标签:表示 会同 总结 数据集 strong 机器 简单的 学习笔记 产生
一、纲要
纠正较大误差的方法
模型选择问题之目标函数阶数的选择
模型选择问题之正则化参数λ的选择
学习曲线
二、内容详述
1、纠正较大误差的方法
当我们运用训练好了的模型来做预测时,发现会有较大的误差,这时我们有哪些解决方法呢?
(1)获得更多的训练集
(2)减少特征的数量
(3)增加特征的数量
(4)增加多项式特征
(5)减少正则化参数λ
(6)增大正则化参数λ
知道有这些方法,那我们应该选哪一种方法使用呢?当然不能是随机选择啦,下面的部分就会讲解针对不同情况应该选择的方法!
2、模型选择问题之目标阶数的选择
我们先介绍该如何评价你的机器学习算法?我们可以将数据集按7:3分为训练集和测试集,训练集的作用就是用来训练模型,测试集的作用就是来评价机器学习算法的性能。这里我们用Jtrain(θ)来表示训练集误差,用Jtest(θ)来表示测试集误差。训练集误差和测试机误差与代价函数相比就是少了正则项,其他都一样。公式表示如下
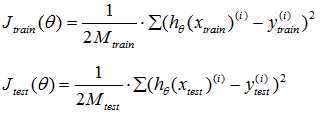
当我们求解线性回归问题时,我们应该怎么选取假设函数呢?假设函数的最高次项又应该怎么选呢?例如

显然多项式次数越高越能完美的拟合训练集中的数据,但是这也会同时带来过拟合的问题,即虽然完美的拟合了训练集的数据,但却在进行预测数据的时候表现的不好。这个问题应该怎么解决?这里的解决方法是利用上面说的将数据集分为训练集和测试集,利用训练集分别训练10个不同的模型(hθ(x))得到10组参数θ(1),θ(2),...,θ(10),然后再代入测试机数据算出测试集误差,从中选择使得测试机误差最小的结束d。这样做完你会发现,如果再用测试集数据对你的算法进行评价,那是没有什么意义的,因为在选择阶数d的时候已经用过测试集数据对假设函数进行拟合了,所以这里我们通常会把数据集分为三部分,训练集:验证集:测试集=6:2:2,利用验证集数据去选择阶数d,之后再用测试集数据对算法进行评价。下面我们先给出误差函数与阶数d的曲线图再作说明。
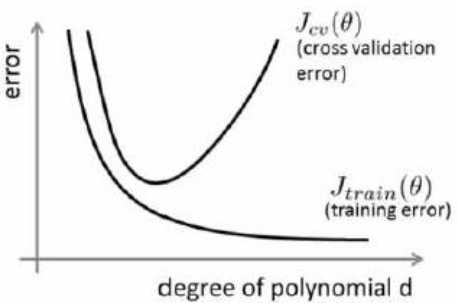
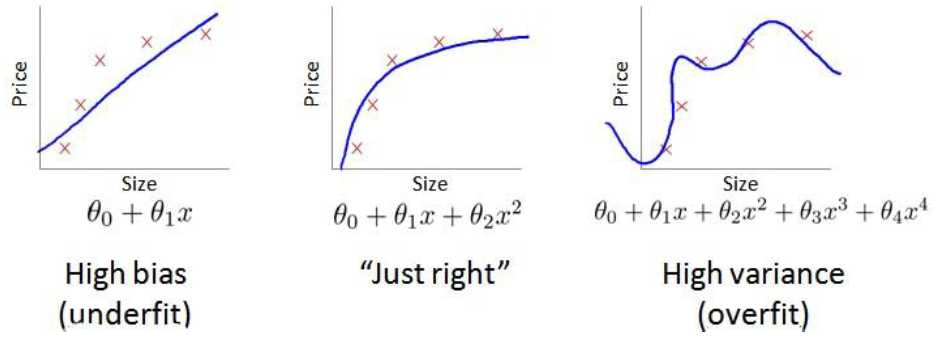
Jcv(θ)表示验证集误差函数,横坐标表示阶数d,我们可以想象的到,当然如果感觉想象的模糊的话,右上图给了简单的例子来帮助理解,当阶数d比较小时,通常就是欠拟合的状态,这个时候训练集误差函数Jtrain(θ)是比较大的,但当d逐渐增大至过拟合状态,这个时候假设函数对训练集的拟合是非常完美的,所以训练集误差函数Jtrain(θ)就随着d的增大而减小。而验证集误差函数Jcv(θ)呢?d比较小时,欠拟合,这个时候假设函数对新数据的预测不是很好,所以验证集误差函数Jcv(θ)比较大,当d增大至过拟合时,我们从之前的学习中知道,过拟合状态的假设函数对新数据预测的效果也不是很好,而只有当阶数d合适的时候,既不是欠拟合也不是过拟合,这时候的假设函数对新数据的预测就表现的比较好了,验证集误差函数Jcv(θ)也就比较小,所以根据这些推理,我们画出了左上图中的曲线。
我们可以根据上图中的曲线来推断假设函数的状态,如果Jcv(θ)与Jtrain(θ)大致相等,我们可以认为这时候假设函数处于欠拟合状态,高偏差(high bias);如果Jcv(θ)>>Jtrain(θ),我们可以认为这时候假设函数处于过拟合状态,高方差(high variance)。
3、模型选择问题之正则化参数λ的选择
当λ比较大时,我们在代价函数最小化的过程中会产生所有的θ1,θ2,...,θn都趋于0,这样的话又变成了欠拟合状态。而λ较小时,正则化产生的效果又不明显,产生的就是过拟合问题,所以我们也可以画出误差函数与λ的曲线图
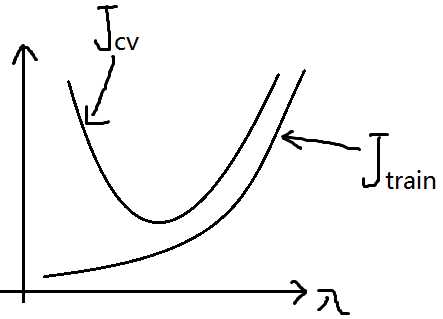
知道了这个,我们怎样选择合适的λ呢?跟上面选择θ时一样,我们可以假设12组λ,并利用训练集训练出模型得到参数θ。然后利用验证集数据将θ和12组λ代入假设函数中,算出验证集误差,根据验证集误差最小选择出合适的λ。
4、学习曲线
我们利用在高偏差和高方差时数据集数量m与误差函数的关系画出曲线
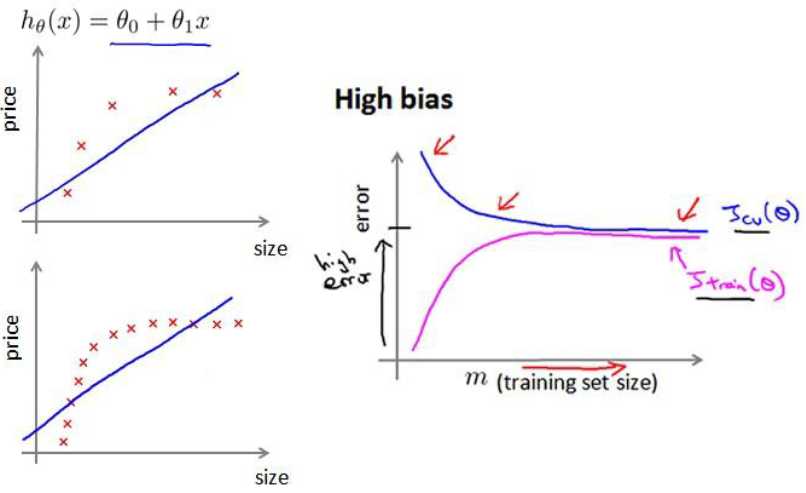
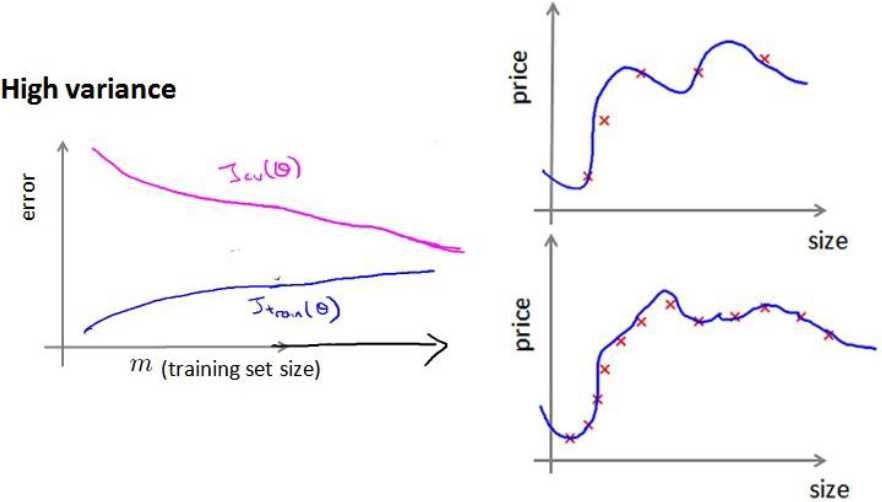
从图中我们可以看出,当处于高偏差时,训练集误差函数Jtrain(θ)和验证集误差函数Jcv(θ)随着m的增大而逐渐趋于平缓,所以增加数据集对高偏差(欠拟合)情况没有改善;当处于高方差时,增加数据集数量可以是的Jcv(θ)持续下降,这时就是有效的。
所以,总结一下:
当处于高偏差(欠拟合)情况下,我们可以采用的方法是:增加特征变量数,或减小λ;
当处于高方差(过拟合)情况下,我们可以采用的方法是:增加数据集,或增大λ,或挑选部分特征变量;
标签:表示 会同 总结 数据集 strong 机器 简单的 学习笔记 产生
原文地址:http://www.cnblogs.com/kl2blog/p/7728237.html