object detection我的理解,就是在给定的图片中精确找到物体所在位置,并标注出物体的类别。object detection要解决的问题就是物体在哪里,是什么这整个流程的问题。然而,这个问题可不是那么容易解决的,物体的尺寸变化范围很大,摆放物体的角度,姿态不定,而且可以出现在图片的任何地方,更何况物体还可以是多个类别。
object detection技术的演进:
RCNN->SppNET->Fast-RCNN->Faster-RCNN
从图像识别的任务说起
这里有一个图像任务:
既要把图中的物体识别出来,又要用方框框出它的位置。
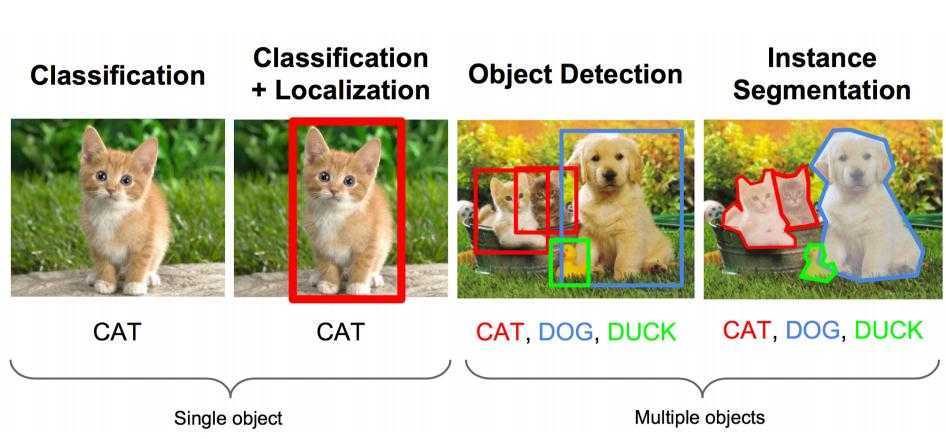
上面的任务用专业的说法就是:图像识别+定位
图像识别(classification):
输入:图片
输出:物体的类别
评估方法:准确率

定位(localization):
输入:图片
输出:方框在图片中的位置(x,y,w,h)
评估方法:检测评价函数 intersection-over-union ( IOU )

IOU的定义
因为没有搞过物体检测不懂IOU这个概念,所以就简单介绍一下。物体检测需要定位出物体的bounding box,就像下面的图片一样,我们不仅要定位出车辆的bounding box 我们还要识别出bounding box 里面的物体就是车辆。对于bounding box的定位精度,有一个很重要的概念,因为我们算法不可能百分百跟人工标注的数据完全匹配,因此就存在一个定位精度评价公式:IOU。

IOU定义了两个bounding box的重叠度,如下图所示:
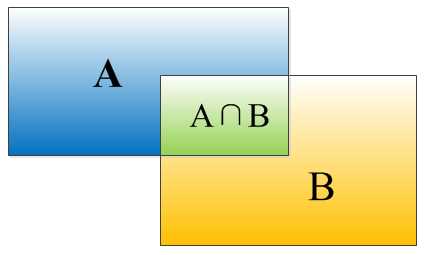
矩形框A、B的一个重合度IOU计算公式为:
IOU=(A∩B)/(A∪B)
就是矩形框A、B的重叠面积占A、B并集的面积比例:
IOU=SI/(SA+SB-SI)
例子:
先假设有6个矩形框,根据分类器类别分类概率做排序,从小到大分别属于车辆的概率分别为A、B、C、D、E、F。
(1)从最大概率矩形框F开始,分别判断A~E与F的重叠度IOU是否大于某个设定的阈值;
(2)假设B、D与F的重叠度超过阈值,那么就扔掉B、D;并标记第一个矩形框F,是我们保留下来的。
(3)从剩下的矩形框A、C、E中,选择概率最大的E,然后判断E与A、C的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。
就这样一直重复,找到所有被保留下来的矩形框。
思路一:看做回归问题
看做回归问题,我们需要预测出(x,y,w,h)四个参数的值,从而得出方框的位置。
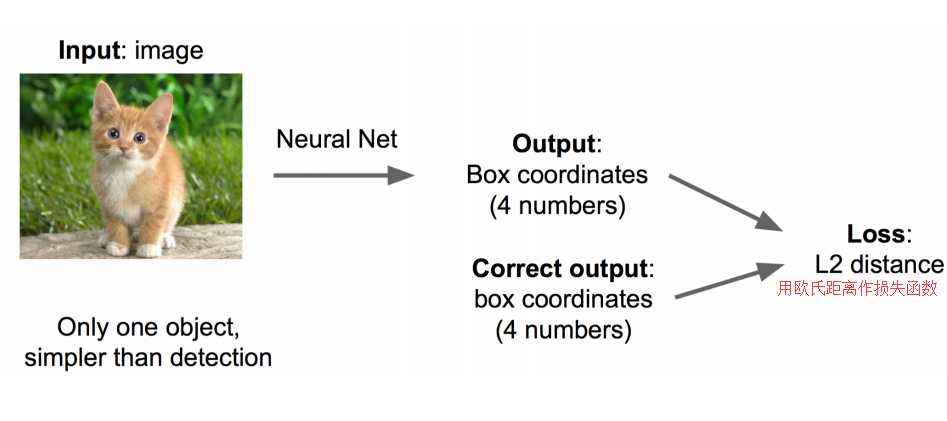
步骤1:
? 先解决简单问题, 搭一个识别图像的神经网络
? 在AlexNet VGG GoogleLenet上fine-tuning一下
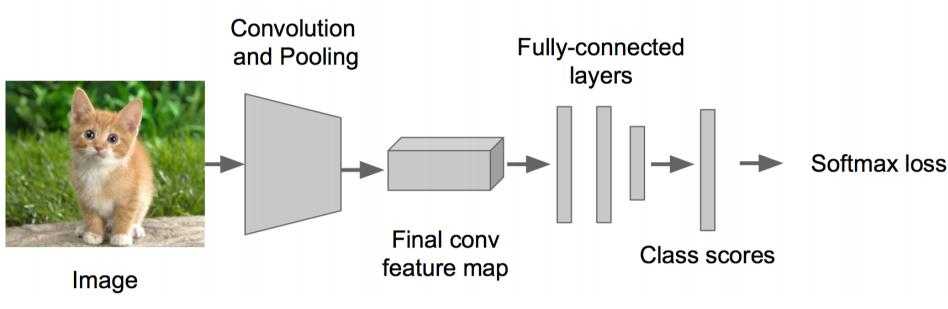
步骤2:
? 在上述神经网络的尾部展开(也就说CNN前面保持不变,我们对CNN的结尾处作出改进:加了两个头:“分类头”和“回归头”)
? 成为classification + regression模式
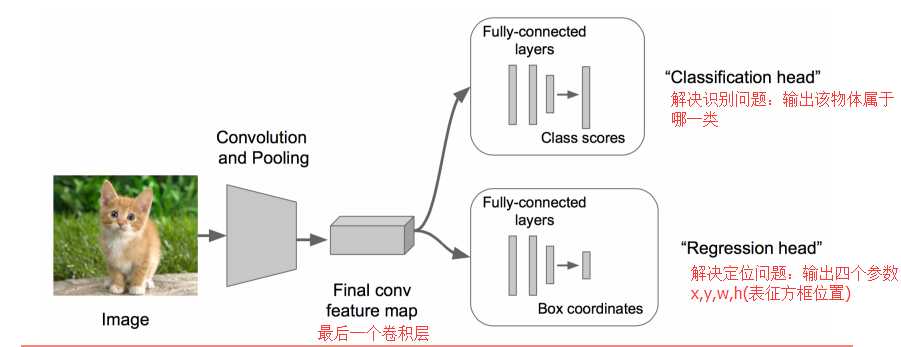
步骤3:
? Regression那个部分用欧氏距离损失
? 使用SGD训练
步骤4:
? 预测阶段把2个头部拼上
? 完成不同的功能
这里需要进行两次fine-tuning
第一次在ALexNet上做,第二次将头部改成regression head,前面不变,做一次fine-tuning
Regression的部分加在哪?
有两种处理方法:
? 加在最后一个卷积层后面(如VGG)
? 加在最后一个全连接层后面(如R-CNN)
regression太难做了,应想方设法转换为classification问题。
regression的训练参数收敛的时间要长得多,所以上面的网络采取了用classification的网络来计算出网络共同部分的连接权值。
思路二:取图像窗口
? 还是刚才的classification + regression思路
? 咱们取不同的大小的“框”
? 让框出现在不同的位置,得出这个框的判定得分
? 取得分最高的那个框
左上角的黑框:得分0.5

右上角的黑框:得分0.75

左下角的黑框:得分0.6

右下角的黑框:得分0.8

根据得分的高低,我们选择了右下角的黑框作为目标位置的预测。
注:有的时候也会选择得分最高的两个框,然后取两框的交集作为最终的位置预测。
疑惑:框要取多大?
取不同的框,依次从左上角扫到右下角。非常粗暴啊。
总结一下思路:
对一张图片,用各种大小的框(遍历整张图片)将图片截取出来,输入到CNN,然后CNN会输出这个框的得分(classification)以及这个框图片对应的x,y,h,w(regression)
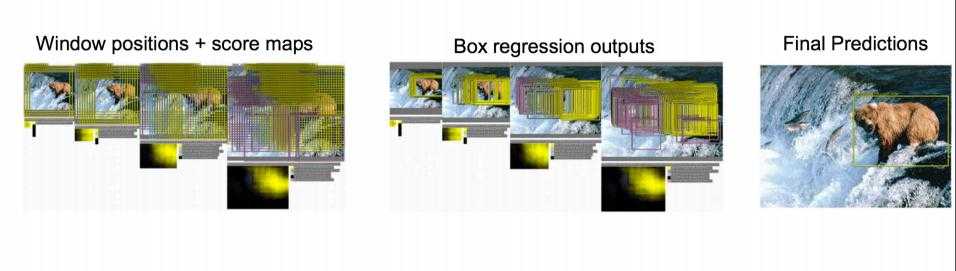
这方法实在太耗时间了,做个优化。
原来网络是这样的:
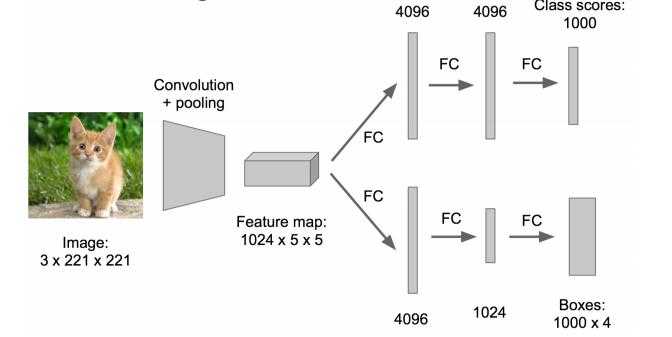
优化成这样:把全连接层改为卷积层,这样可以提提速
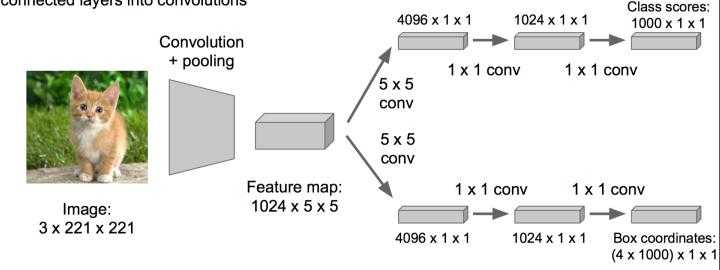
物体检测(Object Detection)
当图像有很多物体怎么办的?难度可是一下暴增啊。
那任务就变成了:多物体识别+定位多个物体
那把这个任务看做分类问题?

看成分类问题有何不妥?
? 你需要找很多位置, 给很多个不同大小的框
? 你还需要对框内的图像分类
? 当然, 如果你的GPU很强大, 恩, 那加油做吧…
看做classification, 有没有办法优化下?我可不想试那么多框那么多位置啊!
有人想到一个好方法:
找出可能含有物体的框(也就是候选框,比如选1000个候选框),这些框之间是可以互相重叠互相包含的,这样我们就可以避免暴力枚举的所有框了。

大牛们发明好多选定候选框的方法,比如EdgeBoxes和Selective Search。
以下是各种选定候选框的方法的性能对比。
R-CNN
基于以上的思路,RCNN的出现了。
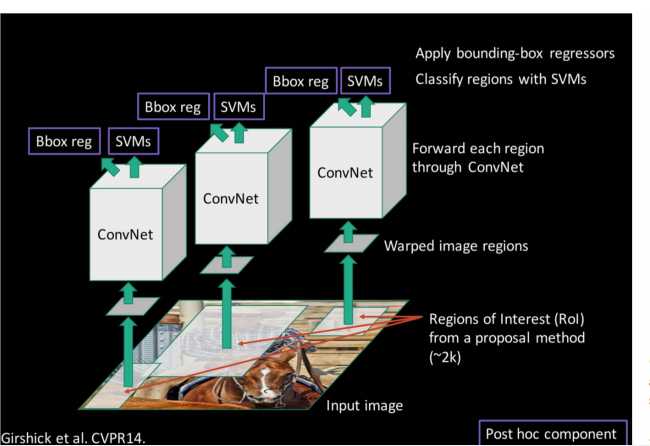
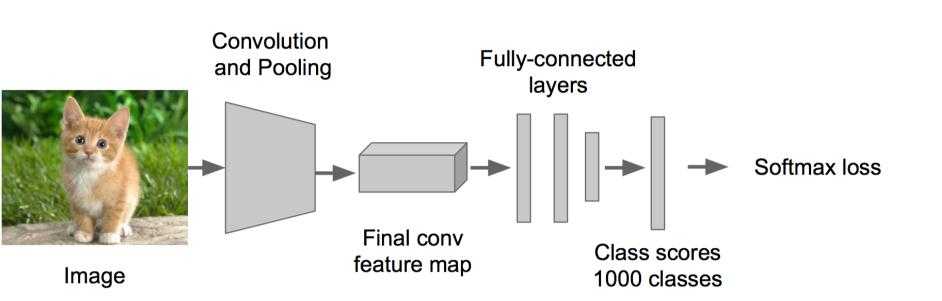
步骤一:训练(或者下载)一个分类模型(比如AlexNet)
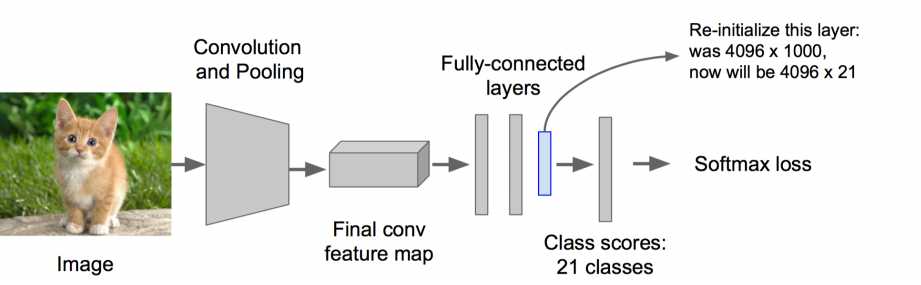
步骤二:对该模型做fine-tuning
? 将分类数从1000改为20(21位20个类别加上整张图片背景)
? 去掉最后一个全连接层
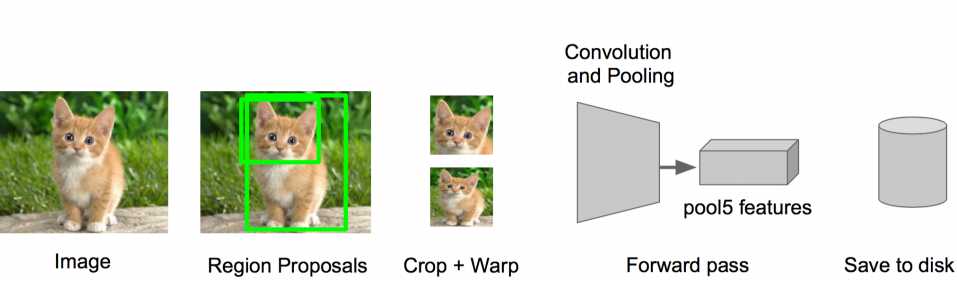
步骤三:特征提取
? 提取图像的所有候选框(选择性搜索)
? 对于每一个区域:修正区域大小以适合CNN的输入,做一次前向运算,将第五个池化层的输出(就是对候选框提取到的特征)存到硬盘
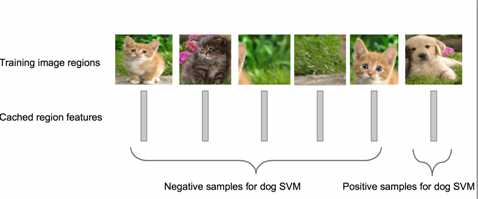
步骤四:训练一个SVM分类器(二分类)来判断这个候选框里物体的类别
每个类别对应一个SVM,判断是不是属于这个类别,是就是positive,反之nagative
比如下图,就是狗分类的SVM
步骤五:使用回归器精细修正候选框位置:对于每一个类,训练一个线性回归模型去判定这个框是否框得完美。
