标签:style blog http color os java strong 文件 数据
对技术,我还是抱有敬畏之心的。
Hadoop是一个开源分布式云计算平台,基于Map/Reduce模型的,处理海量数据的离线分析工具。基于Java开发,建立在HDFS上,最早由Google提出,有兴趣的同学可以从Google三驾马车: GFS,mapreduce,Bigtable开始了解起,这里我不详细介绍了,因为网上的资料实在是太多了。
Hadoop项目的结构如下:
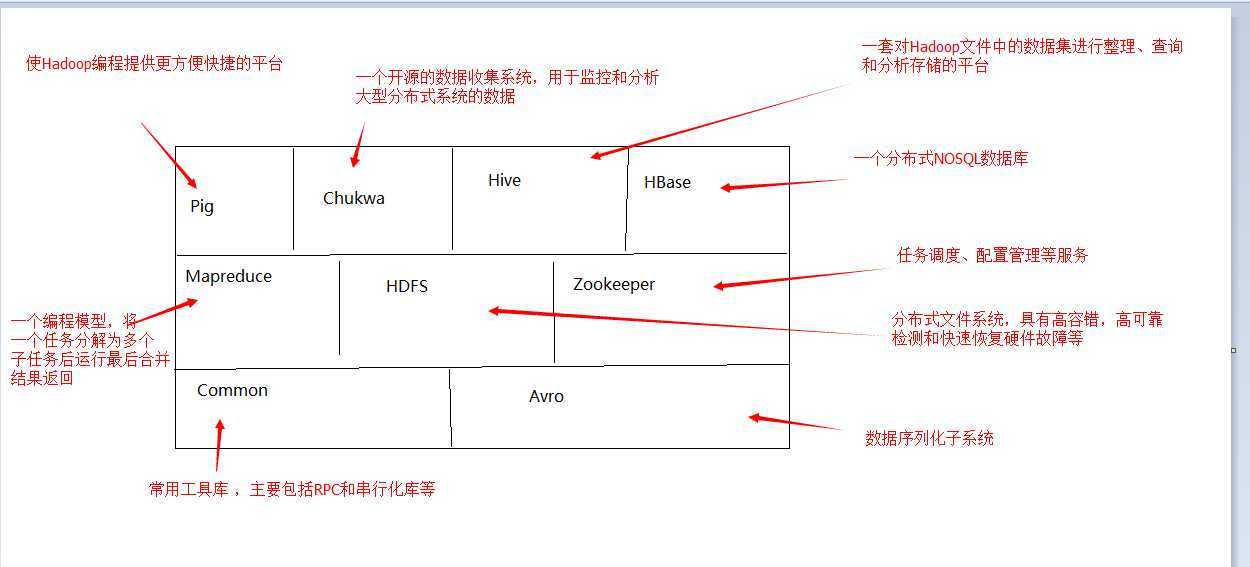
Hadoop中最重要的应该就是HDFS和Mapreduce了,从HDFS讲起:
HDFS主要由以下优点:
1)、支持超大文件,一般来说,一个Hadoop文件系统可以轻松的存储TB、PB级别的数据。
2)、检测和快速应对硬件故障,在大量通用的廉价硬件构建的集群上,特别是硬件故障很常见,一班的HDFS系统由成百上千台存储着数据文件的服务器组成,越多的服务器也就意味着高故障率,因此故障检测和制动恢复就是HDFS的一个设计目标。
3)、流式数据访问方式,HDFS要处理的数据规模都比较大,应用程序一次需要访问大量数据,适用于批量处理而非用户交互式处理数据,HDFS以流式方式访问数据,注重的是数据的高吞吐量而非访问速度。 HDFS是建立在最有效的数据处理模式是一次写多次读(write-once,read-many-times)的模式的概念之上的,当写入操作被关闭后,想要往文件里面更新一些内容是不受支持。HDFS存储的数据集作为hadoop的分析对象。在数据集生成后,长时间在此数据集上进行各种分析。每次分析都将设计该数据集的大部分数据甚至全部数据,因此读取整个数据集的时间延迟比读取第一条记录的时间延迟更重要。(流式读取最小化了硬盘的寻址开销,只需要寻址一次,然后就一直读啊读。毕竟每一个文件块都被划分为64M大小了。硬盘的物理构造导致寻址开销的优化跟不上读取开销。所以流式读取更加适合硬盘的本身特性。当然大文件的特点也更适合流式读取。与流数据访问对应的是随机数据访问,它要求定位、查询或修改数据的延迟较小,传统关系型数据库很符合这一点)
4)、简化的一致性模型,大部分的HDFS的数据操纵文件都是一次写入,多次读取,一个文件一旦经过创建、写入和关闭后,一半就不需要修改了,这样简单的一致性模型,有利于提供高吞吐量的数据访问模型。
对于上述设计目标,我们会发现,这些在一些场景中是优势,但是在默写情况下,会成为其局限性,主要有以下几点:
1)、不适合低延迟的数据访问,HDFS是为处理大规模的数据而生的,主要是为达到高的数据吞吐量而设计的,HDFS为了高吞吐量,可以牺牲低延迟,因此我们不能奢望能够快速的读出HDFS里的数据。
如果想在Hadoop上对数据做低延迟或实时的数据访问,在其上HBase是一个很好的解决方案。但是Hbase是一个NOSQL,即面向列的数据库。
2)、不能搞笑的存储大量小文件,在HDFS中,有NameNode(Master)节点来管理文件系统的元数据,已相应客户端请求返回文件位置等,因此文件数量大小的限制就由NameNode(具体的来说是由其内存大小)来决定;另外,在一次数据访问中,更多的小文件也意味着更多的磁盘寻址操作,以及更多的文件的打开与关闭的开销,这会大大降低数据的吞吐量,这都有违HDFS的设计目标,也会给NameNode带来更大的工作压力。
3)、不支持多用户的数据写入和随机访问与修改文件,在一个HDFS写操作中只能有一个用户对一个文件写操作,并且自能通过追加的方式将数据写到文件末尾,在读一个文件的时候也只能从文件头部顺序读取文件数据。
目前HDFS还不支持多个用户对同一个文件的并发写操作、随机访问和修改数据。
HDFS的架构如下:
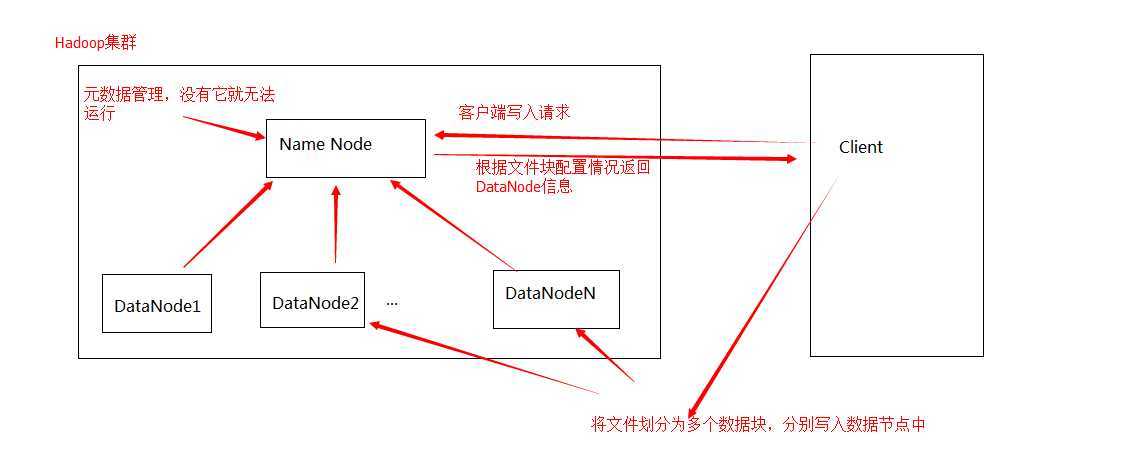
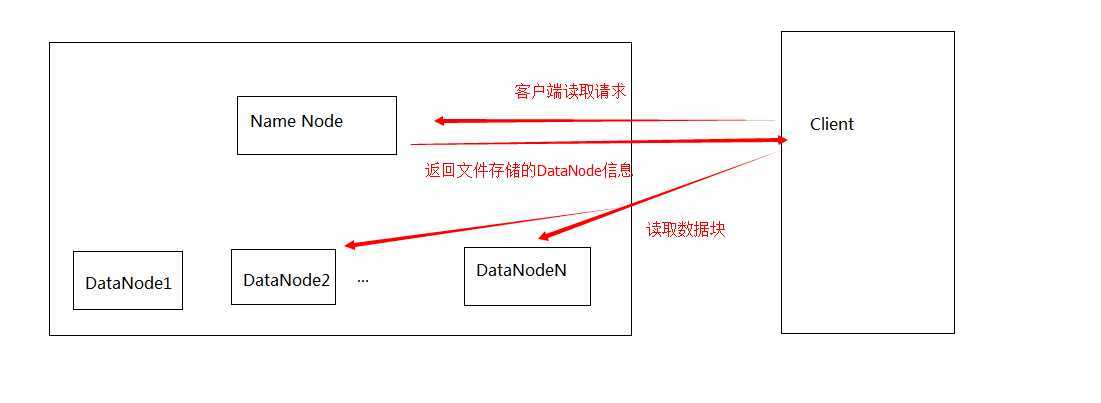
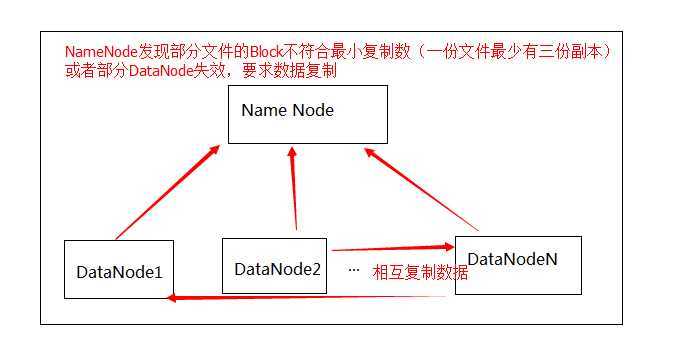
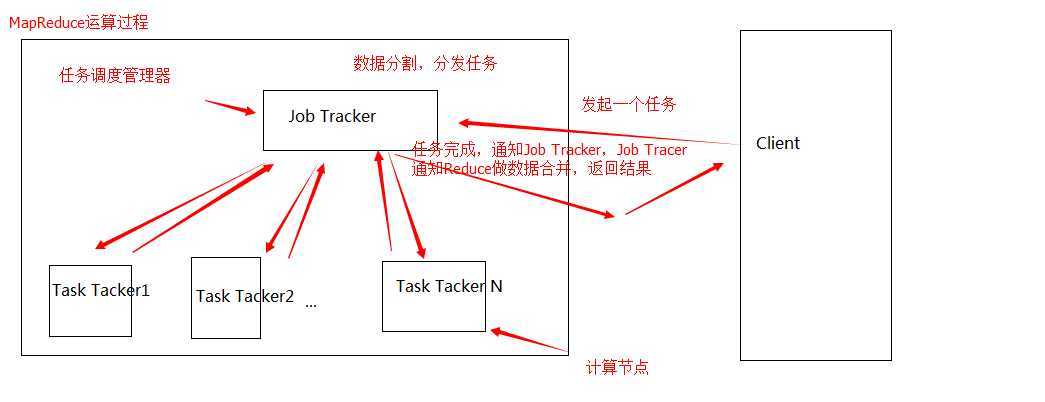
好了,说完了上面,说说主线了,Hive,这次预研的主要对象就是它了。前图已经说明,hive是Hadoop上的数据仓库基础架构,这么绕口的东西怎么说比较形象呢?说白了就是:
1 它不是存储数据的,真正的数据存储在HDFS上
2 它提供一个类SQL的语言,可以对外提供数据存储、查询和分析的接口,总之就是比起直接查Hadoop上的数据,要舒服得多了
如图:

接下来,从三方面来对Hive的数据管理进行分析:
1 元数据存储
Hive将元数据存储在RDBMS中,所以通常你在网上会查到安装hive需要安装Mysql数据库或者其它RDBMS数据库,就是这么回事,对于元数据不太能理解的朋友可以将它理解成数据的基本信息,但是不包含实际数据。
2 数据存储
Hive没有专门的数据存储格式,也没有为数据建立索引,其所有数据都存在HDFS中,由于Hadoop是批处理系统,任务是高延迟的,在任务提交和处理过程中也会消耗一些时间成本,所以即时Hive处理的数据集非常小,在执行过程中也会出现延迟现象,这样,Hive的性能就不能和传统的Oracle相比了 。另外,Hive不提供数据排序和查询cache功能,不提供在线事物处理,换句话说,不支持与用户直接对接,而是适合离线处理。当然也不提供实时的查询和记录级的更新。Hive适合的是处理不变的大规模数据集(例如网络日志)上的批量任务,最大的价值是可扩展性、可延展性、良好的容错率和低约束的数据输入格式。
hive架构体系如图:
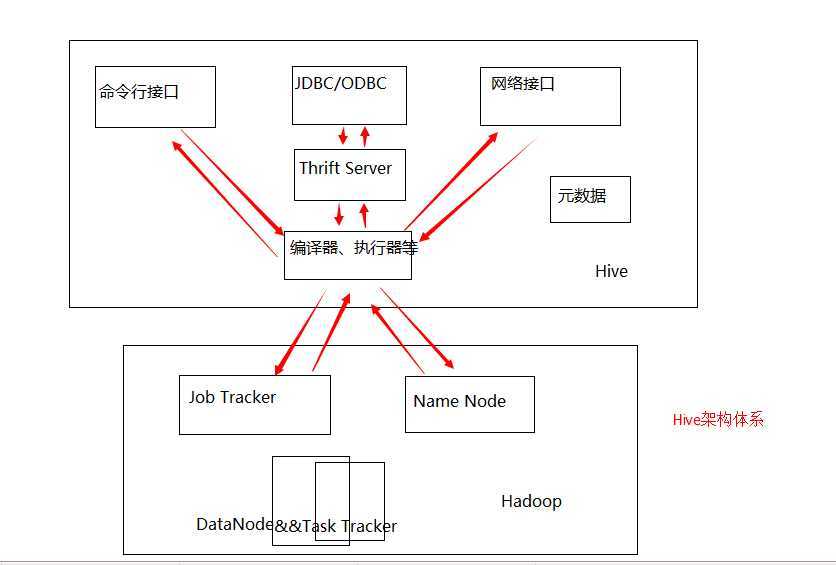
其中Thrift是一个类似与ICE的通讯框架。
介绍完以上,相信大家对于Hadoop和hive所适用的场景已经一目了然了,具体用不用,取决于具体的业务场景吧~
如果有下一篇,将是Hadoop集群搭建和hive的实例介绍。
标签:style blog http color os java strong 文件 数据
原文地址:http://www.cnblogs.com/HouZhiHouJueBlogs/p/3963848.html