标签:解决 显示中文 nbsp 北京天安门 技术分享 方法 了解 还原 台湾
详细课件:http://www.cnblogs.com/alex3714/articles/5465198.html
字符编码
支持中文的第一张表就是GB2312
1980 gb2312 6700+
1995 gbk1.0 20000
2000 gb18030 27000
big5 台湾
unicode 万国码 支持所有国家和地区的编码
2^16 = 65535 = 存一个字符 统一占用2个字节
为了解决字符字节翻倍的问题,出现了UTF-8
UTF-8 = unicode 的扩展及,可变长的字符编码集
ASSIC==>GB2312==>GBK1.0==>GB18030
ASSIC==>UNICODE==>UTF-8
python3.0默认编码是nuicode支持中文
python2.0默认编码默认是ASSIC
如果用python2执行以下代码会报错,因为不支持中文,所以需要加上一行红色代码,终于搞懂为什么不需要在python3中加上这行代码了
#!-*- coding:utf-8 -*-
print "我爱北京天安门!"

windows默认编码是GBK,所以看UTF-8就看不了,所以出现以上错误乱码
解决方法:2种类
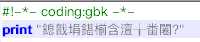
#!-*- coding:gbk -*- print "我爱北京天安门!"
但是如果你使用notepad++的话,默认是utf-8,所以还需要转换一下才行

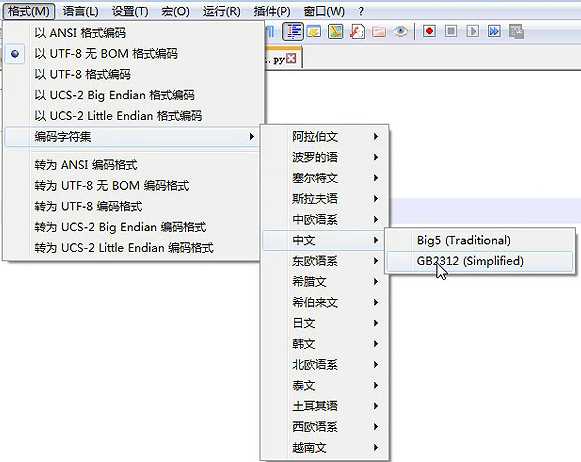
所以最好不要使用notepad++这个恶心的编辑器...这个编辑器最大的问题就是编码问题,fuck notepad++
因为unicode是向下兼容gb2312的,所以以下代码前加上u,就是可以直接显示中文了
#!-*- coding:utf-8-*- print u"我爱北京天安门"
另外一种编码的写法
#coding:utf-8 print "我爱北京天安门"
把cmd编码还原成GBK格式,在cmd命令行中输入chcp 936
标签:解决 显示中文 nbsp 北京天安门 技术分享 方法 了解 还原 台湾
原文地址:http://www.cnblogs.com/darkalex001/p/7484748.html