1.时间复杂度是什么?
有人说,这还不简单,不就是在给定输入规模时,求所执行的基本操作数量吗?就是次数如下:
int n=10; int count=0; for(int i=0;i<n;i++){//循环次数 for(int j=0;j<n;j++){//执行深度 count++; } }
//count=100
看到这个,时间复杂度无疑是O(n^2),再看看下面的
int n=10; int count=0; for(int i=0;i<n;i++){ for(int j=0;j<i;j++){ count++; } }
//count=45
看到这个,时间复杂度也是O(n^2),这里要出来一个概念,次数和时间复杂度的区别:
第一个程序运行的次数是100(n*n=n^2),第二个程序运行的次数是45(0+1+2+3+4+...........+n-1=n*(n-1)/2),时间复杂度一样的原因是:当n趋于无穷大时可忽略常数,-1,/2可忽略。但是时间复杂度是在次数的基础上计算出来的。而次数就是循环次数*执行深度。
2.什么是大O?
比如我说一个变量x,并且有x在[a,b]这个区间,就表示了上界是a下界是b,对于变量x的取值范围来说,最大不超过b,最小不小于a。在算法中,上界就是对于一种资源的限制最大不大于的值,下界就是对于这种资源的限制最小不小于的值。这里的资源可以是时间、空间、带宽……
所以当n趋于无穷时,O(2n^2)=O(n^2),O(n*(n-1)/2)=O(n^2),O(5n)=O(n),O(5)=O(1)。
总结来说,大O表示算法执行的最低上界。
3.为什么要进行计算时间复杂度?
我们先来看张图:
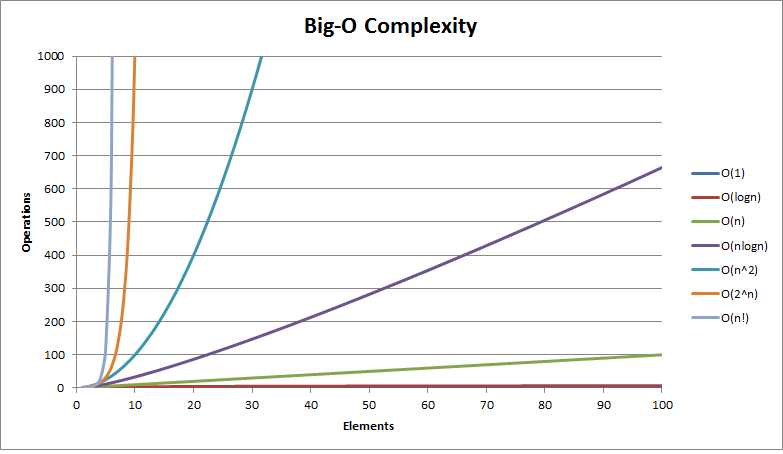
如果老板给你一个任务,让你对公司的账单从大到小进行排序,你可能会直接使用数据库自带的语句order by,的确,这是个好办法。如果你细致了解数据库,数据库的底层使用了B+树为数据建立了索引,时间复杂度明显降低。换个简单例子,如果老板让你把一堆数字进行排序,你可能最先想到选择排序,每次选择最小的数。老板说,这个太耗时了,你又会想到快速排序,选择一个基准数进行比较。老板又说,我给你的这些数基本有序,你又会想到插入排序,因为插入排序在基本有序的时候,算法复杂度接近O(n)。老板说,我还想快点,你想到了快速排序与插入排序的结合,等到快速排序排到很有序的时候,插入排序就有作用了。老板又说,我想在这些排序好的数字找到中间的数,这时候你可能想到,我直接数组[(0+n)/2]输出就行了,对的,因为数组本身就是一种很快的数据结构,相当于给每个数建立了索引,就可以直接取出数来,时间复杂度复杂度O(1)。
梳理一下:时间复杂度分别向O(n^2),O(nlogn),O(n),O(nlogn)+O(n),O(1)演变
| 复杂度 | 标记符号 | 描述 |
| 常量(Constant) |
O(1) |
操作的数量为常数,与输入的数据的规模无关。 n = 1,000,000 -> 1-2 operations |
| 对数(Logarithmic) |
O(log2 n) |
操作的数量与输入数据的规模 n 的比例是 log2 (n)。 n = 1,000,000 -> 30 operations |
| 线性(Linear) | O(n) |
操作的数量与输入数据的规模 n 成正比。 n = 10,000 -> 10000 operations |
| 平方(Quadratic) | O(n2) |
操作的数量与输入数据的规模 n 的比例为二次平方。 n = 500 -> 250,000 operations |
| 立方(Cubic) | O(n3) |
操作的数量与输入数据的规模 n 的比例为三次方。 n = 200 -> 8,000,000 operations |
| 指数(Exponential) |
O(2n) O(kn) O(n!) |
指数级的操作,快速的增长。 n = 20 -> 1048576 operations |
为什么要这样演变呢?
时间复杂度的演变,就是为了更快更好的解决问题,使其效率越来越高。
另外贴出问题规模与执行时间之间的关系图:
| 复杂度 | 10 | 20 | 50 | 100 | 1000 | 10000 | 100000 |
| O(1) |
<1s |
<1s |
<1s |
<1s |
<1s |
<1s |
<1s |
| O(log2(n)) |
<1s |
<1s |
<1s |
<1s |
<1s |
<1s |
<1s |
| O(n) |
<1s |
<1s |
<1s |
<1s |
<1s |
<1s |
<1s |
| O(n*log2(n)) |
<1s |
<1s |
<1s |
<1s |
<1s |
<1s |
<1s |
| O(n2) |
<1s |
<1s |
<1s |
<1s |
<1s |
2s |
3-4 min |
| O(n3) |
<1s |
<1s |
<1s |
<1s |
20s |
5 hours |
231 days |
| O(2n) |
<1s |
<1s |
260 days |
hangs |
hangs |
hangs |
hangs |
| O(n!) |
<1s |
hangs |
hangs |
hangs |
hangs |
hangs |
hangs |
| O(nn) |
3-4 min |
hangs |
hangs |
hangs |
hangs |
hangs |
hangs |
上面关于排序的优化的文章我在前面已经做出Java代码的演示,地址:从优化的角度谈谈排序
谢谢大家的阅读,博客不易,转载请注明地址。