爬取网站内容并保存为PDF格式
1、安装pdf依赖包 pip install pdfkit
但是使用pdfkit时,还是会报错
Traceback (most recent call last): File "C:\Users\zhan\AppData\Roaming\Python\Python36\site-packages\pdfkit\configuration.py", line 21, in __init__ with open(self.wkhtmltopdf) as f: FileNotFoundError: [Errno 2] No such file or directory: b‘‘ During handling of the above exception, another exception occurred: OSError: No wkhtmltopdf executable found: "b‘‘" If this file exists please check that this process can read it. Otherwise please install wkhtmltopdf - https://github.com/JazzCore/python-pdfkit/wiki/Installing-wkhtmltopdf
根据提示官网下载 wkhtmltopdf ,并安装记录安装路径。
通过如下代码使用pdfkit
# path_wk = r‘D:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe‘ #安装位置 # config = pdfkit.configuration(wkhtmltopdf = path_wk) # pdfkit.from_string("hello world","1.pdf",configuration=config)
准备工作完成后开始代码实现:
#!/usr/bin/env python #coding:utf8 import sys import requests import pdfkit import re import os class HtmlToPdf(): def __init__(self): self.path_wk = r‘D:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe‘ self.config = pdfkit.configuration(wkhtmltopdf=self.path_wk) self.url = "http://www.apelearn.com/study_v2/" # self.reg = re.compile(r‘<li class="toctree-l1"><a.*?href="(.*?)">.*?</a></li>‘) self.reg = re.compile(r‘<li class="toctree-l1"><a.*?href="(.*?)">(.*?)</a></li>‘) self.dirName = "aminglinuxbook" self.result = "" self.chapter = "" self.chapter_content = "" def get_html(self): s = requests.session() response = s.get(self.url) response.encoding = ‘utf-8‘ text = self.reg.findall(response.text) self.result = list(set(text)) def get_pdfdir(self): if not os.path.exists(self.dirName): os.makedirs(self.dirName) def get_chapter(self): self.get_pdfdir() for chapter in self.result: pdfFileName = "{0}-{1}.pdf".format(chapter[0].split(‘.‘)[0],chapter[1]) # pdfFileName = chapter[0].replace("html", "pdf") pdfUrl = "{0}{1}".format(self.url, chapter[0]) filePath = os.path.join(self.dirName, pdfFileName).strip() print(pdfUrl) print(filePath) try: pdfkit.from_url(pdfUrl, filePath, configuration=self.config) except Exception as e: print(e) def main(): html2pdf = HtmlToPdf() html2pdf.get_html() html2pdf.get_chapter() if __name__ == "__main__": main()
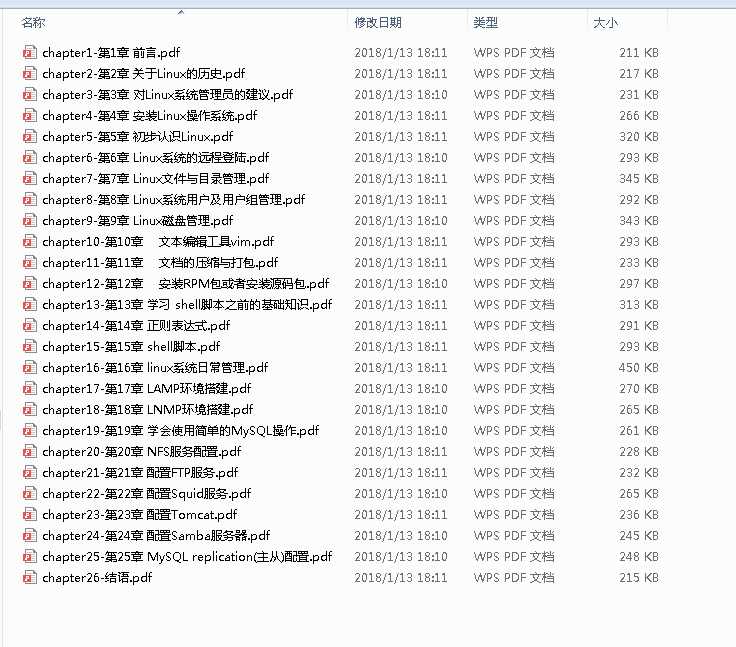
运行结果:

在目录中查看下载到的PDF文件