标签:基础 article 对比 connect def ext 防盗链 自定义 highlight
上课第24天,打卡:
努力不必让全世界知道;

1 s16/17爬虫2 2 3 内容回顾: 4 1. Http协议 5 Http协议:GET / http1.1/r/n...../r/r/r/na=1 6 TCP协议:sendall("GET / http1.1/r/n...../r/r/r/na=1") 7 8 2. 请求体 9 GET: GET / http1.1/r/n...../r/r/r/n 10 POST: 11 POST / http1.1/r/n...../r/r/r/na=1&b=2 12 POST / http1.1/r/n...../r/r/r/{"k1":123} 13 14 PS: 依据Content-Type请求头 15 16 3. requests模块 17 - method 18 - url 19 - params 20 - data 21 - json 22 - headers 23 - cookies 24 - proxies 25 4. BeautifulSoup4模块 26 HTML 27 XML 28 29 5. Web微信 30 - 轮训 31 - 长轮训 32 33 34 35 今日内容概要: 36 1. Web微信 37 38 2. 高性能相关 39 40 3. Scrapy 41 42 43 内容详细: 44 1. Web微信 45 46 - 防盗链 47 - headers 48 - cookies 49 50 - 检测请求 51 - url 52 53 - Session中: 54 - qcode 55 - ctime 56 - login_cookie_dict 57 - ticket_dict_cookie 58 - ticket_dict 59 - init_cookie_dict 60 61 - 收发消息 62 63 64 65 2. 高性能相关 66 67 基本原理: 68 IO多路复用:select,用于检测socket对象是否发生变化(是否连接成功,是否有数据到来) 69 Socket:socket客户端 70 71 import socket 72 import select 73 74 class Request(object): 75 def __init__(self,sock,func,url): 76 self.sock = sock 77 self.func = func 78 self.url = url 79 80 def fileno(self): 81 return self.sock.fileno() 82 83 def async_request(url_list): 84 85 input_list = [] 86 conn_list = [] 87 88 for url in url_list: 89 client = socket.socket() 90 client.setblocking(False) 91 # 创建连接,不阻塞 92 try: 93 client.connect((url[0],80,)) # 100个向百度发送的请求 94 except BlockingIOError as e: 95 pass 96 97 obj = Request(client,url[1],url[0]) 98 99 input_list.append(obj) 100 conn_list.append(obj) 101 102 while True: 103 # 监听socket是否已经发生变化 [request_obj,request_obj....request_obj] 104 # 如果有请求连接成功:wlist = [request_obj,request_obj] 105 # 如果有响应的数据: rlist = [request_obj,request_obj....client100] 106 rlist,wlist,elist = select.select(input_list,conn_list,[],0.05) 107 for request_obj in wlist: 108 # print(‘连接成功‘) 109 # # # # 发送Http请求 110 # print(‘发送请求‘) 111 request_obj.sock.sendall("GET / HTTP/1.0\r\nhost:{0}\r\n\r\n".format(request_obj.url).encode(‘utf-8‘)) 112 conn_list.remove(request_obj) 113 114 for request_obj in rlist: 115 data = request_obj.sock.recv(8096) 116 request_obj.func(data) 117 request_obj.sock.close() 118 input_list.remove(request_obj) 119 120 if not input_list: 121 break 122 123 使用一个线程完成并发操作,如何并发? 124 当第一个任务到来时,先发送连接请求,此时会发生IO等待,但是我不等待,我继续发送第二个任务的连接请求.... 125 126 IO多路复用监听socket变化 127 先连接成功: 128 发送请求信息: GET / http/1.0\r\nhost.... 129 遇到IO等待,不等待,继续检测是否有人连接成功: 130 发送请求信息: GET / http/1.0\r\nhost.... 131 遇到IO等待,不等待,继续检测是否有人连接成功: 132 发送请求信息: GET / http/1.0\r\nhost.... 133 134 有结果返回: 135 读取返回内容,执行回调函数 136 读取返回内容,执行回调函数 137 读取返回内容,执行回调函数 138 读取返回内容,执行回调函数 139 读取返回内容,执行回调函数 140 读取返回内容,执行回调函数 141 读取返回内容,执行回调函数 142 143 144 145 问题:什么是协程? 146 单纯的执行一端代码后,调到另外一端代码执行,再继续跳... 147 148 异步IO: 149 - 【基于协程】可以用 协程+非阻塞socket+select实现,gevent 150 - 【基于事件循环】完全通用socket+select实现,Twsited 151 152 1. 如何提高爬虫并发? 153 利用异步IO模块,如:asyncio,twisted,gevent 154 本质: 155 - 【基于协程】可以用 协程+非阻塞socket+select实现,gevent 156 - 【基于事件循环】完全通用socket+select实现,Twsited,tornado 157 158 2. 异步非阻塞 159 异步:回调 select 160 非阻塞:不等待 setblocking(False) 161 162 3. 什么是协程? 163 pip3 install gevent 164 165 from greenlet import greenlet 166 167 def test1(): 168 print(12) 169 gr2.switch() 170 print(34) 171 gr2.switch() 172 173 174 def test2(): 175 print(56) 176 gr1.switch() 177 print(78) 178 179 gr1 = greenlet(test1) 180 gr2 = greenlet(test2) 181 gr1.switch() 182 183 184 185 3. 爬虫 186 - request+bs4+twisted或gevent或asyncio 187 - scrapy框架 188 - twisted 189 - 自己html解析 190 - 限速 191 - 去重 192 - 递归,找4层 193 - 代理 194 - https 195 - 中间件 196 .... 197 - 安装scrapy 198 依赖Twisted 199 200 - 开始写爬虫 201 执行命令: 202 scrapy startproject sp1 203 204 sp1 205 - sp1 206 - spiders 爬虫 207 - xx.py 208 - chouti.py 209 - middlewares 中间件 210 - pipelines 持久化 211 - items 规则化 212 - settings 配置 213 - scrapy.cfg 214 215 cd sp1 216 scrapy genspider xx xx.com 217 scrapy genspider chouti chouti.com 218 219 - scrapy crawl chouti 220 name 221 allow_domains 222 start_urls 223 224 parse(self,response) 225 226 227 yield Item 228 229 yield Request(url,callback) 230 231 232 本周任务: 233 1. Web微信 234 235 2. 高性能示例保存 236 237 3. 238 - 煎蛋 239 - 拉钩 240 - 知乎 241 - 抽屉 242
day24
Web微信
高性能
scrapy
requests.post(data=xxx) -> Form Data
requests.post(json=xxx) -> Request Payload
HttpResponse() 参数可以是字符串也可以是字节
response.text 字符串
response.content 字节
# 获取最近联系人然后进行初始化
# 获取头像
# 拿联系人列表
response = requests.get(url,cookies=xxx)
response.encoding = ‘utf-8‘
print(json.loads(response.text))
Web微信总结
- 头像防盗链
- headers
- cookies
- 检测请求:
- tip | pass_ticket | ...
- redirect_url和真实请求的url是否一致
- session 保存关键点的cookies和关键变量值
- qrcode 和 ctime
- login_cookie_dict
- ticket_dict_cookie
- ticket_dict
- init_cookie_dict
- init_dict
- all_cookies = {}
- all_cookies.update(...)
json序列化的时候是可以加参数的:
data = {
‘name‘:‘alex‘,
‘msg‘:‘中文asa‘
}
import json
print(json.dumps(data))
按Unicode显示
print(json.dumps(data,ensure_ascii=False))
按中文显示
json.dumps() 之后是字符串
requests.post() 默认是按照 latin-1 编码,不支持中文
所以改成直接发bytes:
requests.post(data=json.dumps(data,ensure_ascii=False).encode(‘utf-8‘))
发送消息需带上cookies
发送消息
检测是否有新消息到来
接收消息
#########################
高性能相关
100张图片,下载
使用一个线程完成并发操作
是配合IO多路复用完成的
爬虫:
- 简单的爬虫
- requests+bs4+twsited+asyncio
- scrapy框架
- 下载页面:twsited
- 解析页面:自己的HTML解析
- 可限速
- 去重
- 递归 一层一层的爬,成倍速的增长,还可以限制层数
- 代理
- https
- 中间件
...
scrapy
- scrapy startproject sp1
- cd sp1
- scrapy genspider baidu baidu.com
- scrapy genspider chouti chouti.com
- scrapy crawl chouti --nolog
- name
- allow_dimains
- start_urls
- parse(self,response)
- yield Item 持久化
- yield Request(url,callback) 把url放到调度器队列里
本周作业:
1.Web微信
自己去写,写完跟老师的对比
2.高性能总结文档(源码示例+文字理解)
3.任意找一个网站,用Scrapy去爬
- 煎蛋
- 拉钩
- 知乎
- 抽屉
- ...
不遵循爬虫规范:
ROBOTSTXT_OBEY = False
可能会失败:没有带请求头
起始url如何携带指定请求头?
自定义start_requests(self)
获取最近联系人列表并初始化:
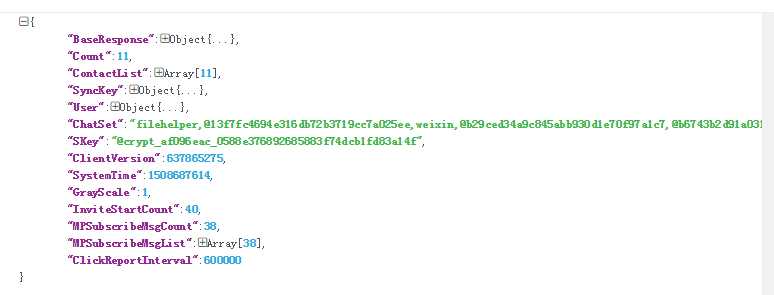
获取联系人列表:
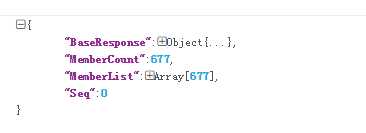
代码实现见另一片博客:Web微信
参考:http://www.cnblogs.com/wupeiqi/articles/6229292.html
代码示例见另一篇那博客:Python高性能编程
标签:基础 article 对比 connect def ext 防盗链 自定义 highlight
原文地址:http://www.cnblogs.com/standby/p/7712565.html
