一:概述
当我们设计一个系统时,需要考虑到系统的运行一段时间后,表里数据量大约有多少,如果在初期,就能估算到某几张表数据量非常庞大时(比如聊天消息表),就要把表创建好,这篇文章从创建表,增加数据,以及字段扩展,这几个方面来给出建议。
二:创建表
假如现在我们需要创建IM项目中的聊天消息表,这个表数据量大,读操作远超过写操作,我们都知道,mysql常用的数据库引擎主要有innodb,myisam,这两个数据库引擎主要区别是,innodb支持事务,支持外键,锁是行级锁(行级锁只是针对主键,非主键也会锁全表),myisam不支持事务,不支持外键约束,锁是表级锁,从性能角度分析,myisam要比innodb更好一些,所以在数据库引擎上,我选择myisam,另外在消息发送用户id和消息接收用户id上加索引。
1:数据类型的选择
由于考虑到数据量非常大,所以在字段数据类型选择时,能用数字的就不要用字符串,当然时间类型也要用bigint来代替,不建议使用text类型,在varchar字段上建议创建默认值,比如:default ‘‘ ,因为where 使用 is null是全表扫描,数字类型也需要加默认值,比如 num int default 0,如果不加默认值,并且执行insert 语句,也没有对该字段赋值,哪么执行update xxx set num = num +1 时,你会发现sql不报错,然后num的值却没更新到,另外需要在作为条件查询的字段加索引.
2:表分区
在大数据面前,除了数据类型和性能有很大关系之外,我们还可以使用表分区,分表和分库目前还用不上,表分区概念
2.1 表分区概念
range分区:基于属于一个给定连续区间的列值,把多行分配给分区。
list分区:和range分区类似,区别是list分区是基于列值匹配一个离散值集合中的某个值来进行选择。
hash分区:基于用户定义的表达式的返回值来进行选择的分区,该表达式使用将要插入到表中的这些行的列值进行计算。
KEY分区:类似于按HASH分区,区别在于KEY分区只支持计算一列或多列,且MySQL服务器提供其自身的哈希函数。必须有一列或多列包含>整数值。
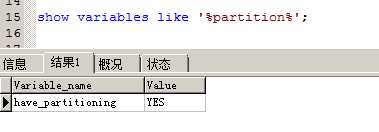
可以使用SHOW VARIABLES LIKE ‘%partition%‘;来确定mysql支持的分区类型.
现在我使用range分区,分区字段是pk,完整sql语句如下

CREATE TABLE chatmsg( cid bigint primary key, cMsgSendUserId bigint, cMsgReceiverUserId bigint, cTime bigint, cContent varchar(2000) not null default ‘‘, cExt varchar(5000) ) ENGINE=MYISAM DEFAULT CHARSET=utf8 COLLATE=utf8_bin PARTITION BY RANGE (cid) ( PARTITION p0 VALUES LESS THAN (1000000), PARTITION p1 VALUES LESS THAN (5000000), PARTITION p2 VALUES LESS THAN (1000000), PARTITION p3 VALUES LESS THAN MAXVALUE ) ; create index senduserid_index on chatmsg(cMsgSendUserId); create index receiverid_index on chatmsg(cMsgReceiverUserId); create index ctime_index on chatmsg(ctime);
三:添加聊天记录。
从建表语句中看到,我们并没有使用外键,所以就需要手动检查外键约束的完整性。
select count(1) from user where uid = 消息发送者id union all select count(1) from user where uid = 消息接收者id
当上面的语句返回结果等于2时,才能执行添加语句。优化查询语句,可以参考我的这一篇文章:百万数据量优化方案
四:扩展字段
假如现在表已经产生了5千万条数据,产品经理过来说,小王,聊天记录需要加一个已读或未读的状态,如果此时在正式使用环境去alter tableadd column,可以想像这个操作有多耗时,有可能数据库直接崩溃都说不定,数据量大了,进行alter tableadd column操作数据库真崩溃过,不是危言耸听,还记得在建表的时候,我们创建了一个cExt字段,这个字段我们记录一个json 字符串,其实正确做法还要加一个版本号,这里我就没有加版本号。表里面的数据如下:
select cid,cTime,cContent,cext from chatmsg where cMsgSendUserId = 100 and cMsgReceiverUserId = 200 union ALL select cid,cTime,cContent,cext from chatmsg where cMsgSendUserId = 200 and cMsgReceiverUserId = 100
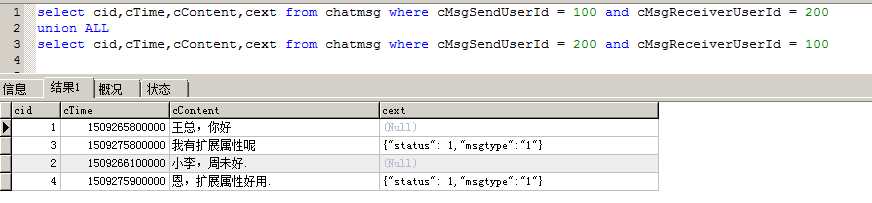
这个方法能解决大部分扩展字段,查询出cext后,然后把该值转换为对像就可以。如果新增的字段,需要出现在where中,就需要根据实际情况进行分析了。
cext扩展字段优点:
(1)可以随时动态扩展属性
(2)新旧两种数据可以同时存在
(3)迁移数据方便,写个小程序将旧版本ext的改为新版本的ext,并修改version
cext扩展字段不足:
(1)cext里的字段无法建立索引
(2)cext里的key值有大量冗余,建议key短一些
五:其它
比如项目初期,产品经理说,小王,我选择任意两个用户,查询这两个人的聊天记录,需要返回这两个用户的昵称,产品经理选择两个用户,我们得到了这两个用户的id,如果直接chat表join user表,性能同样不好,这种情况我们可以考虑使用空间换时间,比如在聊天表中直接创建接收者和发送者的昵称。这个方法表达的意思是,大数据表尽量不要join,性能是不好的,要用其它办法来解决这个问题。当然在正式项目中,具体情况还需要具体分析。