标签:名称 binlog 消费 keyword 效果 个数 lis 数据 系统
业务执行失败之后隔10分钟重试一次
类似的场景比较多 简单的处理方式就是使用定时任务 假如数据比较多的时候 有的数据可能延迟比较严重,而且越来越多的定时业务导致任务调度很繁琐不好管理。
目前可以考虑使用rabbitmq来满足需求 但是不打算使用,因为目前太多的业务使用了另外的MQ中间件。
开发前需要考虑的问题?
消费端如何消费
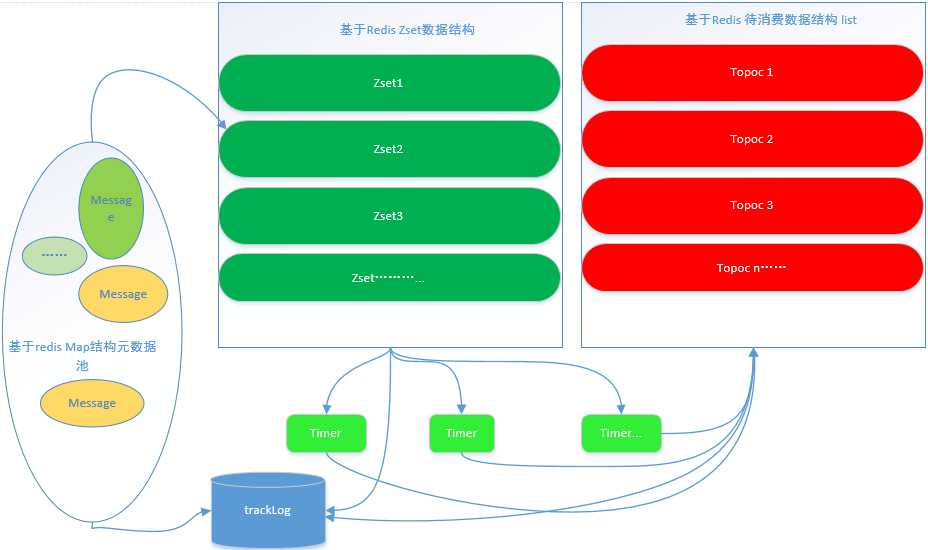
当然初步选用redis作为数据缓存的主要原因是因为redis自身支持zset的数据结构(score 延迟时间毫秒) 这样就少了排序的烦恼而且性能还很高,正好我们的需求就是按时间维度去判定执行的顺序 同时也支持map list数据结构。
简单定义一个消息数据结构
|
private String topic;/***topic**/
private String id;/***自动生成 全局惟一 snowflake**/
private String bizKey;
private long delay;/***延时毫秒数**/
private int priority;//优先级
private long ttl;/**消费端消费的ttl**/
private String body;/***消息体**/
private long createTime=System.currentTimeMillis();
private int status= Status.WaitPut.ordinal();
|
运行原理:
Map来存储元数据。id作为key,整个消息结构序列化(json/…)之后作为value,放入元消息池中。id放入其中(有N个)一个zset有序列表中,以createTime+delay+priority作为score。修改状态为正在延迟中zset有序列表中top 10的数据 。 如果数据score>=当前时间毫秒就取出来,根据topic重新放入一个新的可消费列表(list)中,在zset中删除已经取出来的数据,并修改状态为待消费zset列表中,修改状态为正在延迟。如果满足修改状态为已消费。或者直接删除元数据。因为涉及到不同程序语言的问题,所以当前默认支持http访问方式。
用nginx暴露服务,配置为轮询 在添加延迟消息的时候就可以流量平均分配。
目前系统中客户端并没有采用HTTP长连接的方式来消费消息,而是采用MQ的方式来消费数据这样客户端就可以不用关心延迟消息队列。只需要在发送MQ的时候拦截一下 如果是延迟消息就用延迟消息系统处理。
实现恢复的原理 正常情况下一般都是记录日志,比如mysql的binlog等。
这里我们直接采用mysql数据库作为记录日志。
目前打算创建以下2张表:
zset扫描线程Name、host/ip定义zset扫描线程Name是为了更清楚的看到消息被分发到具体哪个zset中。前提是zset的key和监控zset的线程名称要有点关系 这里也可以是zset key。
举个栗子
假如redis服务器宕机了,重启之后发现数据也没有了。所以这个恢复是很有必要的,只需要从表1也就是消息表中把消息状态不等于已消费的数据全部重新分发到延迟队列中去,然后同步一下状态就可以了。
当然恢复单个任务也可以这么干。
分布式协调还是选用zookeeper吧。
如果有多个实例最多同时只能有1个实例工作 这样就避免了分布式竞争锁带来的坏处,当然如果业务需要多个实例同时工作也是支持的,也就是一个消息最多只能有1个实例处理,可以选用zookeeper或者redis就能实现分布式锁了。
最终做了一下测试多实例同时运行,可能因为会涉及到锁的问题性能有所下降,反而单机效果很好。所以比较推荐基于docker的主备部署模式。
支持zset队列个数可配置 避免大数据带来高延迟的问题。
目前存在日志和redis元数据有可能不一致的问题 如mysql挂了,写日志不会成功。
设计图:
标签:名称 binlog 消费 keyword 效果 个数 lis 数据 系统
原文地址:http://www.cnblogs.com/peachyy/p/7398430.html