标签:col 技术 是什么 完整 计算方法 方法 结果 表示 我不知道
翻译自:https://stackoverflow.com/questions/34240703/whats-the-difference-between-softmax-and-softmax-cross-entropy-with-logits
在Tensorflow官方文档中,他们使用一个关键词,称为logits。这个logits是什么?比如说在API文档中有很多方法(methods),经常像下面这么写:
tf.nn.softmax(logits, name=None)
另外一个问题是,有2个方法我不知道该怎么区分,它们是:
tf.nn.softmax(logits, name=None)
tf.nn.softmax_cross_entropy_with_logits(logits, labels, name=None)
它们之间的区别是什么?
假设你有2个tensors,其中y_hat包含每个类预测的得分(比如说,从y = W*x +b计算得到),y_true包含one-hot编码后的正确的label。
y_hat = ... # Predicted label, e.g. y = tf.matmul(X, W) + b y_true = ... # True label, one-hot encoded
如果你将y_hat的得分解释为未归一化的log概率,那么它们就是logits。
另外,总的交叉熵损失可以用如下方式计算得到:
y_hat_softmax = tf.nn.softmax(y_hat)
total_loss = tf.reduce_mean(-tf.reduce_sum(y_true * tf.log(y_hat_softmax), [1]))
从本质上来说,与用softmax_cross_entropy_with_logits()函数计算得到的总的交叉熵损失是一样的,计算方法为:
total_loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(y_hat, y_true))
举个例子,我们创建一个2x3大小的y_hat,其中行对应着训练样本,列对应类别。因此,这里有2个训练样本和3个类别。
import tensorflow as tf import numpy as np sess = tf.Session() # Create example y_hat. y_hat = tf.convert_to_tensor(np.array([[0.5, 1.5, 0.1],[2.2, 1.3, 1.7]])) sess.run(y_hat) # array([[ 0.5, 1.5, 0.1], # [ 2.2, 1.3, 1.7]])
注意到这些值并没有归一化(每一行加起来并不等于1)。为了归一化这些数,我们可以使用softmax函数,这个函数的输入就是未归一化的log概率(也称为logits),输出是归一化的线性概率。
y_hat_softmax = tf.nn.softmax(y_hat) sess.run(y_hat_softmax) # array([[ 0.227863 , 0.61939586, 0.15274114], # [ 0.49674623, 0.20196195, 0.30129182]])
完全理解softmax输出的内容是很重要的。下面我将展示一个表格来更加清楚地解释上面的输出。从表格中可以看出来,训练样本实例1属于类别2的概率是0.619,每个训练样本实例的类概率被归一化,所有每一行的和是1.0。
Pr(Class 1) Pr(Class 2) Pr(Class 3)
--------------------------------------
Training instance 1 | 0.227863 | 0.61939586 | 0.15274114
Training instance 2 | 0.49674623 | 0.20196195 | 0.30129182
现在我们有了每个训练样本在每个类上的概率,我们可以对每一行使用argmax()来产生一个最终的分类结果。从上面的表格上来看,我们可以判断出训练样本实例1属于类别2,训练样本实例2属于类别1。
那么,这些分类正确么?我们需要根据训练样本正确的标签来衡量。你需要一个one-hot编码的y_true数组,其中每一行表示训练样本实例,每一列表示类别。下面我将创建一个例子,y_true为one-hot编码的数组,其中对于训练样本1正确的标签是类别2,对于训练样本2正确的标签是类别3。
y_true = tf.convert_to_tensor(np.array([[0.0, 1.0, 0.0],[0.0, 0.0, 1.0]])) sess.run(y_true) # array([[ 0., 1., 0.], # [ 0., 0., 1.]])
y_hat_softmax的概率分布接近y_true的概率分布么?我们可以使用交叉熵损失( cross-entropy loss)来衡量错误程度。
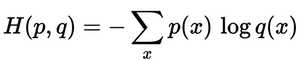
根据下面的式子,我们可以计算出每一行的交叉熵损失。从下面的结果中可以看出训练样本1的损失为0.479,训练样本2的损失比较高,是1.200。这个结果是有道理的,因为y_hat_softmax显示训练样本1的最高概率是类别2,与正确标签y_true匹配,而训练样本2的最高概率预测为类别1,与实际标签(类别3)不匹配。
loss_per_instance_1 = -tf.reduce_sum(y_true * tf.log(y_hat_softmax), reduction_indices=[1]) sess.run(loss_per_instance_1) # array([ 0.4790107 , 1.19967598])
我们想要的是训练集上的所有的loss,因此我们需要将每个训练样本的loss加起来,如下:
total_loss_1 = tf.reduce_mean(-tf.reduce_sum(y_true * tf.log(y_hat_softmax), reduction_indices=[1])) sess.run(total_loss_1) # 0.83934333897877944
使用softmax_cross_entropy_with_logits()
我们也可以使用tf.nn.softmax_cross_entropy_with_logits()函数来计算整个交叉熵损失,代码如下:
loss_per_instance_2 = tf.nn.softmax_cross_entropy_with_logits(y_hat, y_true) sess.run(loss_per_instance_2) # array([ 0.4790107 , 1.19967598]) total_loss_2 = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(y_hat, y_true)) sess.run(total_loss_2) # 0.83934333897877922
注意到,total_loss_1和total_loss_2计算得到的结果是基本一样的(有一点点小的差别)。然而,还是建议使用第二种方法,原因是1)代码量更少,2)方法二的内部考虑到了一些边界情况,不容易产生错误。
[翻译] softmax和softmax_cross_entropy_with_logits的区别
标签:col 技术 是什么 完整 计算方法 方法 结果 表示 我不知道
原文地址:http://www.cnblogs.com/hejunlin1992/p/7783902.html