标签:surface cond 分析 file 过拟合 样本 surf 预测 输出
Decision Trees (DT)是用于分类和回归的非参数监督学习方法。 目标是创建一个模型,通过学习从数据特征推断出的简单决策规则来预测目标变量的值。
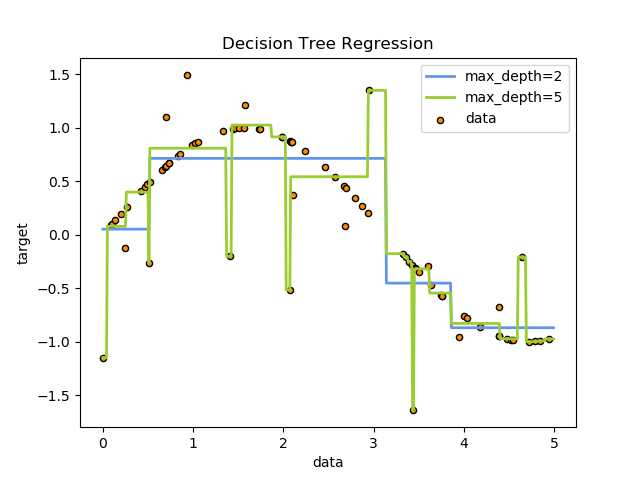
例如,在下面的例子中,决策树从数据中学习用一组if-then-else决策规则逼近正弦曲线。 树越深,决策规则越复杂,模型也越复杂。
决策树的优点:
决策树的缺点:
DecisionTreeClassifier是一个能够对数据集进行多类分类的类。
与其他分类器一样,DecisionTreeClassifier采用两个数组作为输入:保存训练样本的大小为[n_samples,n_features]的稀疏或密集数组X,以及保存类标签的整数值数组Y [n_samples] 训练样本:
>>> from sklearn import tree >>> X = [[0, 0], [1, 1]] >>> Y = [0, 1] >>> clf = tree.DecisionTreeClassifier() >>> clf = clf.fit(X, Y)
经过拟合后,模型可以用来预测样本的类别:
>>> clf.predict([[2., 2.]])
array([1])
或者,可以预测每个类的概率,这是叶子节点中同一类的训练样本的比值:
>>> clf.predict_proba([[2., 2.]])
array([[ 0., 1.]])
DecisionTreeClassifier具有二进制(其中标签是[-1,1])分类和多类(其中标签是[0,...,K-1])分类的能力。
使用Iris数据集,我们可以构建一棵树,如下所示:
>>> from sklearn.datasets import load_iris >>> from sklearn import tree >>> iris = load_iris() >>> clf = tree.DecisionTreeClassifier() >>> clf = clf.fit(iris.data, iris.target)
一旦训练完成,我们可以使用export_graphviz导出器以Graphviz格式导出树。 如果您使用conda软件包管理器,则可以使用graphviz二进制文件和python软件包进行安装
conda install python-graphviz
或者,可以从graphviz项目主页下载graphviz的二进制文件,并使用pip安装graphviz从pypi安装Python包装程序。
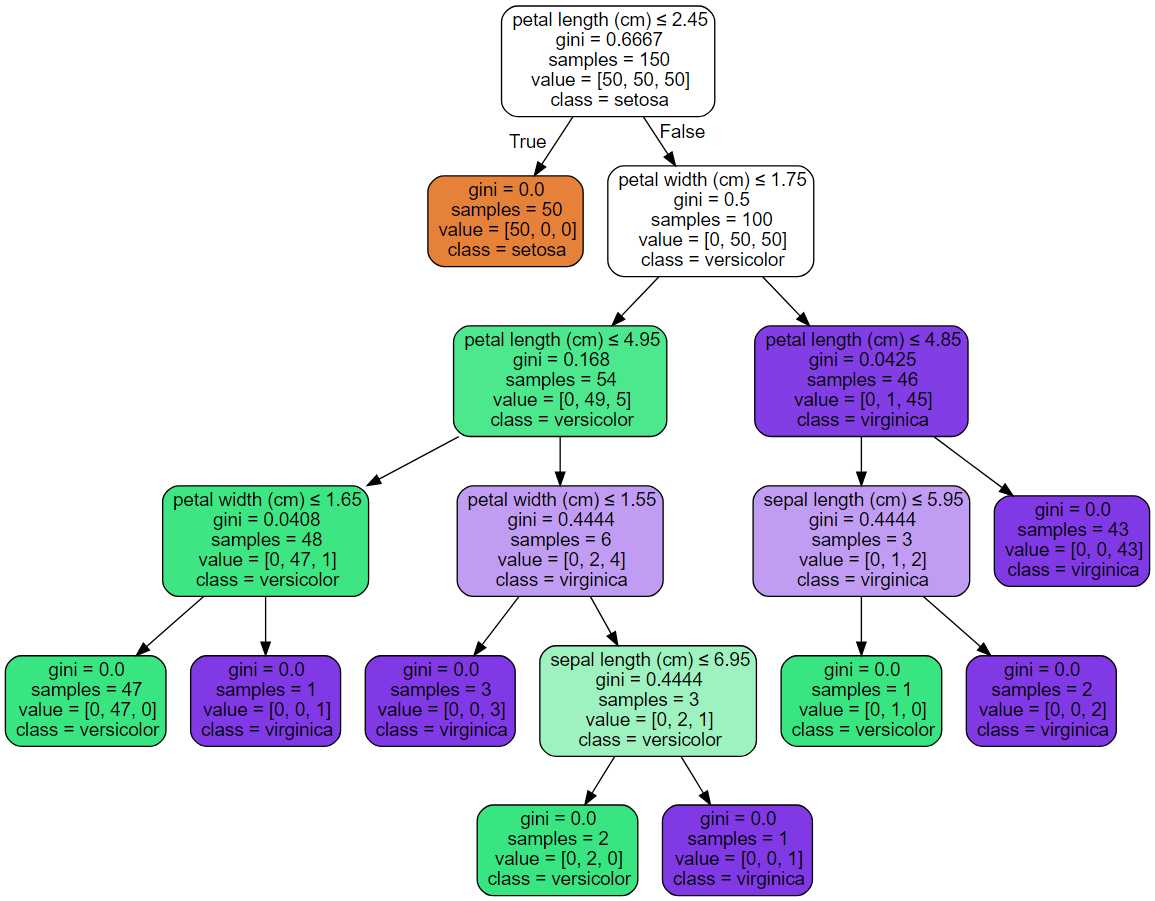
下面是在整个Iris数据集上训练的上述树的graphviz输出示例; 结果保存在一个输出文件iris.pdf中:
>>> import graphviz >>> dot_data = tree.export_graphviz(clf, out_file=None) >>> graph = graphviz.Source(dot_data) >>> graph.render("iris")
export_graphviz导出器还支持各种美观的选项,包括按类别(或回归值)着色节点,并根据需要使用显式变量和类名称。 Jupyter笔记本也自动内联这些图。
>>> dot_data = tree.export_graphviz(clf, out_file=None, feature_names=iris.feature_names, class_names=iris.target_names, filled=True, rounded=True, special_characters=True) >>> graph = graphviz.Source(dot_data) >>> graph
经过拟合后,模型可以用来预测样本的类别:
>>> clf.predict(iris.data[:1, :])
array([0])
或者,可以预测每个类的概率,这是叶子节点中同一类的训练样本的比值:
>>> clf.predict_proba([[2., 2.]])
array([[ 0., 1.]])
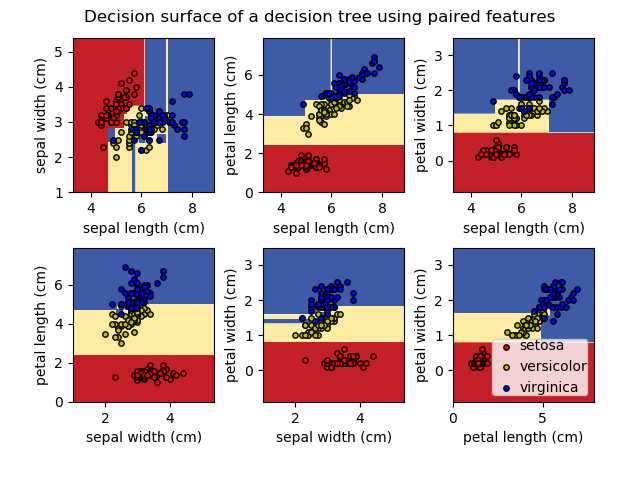
未完待续。。。
详见:http://scikit-learn.org/stable/modules/tree.html
标签:surface cond 分析 file 过拟合 样本 surf 预测 输出
原文地址:http://www.cnblogs.com/skykill/p/7900989.html