标签:ons images nal scribe php arm rcu state 随机
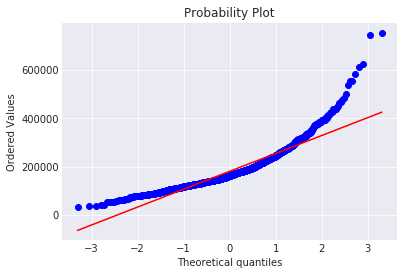
一. QQ图
fig = plt.figure() res = stats.probplot(train[‘SalePrice‘], plot=plt) plt.show()
scipy.stats 用法
# -*- coding: utf-8 -*-
from scipy import stats
from numpy import random
# Distributions
# 常用分布可参考本文档结尾处
# 分布可以使用的方法见下列清单
data=random.normal(size=1000)
stats.norm.rvs(loc=0,scale=1,size=10,random_state=None) # 生成随机数
stats.norm.pdf(-1.96,loc=0,scale=1) # 密度分布函数,画密度分布图时使用
stats.norm.cdf(-1.96,loc=0,scale=1) # 累计分布函数,-1.96对应2.5%
stats.norm.sf(-1.96,loc=0,scale=1) # 残存函数(=1-cdf),-1.96对应97.5%
stats.norm.ppf(0.025,loc=0,scale=1) # 累计分布函数反过来
stats.norm.isf(0.975,loc=0,scale=1) # 残存函数反过来
stats.norm.interval(0.95,loc=0,scale=1) # 置信度为95%的置信区间
stats.norm.moment(n=2,loc=0,scale=1) # n阶非中心距,n=2时是方差
stats.norm.median(loc=0,scale=1) # Median of the distribution.
stats.norm.mean(loc=0,scale=1) # Mean of the distribution.
stats.norm.var(loc=0,scale=1) # Variance of the distribution.
stats.norm.std(loc=0,scale=1) # Standard deviation of the distribution.
stats.norm.fit(data) # fit 估计潜在分布的参数
# Statistical functions
stats.describe([1,2,3]) # 返回多个统计量
stats.gmean([1,2,4]) # 几何平均数 n-th root of (x1 * x2 * ... * xn)
stats.hmean([2,2,2]) # 调和平均数 n / (1/x1 + 1/x2 + ... + 1/xn)
stats.trim_mean([1,2,3,5],0.25) # 砍头去尾均值,按比例砍
stats.sem(data) # Calculates the standard error of the mean
stats.mode([1,1,2]) # 众数
stats.skew(data) # 偏度
stats.kurtosis(data) # 峰度
stats.moment(data,moment=3) # n阶中心矩,3阶就是偏度,4阶就是峰度
stats.skewtest(data) # 检验偏度是否符合正态分布的偏度
stats.kurtosistest(data) # 检验峰度是否符合正态分布的峰度
stats.normaltest(data) # 检验是否符合正态分布
stats.variation([1,2,3]) # 变异系数(=std/mean*100%)
stats.find_repeats([1,1,2,2,3]) # 重复值查找
stats.itemfreq([1,1,2,2,3]) # 频次统计
stats.percentileofscore([1,2,3,4,5],2) # 返回数值的分位数
stats.scoreatpercentile([1,2,3,4,5],80,interpolation_method="lower") # 返回分位数对应的数值
stats.bayes_mvs(data) # 返回均值/方差/标准差的贝叶斯置信区间
stats.iqr([1,2,3,4,5],rng=(25,75)) # 计算 IQR
stats.zscore(data) # 计算 zscore
stats.f_oneway(data,data+data,data+data+data) # 单因素方差分析,参数是(样本组1,样本组2,样本组3)
stats.pearsonr(data,data+data) # 皮尔森相关系数
stats.spearmanr(data,data+data) # 斯皮尔曼秩相关系数
stats.kendalltau(data,data+data) # 肯德尔相关系数
stats.pointbiserialr([1,1,1,0,0,0],[1,2,3,4,5,6]) # 点二系列相关,第一个变量需要是二分类变量
stats.linregress(data,data+data) # 线性最小二乘回归
stats.ttest_1samp(data,popmean=0) # 单样本 t-检验: 检验总体平均数的值
stats.ttest_ind(data,data+data) # 双样本 t-检验: 检验不同总体的差异
stats.ttest_rel(data,data+data) # 配对样本 t-检验
stats.ttest_ind_from_stats(mean1=0,std1=1,nobs1=100,mean2=10,std2=1,nobs2=150,equal_var=True) # 根据统计量做 t-检验
stats.wilcoxon(data,data+data) # 一种非参数的配对样本检验。t-检验假定高斯误差。可以使用威尔科克森符号秩检验, 放松了这个假设
stats.kstest(data,‘norm‘) # Kolmogorov–Smirnov检验: 检验单一样本是否服从某一预先假设的特定分布
stats.ks_2samp(data,data+data) # 检测两样本分布是否相同
stats.ranksums(data,data+data) # Wilcoxon rank-sum statistic 检测两样本分布是否相同
stats.chisquare(data,data) # 卡方检验,第一个参数是样本分布,第二个参数是期望分布
# Circular statistical functions
# 适用于环形数据,如时间(60分钟一圈),角度(360度一圈)
# 例如 0度 与 360度 的均值应该是 0度
stats.circmean([0,360],high=0,low=360) # 均值
stats.circvar([0,360],high=0,low=360) # 方差
stats.circstd([0,360],high=0,low=360) # 标准差
# Contingency table functions
# 列联表
stats.chi2_contingency([[10,10,20],[20,20,20]],lambda_="log-likelihood") # 卡方检验,n*m的列联表,每个格子样本数要大于5,lambda_默认皮尔森
stats.fisher_exact([[8,2],[1,5]],alternative="two-sided") # 费舍尔精确检验,2*2的列联表,alternative:two-sided,less,greater
stats.contingency.expected_freq([[10,10,20],[20,20,20]]) # 返回列联表的期望频次(各变量独立时的预期频次)
import numpy as np; stats.contingency.margins(np.array([[10,10,20],[20,20,20]]))# 返回列联表的行列和
# Plot-tests
# 图检验:probplot与Q-Q图的差异:P-P图是用分布的累计比,而Q-Q图用的是分布的分位数来做检验
import matplotlib.pyplot as plt
data=random.normal(loc=0,scale=1,size=500)
stats.probplot(data,dist=stats.norm,sparams=(0,1),plot=plt) # P-P图(probability plot),参数sparams传的是均值与标准差
stats.boxcox_normplot(abs(data),-3,3,plot=plt) # 不知干啥用,Compute parameters for a Box-Cox normality plot
stats.ppcc_plot(data,-3,3,dist=stats.norm,plot=plt) # 不知干啥用,Calculate and optionally plot probability plot correlation coefficient.
stats.ppcc_max(data,dist=stats.norm) # 不知干啥用,返回 PPCC 取最大时对应的位置
# Univariate and multivariate kernel density estimation
# 核密度估计用于估计未知的密度函数,属於非参数检验方法之一
stats.gaussian_kde([data,data+random.normal(size=500)]) # 不知干啥用,Representation of a kernel-density estimate using Gaussian kernels.
""" ---------------------------------------------------------------------------------------------------------
所有分布都是 rv_continuous(连续型分布) 与 rv_discrete(离散型分布) 的实例
rv_continuous([momtype, a, b, xtol, ...]) A generic continuous random variable class meant for subclassing.
rv_discrete([a, b, name, badvalue, ...]) A generic discrete random variable class meant for subclassing.
rv_histogram(histogram, *args, **kwargs) Generates a distribution given by a histogram.
Continuous distributions 连续型分布
alpha An alpha continuous random variable.
beta A beta continuous random variable.
chi2 A chi-squared continuous random variable.
f An F continuous random variable.
gamma A gamma continuous random variable.
lognorm A lognormal continuous random variable.
ncx2 A non-central chi-squared continuous random variable.
ncf A non-central F distribution continuous random variable.
nct A non-central Student’s T continuous random variable.
norm A normal continuous random variable.
pareto A Pareto continuous random variable.
t A Student’s T continuous random variable.
uniform A uniform continuous random variable.
wald A Wald continuous random variable.
……
Multivariate distributions 多元分布
multivariate_normal A multivariate normal random variable.
matrix_normal A matrix normal random variable.
multinomial A multinomial random variable.
random_correlation A random correlation matrix.
……
Discrete distributions 离散型分布
binom A binomial discrete random variable.
hypergeom A hypergeometric discrete random variable.
nbinom A negative binomial discrete random variable.
poisson A Poisson discrete random variable.
randint A uniform discrete random variable.
标签:ons images nal scribe php arm rcu state 随机
原文地址:http://www.cnblogs.com/king-lps/p/7840268.html