标签:个数 family ack 删除 瓶颈 conf 客户端 comm 使用场景
目录
1.redis搭建
2.redis和memcached
3.redis技术总结
1.redis搭建
一、下载最新版
wget http://redis.googlecode.com/files/redis-2.0.0-rc4.tar.gz
二、解压缩
tar -xvf redis-2.0.0-rc4.tar.gz
三、安装C/C++的编译组件(非必须)
apt-get install build-essential
四、编译
cd redis-2.0.0-rc4
make
make命令执行完成后,会在当前目录下生成本个可执行文件,分别是redis-server、redis-cli、redis-benchmark、redis-stat,它们的作用如下:
在后面会有这几个命令的说明,当然是从网上抄的。。。
五、修改配置文件
/etc/sysctl.conf
添加
vm.overcommit_memory=1
刷新配置使之生效
sysctl vm.overcommit_memory=1
补充介绍:
**如果内存情况比较紧张的话,需要设定内核参数:
echo 1 > /proc/sys/vm/overcommit_memory
内核参数说明如下:
overcommit_memory文件指定了内核针对内存分配的策略,其值可以是0、1、2。
0, 表示内核将检查是否有足够的可用内存供应用进程使用;如果有足够的可用内存,内存申请允许;否则,内存申请失败,并把错误返回给应用进程。
1, 表示内核允许分配所有的物理内存,而不管当前的内存状态如何。
2, 表示内核允许分配超过所有物理内存和交换空间总和的内存
**编辑redis.conf配置文件(/etc/redis.conf),按需求做出适当调整,比如:
daemonize yes #转为守护进程,否则启动时会每隔5秒输出一行监控信息
save 60 1000 #减小改变次数,其实这个可以根据情况进行指定
maxmemory 256000000 #分配256M内存
在我们成功安装Redis后,我们直接执行redis-server即可运行Redis,此时它是按照默认配置来运行的(默认配置甚至不是后台运 行)。我们希望Redis按我们的要求运行,则我们需要修改配置文件,Redis的配置文件就是我们上面第二个cp操作的redis.conf文件,目前 它被我们拷贝到了/usr/local/redis/etc/目录下。修改它就可以配置我们的server了。如何修改?下面是redis.conf的主 要配置参数的意义:
下面是一个略做修改后的配置文件内容:
daemonize yes
pidfile /usr/local/redis/var/redis.pid
port 6379
timeout 300
loglevel debug
logfile /usr/local/redis/var/redis.log
databases 16
save 900 1
save 300 10
save 60 10000
rdbcompression yes
dbfilename dump.rdb
dir /usr/local/redis/var/
appendonly no
appendfsync always
glueoutputbuf yes
shareobjects no
shareobjectspoolsize 1024
将上面内容写为redis.conf并保存到/usr/local/redis/etc/目录下
然后在命令行执行:
/usr/local/redis/bin/
|
1 |
/usr/local/redis/bin/redis-server /usr/local/redis/etc/redis.conf |
即可在后台启动redis服务,这时你通过
|
1 |
telnet 127.0.0.1 6379 |
即可连接到你的redis服务。
六、启动服务并验证
启动服务器
./redis-server
或
$redis-server /etc/redis.conf
查看是否成功启动
$ ps -ef | grep redis
或
./redis-cli ping
PONG
七、启动命令行客户端赋值取值
redis-cli set mykey somevalue
./redis-cli get mykey
八、关闭服务
$ redis-cli shutdown
#关闭指定端口的redis-server
$redis-cli -p 6380 shutdown
九、客户端也可以使用telnet形式连接。
[root@dbcache conf]# telnet 127.0.0.1 6379
Trying 127.0.0.1...
Connected to dbcache (127.0.0.1).
Escape character is ‘^]‘.
set foo 3
bar
+OK
get foo
$3
bar
^]
telnet> quit
Connection closed.
安装不成功的情况下看下面 yum list中可以看到tcl 8.4
wget http://download.redis.io/redis-stable.tar.gz
tar xvzf redis-stable.tar.gz
cd redis-stable
make
前面3步应该没有问题,主要的问题是执行make的时候,出现了异常。
异常一:
make[2]: cc: Command not found
异常原因:没有安装gcc
解决方案:yum install gcc-c++
异常二:
zmalloc.h:51:31: error: jemalloc/jemalloc.h: No such file or directory
异常原因:一些编译依赖或原来编译遗留出现的问题
解决方案:make distclean。清理一下,然后再make。
在make成功以后,需要make test。在make test出现异常。
异常一:
couldn‘t execute "tclsh8.5": no such file or directory
异常原因:没有安装tcl
解决方案:yum install -y tcl。
在make成功以后,会在src目录下多出一些可执行文件:redis-server,redis-cli等等。
方便期间用cp命令复制到usr目录下运行。
cp redis-server /usr/local/bin/
cp redis-cli /usr/local/bin/
然后新建目录,存放配置文件
mkdir /etc/redis
mkdir /var/redis
mkdir /var/redis/log
mkdir /var/redis/run
mkdir /var/redis/6379
在redis解压根目录中找到配置文件模板,复制到如下位置。
cp redis.conf /etc/redis/6379.conf
通过vim命令修改
daemonize yes
pidfile /var/redis/run/redis_6379.pid
logfile /var/redis/log/redis_6379.log
dir /var/redis/6379
最后运行redis:
$ redis-server /etc/redis/6379.conf
tcl安装
先去这里下载:
www.activestate.com
http://downloads.activestate.com/ActiveTcl/Linux/8.5.0/
然后解压
对于.tar.gz的后缀文件可以使用tar zxvf 。。。.tar.gz解压
安装 Tcl
为编译 Tcl 做准备:
cd 到tcl文件夹里然后
cd unix
./configure
编译软件包:
make
安装软件包:
make install
这个时候在命令行就可以输入tclsh进入tcl解释器了
Java 调用redis http://www.cnblogs.com/edisonfeng/p/3571870.html
2.redis和memcached
找的这篇文章的时候,一眼望去就是黑memcache的文章,这篇文章突出redis的强大
1. Redis中,并不是所有的数据都一直存储在内存中的,这是和Memcached相比一个最大的区别。
2. Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,hash等数据结构的存储。
3. Redis支持数据的备份,即master-slave模式的数据备份。
4. Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用。
Redis在很多方面具备数据库的特征,或者说就是一个数据库系统,而Memcached只是简单的K/V缓存
来看下Redis作者对比redis和memcache
来源:《Is memcached a dinosaur in comparison to Redis?》(相比Redis,Memcached真的过时了吗?)
You should not care too much about performances. Redis is faster per core with small values, but memcached is able to use multiple cores with a single executable and TCP port without help from the client. Also memcached is faster with big values in the order of 100k. Redis recently improved a lot about big values (unstable branch) but still memcached is faster in this use case. The point here is: nor one or the other will likely going to be your bottleneck for the query-per-second they can deliver.
没有必要过多的关心性能,因为二者的性能都已经足够高了。由于Redis只使用单核,而Memcached可以使用多核,所以在比较上,平均每一个核上 Redis在存储小数据时Memcached性能更高。而在100k以上的数据中,Memcached性能要高于Redis,虽然Redis最近也在存储 大数据的性能上进行优化,但是比起Memcached,还是稍有逊色。说了这么多,结论是,无论你使用哪一个,每秒处理请求的次数都不会成为瓶颈。(比如 瓶颈可能会在网卡)
You should care about memory usage. For simple key-value pairs memcached is more memory efficient. If you use Redis hashes, Redis is more memory efficient. Depends on the use case.
如果要说内存使用效率,使用简单的key-value存储的话,Memcached的内存利用率更高,而如果Redis采用hash结构来做key-value存储,由于其组合式的压缩,其内存利用率会高于Memcached。当然,这和你的应用场景和数据特性有关。
You should care about persistence and replication, two features only available in Redis. Even if your goal is to build a cache it helps that after an upgrade or a reboot your data are still there.
如果你对数据持久化和数据同步有所要求,那么推荐你选择Redis,因为这两个特性Memcached都不具备。即使你只是希望在升级或者重启系统后缓存数据不会丢失,选择Redis也是明智的。
You should care about the kind of operations you need. In Redis there are a lot of complex operations, even just considering the caching use case, you often can do a lot more in a single operation, without requiring data to be processed client side (a lot of I/O is sometimes needed). This operations are often as fast as plain GET and SET. So if you don‘t need just GET/SET but more complex things Redis can help a lot (think at timeline caching).
当 然,最后还得说到你的具体应用需求。Redis相比Memcached来说,拥有更多的数据结构和并支持更丰富的数据操作,通常在Memcached里, 你需要将数据拿到客户端来进行类似的修改再set回去。这大大增加了网络IO的次数和数据体积。在Redis中,这些复杂的操作通常和一般的 GET/SET一样高效。所以,如果你需要缓存能够支持更复杂的结构和操作,那么Redis会是不错的选择。
1、 Redis和Memcache都是将数据存放在内存中,都是内存数据库。不过memcache还可用于缓存其他东西,例如图片、视频等等。
2、Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,hash等数据结构的存储。
3、虚拟内存--Redis当物理内存用完时,可以将一些很久没用到的value 交换到磁盘
4、过期策略--memcache在set时就指定,例如set key1 0 0 8,即永不过期。Redis可以通过例如expire 设定,例如expire name 10
5、分布式--设定memcache集群,利用magent做一主多从;redis可以做一主多从。都可以一主一从
6、存储数据安全--memcache挂掉后,数据没了;redis可以定期保存到磁盘(持久化)
7、灾难恢复--memcache挂掉后,数据不可恢复; redis数据丢失后可以通过aof恢复
8、Redis支持数据的备份,即master-slave模式的数据备份。
3.redis技术总结
简介:
redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都 支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排 序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文 件,并且在此基础上实现了master-slave(主从)同步。
redis使用了两种文件格式:全量数据和增量请求。
redis的存储分为内存存储、磁盘存储和log文件三部分,配置文件中有三个参数对其进行配置。
save seconds updates,save配置,指出在多长时间内,有多少次更新操作,就将数据同步到数据文件。这个可以多个条件配合,比如默认配置文件中的设置,就设置了三个条件。
appendonly yes/no ,appendonly配置,指出是否在每次更新操作后进行日志记录,如果不开启,可能会在断电时导致一段时间内的数据丢失。因为redis本身同步数据 文件是按上面的save条件来同步的,所以有的数据会在一段时间内只存在于内存中。
appendfsync no/always/everysec ,appendfsync配置,no表示等操作系统进行数据缓存同步到磁盘,always表示每次更新操作后手动调用fsync()将数据写到磁盘,everysec表示每秒同步一次。
官方网址:redis.io
Redis数据库完全在内存中,使用磁盘仅用于持久性。
相比许多键值数据存储,Redis拥有一套较为丰富的数据类型。
Redis可以将数据复制到任意数量的从服务器。
异常快速:Redis的速度非常快,每秒能执行约11万集合,每秒约81000+条记录。
支持丰富的数据类型:Redis支持最大多数开发人员已经知道像列表,集合,有序集合,散列数据类型。这使得它非常容易解决各种各样的问题,因为我们知道哪些问题是可以处理通过它的数据类型更好。
操作都是原子性:所有Redis操作是原子的,这保证了如果两个客户端同时访问的Redis服务器将获得更新后的值。
多功能实用工具:Redis是一个多实用的工具,可以在多个用例如缓存,消息,队列使用(Redis原生支持发布/订阅),任何短暂的数据,应用程序,如Web应用程序会话,网页命中计数等。
应用场景:
下面列出11种Web应用场景,在这些场景下可以充分的利用Redis的特性,大大提高效率。
1.在主页中显示最新的项目列表。
Redis使用的是常驻内存的缓存,速度非常快。LPUSH用来插入一个内容ID,作为关键字存储在列表头部。LTRIM用来限制列表中的项目数最多为5000。如果用户需要的检索的数据量超越这个缓存容量,这时才需要把请求发送到数据库。
2.删除和过滤。
如果一篇文章被删除,可以使用LREM从缓存中彻底清除掉。
3.排行榜及相关问题。
排行榜(leader board)按照得分进行排序。ZADD命令可以直接实现这个功能,而ZREVRANGE命令可以用来按照得分来获取前100名的用户,ZRANK可以用来获取用户排名,非常直接而且操作容易。
4.按照用户投票和时间排序。
这就像Reddit的排行榜,得分会随着时间变化。LPUSH和LTRIM命令结合运用,把文章添加到一个列表中。一项后台任务用来获取列表,并重新计算列表的排序,ZADD命令用来按照新的顺序填充生成列表。列表可以实现非常快速的检索,即使是负载很重的站点。
5.过期项目处理。
使用unix时间作为关键字,用来保持列表能够按时间排序。对current_time和time_to_live进行检索,完成查找过期项目的艰巨任务。另一项后台任务使用ZRANGE...WITHSCORES进行查询,删除过期的条目。
6.计数。
进行各种数据统计的用途是非常广泛的,比如想知道什么时候封锁一个IP地址。INCRBY命令让这些变得很容易,通过原子递增保持计数;GETSET用来重置计数器;过期属性用来确认一个关键字什么时候应该删除。
7.特定时间内的特定项目。
这是特定访问者的问题,可以通过给每次页面浏览使用SADD命令来解决。SADD不会将已经存在的成员添加到一个集合。
8.实时分析正在发生的情况,用于数据统计与防止垃圾邮件等。
使用Redis原语命令,更容易实施垃圾邮件过滤系统或其他实时跟踪系统。
9.Pub/Sub。
在更新中保持用户对数据的映射是系统中的一个普遍任务。Redis的pub/sub功能使用了SUBSCRIBE、UNSUBSCRIBE和PUBLISH命令,让这个变得更加容易。
10.队列。
在当前的编程中队列随处可见。除了push和pop类型的命令之外,Redis还有阻塞队列的命令,能够让一个程序在执行时被另一个程序添加到队列。你也可以做些更有趣的事情,比如一个旋转更新的RSS feed队列。
11.缓存。
Redis缓存使用的方式与memcache相同。
网络应用不能无休止地进行模型的战争,看看这些Redis的原语命令,尽管简单但功能强大,把它们加以组合,所能完成的就更无法想象。当然,你可以专门编写代码来完成所有这些操作,但Redis实现起来显然更为轻松。
数据类型的使用:
Redis最为常用的数据类型主要有以下五种:
在具体描述这几种数据类型之前,我们先通过一张图了解下Redis内部内存管理中是如何描述这些不同数据类型的:
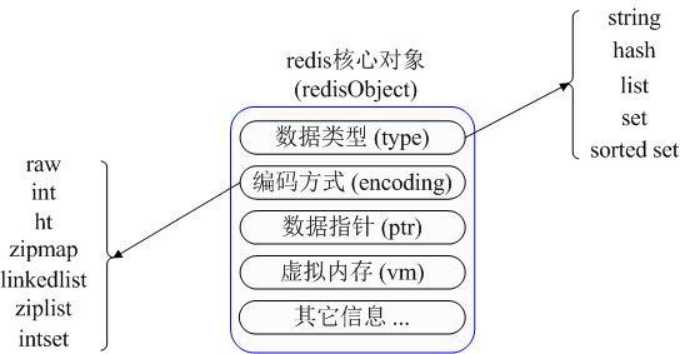
首先Redis内部使用一个redisObject对象来表示所有的key和value,redisObject最主要的信息如上图所示:type 代表一个value对象具体是何种数据类型,encoding是不同数据类型在redis内部的存储方式,比如:type=string代表value存 储的是一个普通字符串,那么对应的encoding可以是raw或者是int,如果是int则代表实际redis内部是按数值型类存储和表示这个字符串 的,当然前提是这个字符串本身可以用数值表示,比如:"123" "456"这样的字符串。
这里需要特殊说明一下vm字段,只有打开了Redis的虚拟内存功能,此字段才会真正的分配内存,该功能默认是关闭状态的,该功能会在后面具体描 述。通过上图我们可以发现Redis使用redisObject来表示所有的key/value数据是比较浪费内存的,当然这些内存管理成本的付出主要也 是为了给Redis不同数据类型提供一个统一的管理接口,实际作者也提供了多种方法帮助我们尽量节省内存使用,我们随后会具体讨论。
下面我们先来逐一的分析下这五种数据类型的使用和内部实现方式:
常用命令:
set,get,decr,incr,mget 等。
应用场景:
String是最常用的一种数据类型,普通的key/value存储都可以归为此类,这里就不所做解释了。
实现方式:
String在redis内部存储默认就是一个字符串,被redisObject所引用,当遇到incr,decr等操作时会转成数值型进行计算,此时redisObject的encoding字段为int。
常用命令:
hget,hset,hgetall 等。
应用场景:
我们简单举个实例来描述下Hash的应用场景,比如我们要存储一个用户信息对象数据,包含以下信息:
用户ID为查找的key,存储的value用户对象包含姓名,年龄,生日等信息,如果用普通的key/value结构来存储,主要有以下2种存储方式:
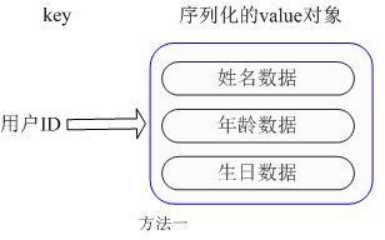
第一种方式将用户ID作为查找key,把其他信息封装成一个对象以序列化的方式存储,这种方式的缺点是,增加了序列化/反序列化的开销,并且在需要修改其中一项信息时,需要把整个对象取回,并且修改操作需要对并发进行保护,引入CAS等复杂问题。
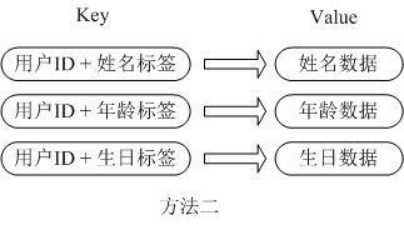
第二种方法是这个用户信息对象有多少成员就存成多少个key-value对儿,用用户ID+对应属性的名称作为唯一标识来取得对应属性的值,虽然省去了序列化开销和并发问题,但是用户ID为重复存储,如果存在大量这样的数据,内存浪费还是非常可观的。
那么Redis提供的Hash很好的解决了这个问题,Redis的Hash实际是内部存储的Value为一个HashMap,并提供了直接存取这个Map成员的接口,如下图:
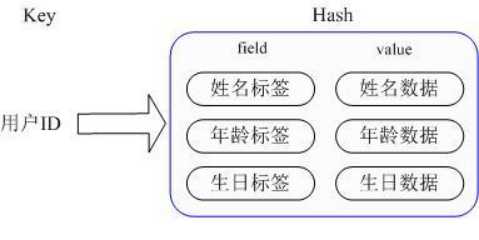
也就是说,Key仍然是用户ID, value是一个Map,这个Map的key是成员的属性名,value是属性值,这样对数据的修改和存取都可以直接通过其内部Map的 Key(Redis里称内部Map的key为field), 也就是通过 key(用户ID) + field(属性标签) 就可以操作对应属性数据了,既不需要重复存储数据,也不会带来序列化和并发修改控制的问题。很好的解决了问题。
这里同时需要注意,Redis提供了接口(hgetall)可以直接取到全部的属性数据,但是如果内部Map的成员很多,那么涉及到遍历整个内部 Map的操作,由于Redis单线程模型的缘故,这个遍历操作可能会比较耗时,而另其它客户端的请求完全不响应,这点需要格外注意。
实现方式:
上面已经说到Redis Hash对应Value内部实际就是一个HashMap,实际这里会有2种不同实现,这个Hash的成员比较少时Redis为了节省内存会采用类似一维数 组的方式来紧凑存储,而不会采用真正的HashMap结构,对应的value redisObject的encoding为zipmap,当成员数量增大时会自动转成真正的HashMap,此时encoding为ht。
常用命令:
lpush,rpush,lpop,rpop,lrange等。
应用场景:
Redis list的应用场景非常多,也是Redis最重要的数据结构之一,比如twitter的关注列表,粉丝列表等都可以用Redis的list结构来实现,比较好理解,这里不再重复。
实现方式:
Redis list的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销,Redis内部的很多实现,包括发送缓冲队列等也都是用的这个数据结构。
常用命令:
sadd,spop,smembers,sunion 等。
应用场景:
Redis set对外提供的功能与list类似是一个列表的功能,特殊之处在于set是可以自动排重的,当你需要存储一个列表数据,又不希望出现重复数据时,set 是一个很好的选择,并且set提供了判断某个成员是否在一个set集合内的重要接口,这个也是list所不能提供的。
实现方式:
set 的内部实现是一个 value永远为null的HashMap,实际就是通过计算hash的方式来快速排重的,这也是set能提供判断一个成员是否在集合内的原因。
常用命令:
zadd,zrange,zrem,zcard等
使用场景:
Redis sorted set的使用场景与set类似,区别是set不是自动有序的,而sorted set可以通过用户额外提供一个优先级(score)的参数来为成员排序,并且是插入有序的,即自动排序。当你需要一个有序的并且不重复的集合列表,那么 可以选择sorted set数据结构,比如twitter 的public timeline可以以发表时间作为score来存储,这样获取时就是自动按时间排好序的。
实现方式:
Redis sorted set的内部使用HashMap和跳跃表(SkipList)来保证数据的存储和有序,HashMap里放的是成员到score的映射,而跳跃表里存放的 是所有的成员,排序依据是HashMap里存的score,使用跳跃表的结构可以获得比较高的查找效率,并且在实现上比较简单。
Redis和Memcached的区别:
1、Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
2、Redis支持数据的备份,即master-slave模式的数据备份。
3、Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用。
4、在Redis中,并不是所有的数据都一直存储在内存中的。
5、Redis使用最佳方式是全部数据in-memory。
6、Redis更多场景是作为Memcached的替代者来使用。
7、当存储的数据不能被剔除时,使用Redis更合适。
8、存储数据安全,memcache挂掉后,数据就没了;redis可以定期保存到磁盘(持久化)。
9、灾难恢复,memcache挂掉后,数据不可恢复;redis数据丢失后可以通过aof恢复。
标签:个数 family ack 删除 瓶颈 conf 客户端 comm 使用场景
原文地址:http://www.cnblogs.com/hotazhou/p/7500618.html