
3
3
rdd3.values.foreach(println)
2
4
6
(5)sortByKey
val rdd7=rdd3.sortByKey()
//结果
(1,2)
(3,4)
(3,6)
(6)combineByKey(): (createCombiner,mergeValue,mergeCombiners,partitioner)
最常用的基于key的聚合函数,返回的类型可以与输入类型不一样。许多基于key的聚合函数都用到了它,像groupByKey()
原理:遍历partition中的元素,元素的key,要么之前见过的,要么不是。如果是新元素,使用我们提供的createCombiner()函数,如果是这个partition中已经存在的key,就会使用mergeValue()函数,合计每个partition的结果的时候,使用mergeCombiner()函数
例子:求平均值
val score=sc.parallelize(Array(("Tom",80.0),("Tom",90.0),("Tom",85.0),("Ben",85.0),("Ben",92.0),("Ben",90.0)))
val score2=score.combineByKey(score=>(1,score),(c1:(Int,Double),newScore)=>(c1._1+1,c1._2+newScore),(c1:(Int,Double),c2:(Int,Double))=>(c1._1+c2._1,c1._2+c2._2))
//结果
(Ben,(3,267.0))
(Tom,(3,255.0))
val average=score2.map{case(name,(num,score))=>(name,score/num)}
//结果
(Ben,89.0)
(Tom,85.0)
标签:不同 yellow inpu width section groupby 合并 集合 系统
原文地址:http://www.cnblogs.com/wonglu/p/7252440.html