标签:基于 images ora 相关 建模 ons 额外 2.4 缩小
来源
Cube:
用空间换时间(类似:BI分析)
预计算把用户需要查询的维度以及他们所对应的考量的值,存储在多维空间里
当用户查询某几个维度的时候,通过这些维度条件去定位到预计算的向量空间,通过再聚合处理,快速返回最终结果给用户。
Kylin的cube不是单一维度的组合,而是所有组合都可以计算。N个维度的完整Cube, 会有2的N次方种组合。
如何计算:逐层算法。它会启动N+1轮MapReduce计算
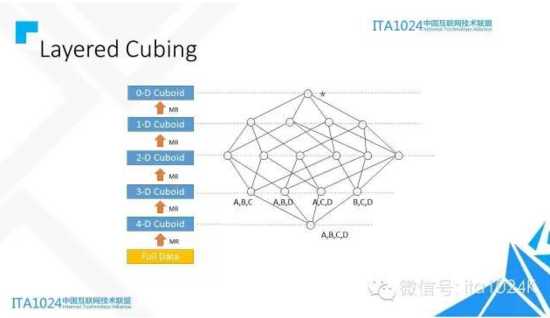
- 第一轮读取原始数据,去掉不相关的列,只保留相关的,同时对维度列进行压缩编码。以此处的四维Cube为例,经过第一轮计算出ABCD组合,我们也称为Base Cuboid;
- 此后的每一轮MapReduce,输入是上一轮的输出,以重用之前计算的结果,去掉要聚合的维度,算出新的Cuboid
- 此往上,直到最后算出所有的Cuboid。
在Storage上是怎么存储的:

- 星形模型会先被拉成一张平表, Dimension的值拼接在一起,后面接着是Metrics。
- 为了标示这是哪几个维度的组合,会在行的开始加上Cuboid ID。最后,Cuboid ID + dimensions会被用作Rowkey,Metrics会作为Value放到Column中 。
查询:
- SQL语句被SQL解析器翻译成一个解释计划,从这个计划可以准确知道用户要查哪些表,它们是怎样join起来,有哪些过滤条件等等。Kylin会用这个计划去匹配寻找合适的Cube。
- 如果有Cube命中,这个计划会发送到存储引擎,翻译成对存储(默认HBase)相应的Scan操作。Groupby和过滤条件的列,用来找到Cuboid,过滤条件会被转换成Scan的开始和结束值, 以缩小Scan的范围; Scan的result,Rowkey会被反向解码成各个dimension的值,Value会被解码成Metrics值 。
架构:
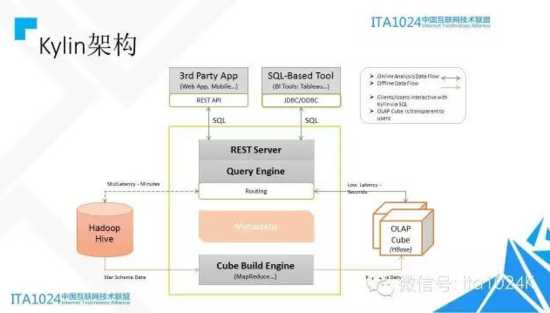
首先要求用户把数据放在Hadoop上,通过Hive管理
用户在Kylin中进行数据建模以后,Kylin会生成一系列的MapReduce任务来计算Cube,算好的Cube最后以K-V的方式存储在HBase中。
分析工具发送标准SQL查询,Kylin将它转换成对HBase的Scan,快速查到结果返回给请求方。
企业级特性:

- Kylin对外暴露的是标准的SQL,支持大多数的SELECT语法,可以把各种工具和系统直接对接进来。这意味着当您使用Kylin的时候,不需要对业务系统做额外的改动。
- Kylin提供了各种接入方式, 如ODBC、JDBC; 如果您的系统不使用这两种方式,还可以使用RESTful API查询。
- Kylin架构天生就非常适合Scale out,当查询量上升,单节点不能满足的时候,只需要相应增加Kylin的节点就可以满足。
- 针对企业对安全的要求,我们有不同力度做安全控制。Kylin有不同用户角色做不同的事情,此外在project和cube层级可以定义ACL帮助在更细力度掌控对cube的使用。
- 企业通常会使用目录服务来管理用户和群组,Kylin支持LDAP认证登录;如果对安全有更高的要求,Kylin还支持了基于SAML的单点登录(SingleSign-On),只要做一些配置就可以完成,不需要额外开发。
- 提供了丰富的RESTful API,非常方便从用各种已有系统,如任务调度,监控等接入Kylin
- Kylin的Web UI做到的事情通过API都可以做到。我们看到网易、美团等在Kylin之上开做了封装,跟他们各自的BI做深度的融合,就是利用了这个特性。
怎么样用Kylin来构建大数据的分析平台?
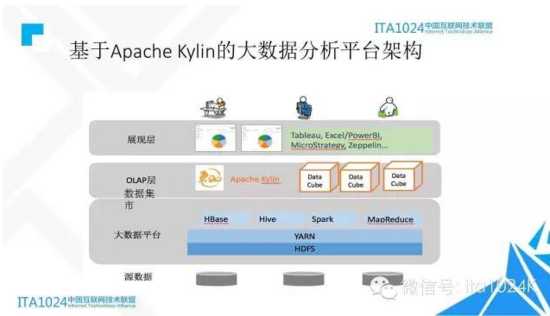
Kylin部署和安装是非常方便的,我们称为非侵入式的安装。如果你已经有一套Hadoop,安装Kylin,只要增加一台机器,下载Kylin安装包运行就可以了,Kylin使用标准Hadoop API跟各种组件通信,不需要对现有的Hadoop安装额外的agent。
架构上就是个分层的结构,最底层是数据,放置在HDFS,其上是Hadoop层,需要有HBase、 Hive, MapReduce等。Kylin运行中Hadoop之上,安装好了之后,业务系统连入Kylin,Kylin把压力分布到Hadoop上做计算和查询。
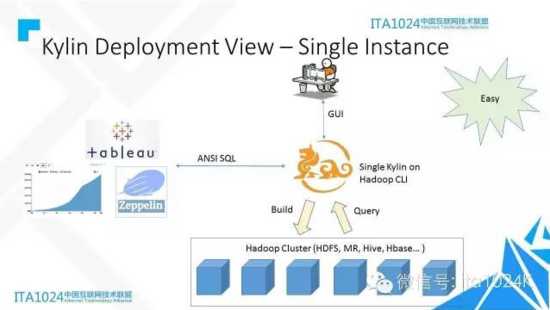
四种典型的部署架构,分别从简单到复杂。
- Single instance的部署 ,通常一两天就可以完成。首先要有Hadoop,版本在2.4或以上。加一台Hadoop客户机,下载Kylin,即可一键启动。 建模人员通过Kylin Web登录,进行建模和cube的创建。业务分析系统或者工具发SQL到Kylin,Kylin查询Cube返回结果。
- 最大特点是简单;缺点也很明显: Kylin是单点,并发请求上来的时候它会成为瓶颈,所以需要Cluster的部署。
Kylin简介
标签:基于 images ora 相关 建模 ons 额外 2.4 缩小
原文地址:http://www.cnblogs.com/panpanwelcome/p/7685967.html