??三维重建是指获取真实物体的三维外观形貌,并建立可复用模型的一种技术。它是当下计算机视觉的一个研究热点,主要有三方面的用途:1)相比于二维图像,可以获取更全面的几何信息;2)在VR/AR中,建立真实和虚拟之间的纽带;3)辅助机器人更好的感知世界。传统的三维重建方法主要是SfM(Structure from Motion),通过一系列不同位置采集的图像,离线计算出三维模型。帝国理工和微软研究院在2011年提出的KinectFusion开启了用RGBD相机实时三维重建的序幕。本文主要参考KinectFusion的论文[1-2],解析它的算法流程。
??KinectFusion由四部分组成(图1):首先,处理采集到的原始深度图,获取点云voxel的坐标以及法向量坐标;接着,根据当前帧的点云和上一帧预测出的点云计算当前相机的位置姿态;然后,根据相机位置姿态更新TSDF值,融合点云;最后根据TSDF值估计出表面。
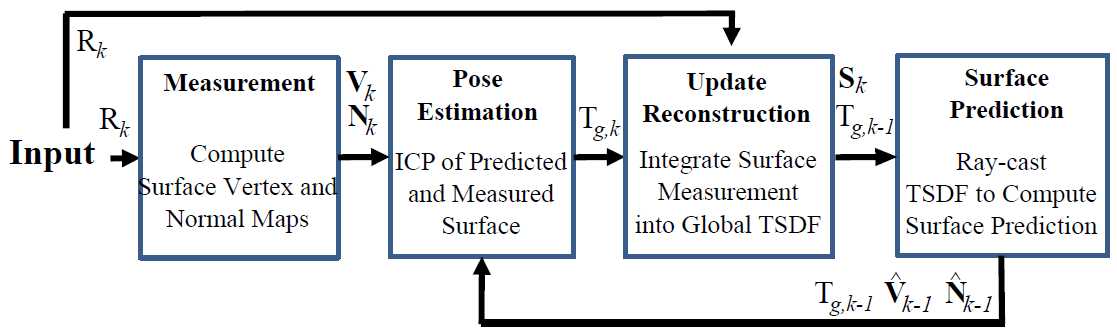
图1: KinectFusion整体算法流程。
??KinectFusion用一群voxel来描述三维空间。它把固定大小的一个空间(比如\(3m\times3m\times3m\))均匀分割成一个个小方块(比如\(512\times512\times512\)),每个小方块就是一个voxel,存储TSDF值以及权重。具体算法如下文所示。
1. 原始数据的处理
??流程和公式如图2所示。先对原始深度图\(R_k\)进行滤波降噪,这里选择双边滤波,目的是保持清晰的边界。一般的滤波是在空间域做加权平均,像素越靠近中心点,权重越高。双边滤波是在空间域加权平均的基础上再对值域加权平均,即像素灰度值越靠近中心像素的灰度值,权重越高。在边界附近,灰度值差异很大,所以虽然边界两边的像素在空间域靠在一起,但是由于灰度值差别非常大,对于互相的权重很低,所以可以保持清晰的边界,如图3所示。

图2:原始数据处理流程。
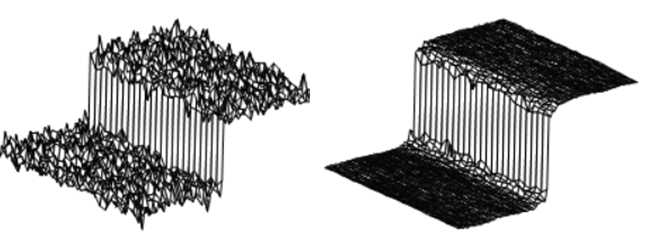
图3:双边滤波器。
??拿到降噪后的深度图\(D_k\)之后,再根据相机内参\(K\),可以反投影出每个像素点的三维坐标,这就是Vertex map \(V_k\)。公式中\(u\)是像素坐标,\(\dot{u}\)是对应的齐次坐标。每个vertex的法向量可以很方便的通过相邻vertex用叉乘得到。然后对深度图降采样,行数、列数各减一半。降采样使用的是均值降采样,即深度图上四个相邻像素的深度值被平均成一个值。构建三层金字塔的目的是为了从粗到细地计算相机位置姿态,有加速计算的效果。
2. 相机位置姿态的估计
??相机的位置姿态是用ICP (Iterative Closest Point) 求解的。ICP是处理点云的常规手段,通过最小化两块点云的差别,迭代求解出拍摄两块点云的相机之间的相对位置。有不同的方式来描述点云的差别,最常用的是point-to-point和point-to-plane两种。KinectFusion选择的是point-to-plane的方式,要把点到点的距离向法向量投影,如图4所示。2001年的一篇论文[3]详细比较了point-to-point和point-to-plane的效果,结论是point-to-plane要比point-to-point收敛速度快很多,而且更鲁棒。图5列出了[3]中的Figure15和16,比较了在两种点云形貌的情况下不同ICP的收敛速度和残差。
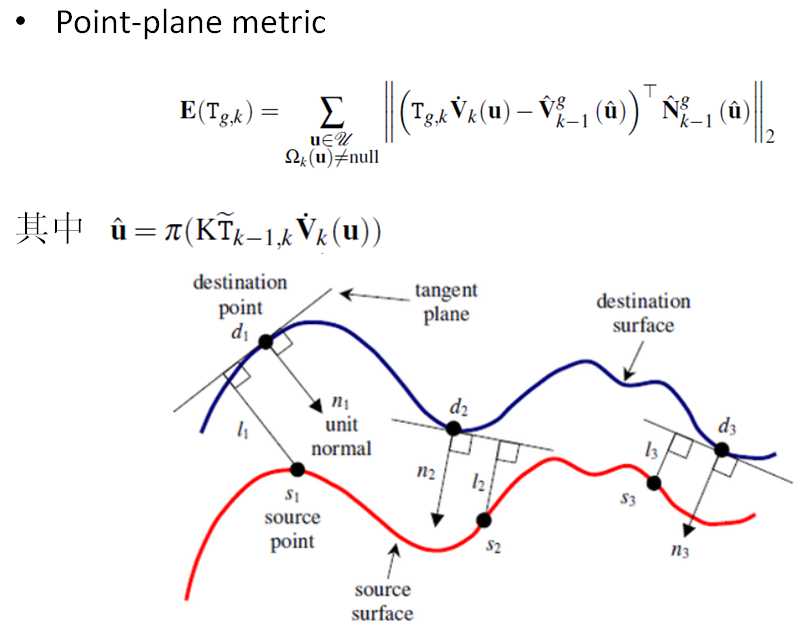
图4:Point-to-plane ICP.
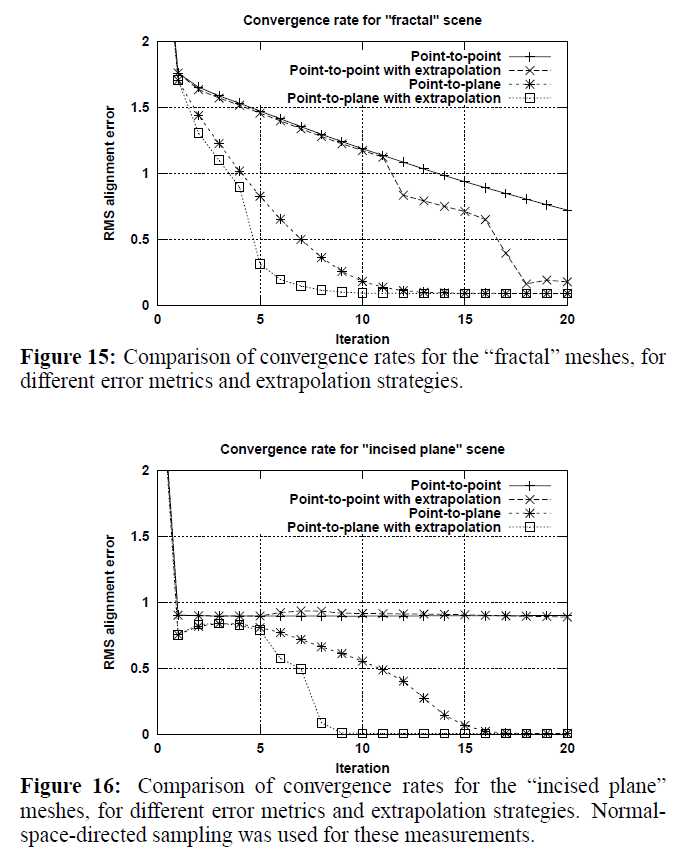
图5:论文[3]中不同ICP的对比。
??损失函数的公式中,\(T_{g,k}\)是第\(k\)帧图片时相机在世界坐标系下的位置姿态,这是优化求解的对象。\(\dot{V}_k(u)\)是第\(k\)帧深度图上像素\(u\)反投影出的vertex坐标,\(\hat{u}\)是这个vertex在第\(k-1\)帧图片的投影。为什么这里\(\hat{V}_{k-1}^{g}\)有hat上标呢?因为这里的vertex并不是直接在第\(k-1\)帧深度图上,而是第\(k-1\)帧融合TSDF后的预测值。如果直接用第\(k-1\)帧的数据,那这就是frame-to-frame的方式,会带来累计误差。而实际采用的是frame-to-model的方式,误差小很多。为了加速计算,这里利用了三层金字塔,从粗到细计算,最大迭代次数分别是\([4,5,10]\)。
3. TSDF的更新
??先介绍一个概念SDF(Signed Distance Function),SDF描述的是点到面的距离,在面上为0,在面的一边为正,另一边为负。TSDF(Truncated SDF)是只考虑面的邻域内的SDF值,邻域的最大值是max truncation的话,则实际距离会除以max truncation这个值,达到归一化的目的,所以TSDF的值在-1到+1之间,如图6所示。
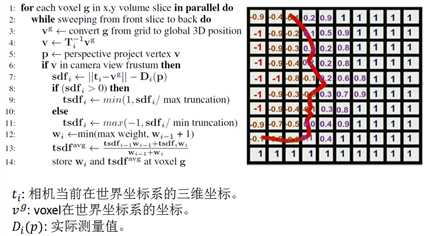
图6:TSDF的更新。
??TSDF的具体算法也在图6中,利用GPU并行处理各个voxel。首先把每个voxel根据计算出的相机位置姿态投影到相机上,如果在相机的视椎内,则会有一个像素点和它对应,\(D_i(p)\)是这个像素点距离表面的实际测量值,\(t_i-v^g\)则是voxel到相机的距离,两者的差就是SDF值。然后用max truncation归一化得到当前TSDF值。接着,用加权平均的方式更新TSDF值。voxel越正对着相机(如图7所示),越靠近相机,权重越大,用公式表示就是:\(W(p)\propto cos(\theta)/R_k(u)\),\(u\)是\(p\)的像。但论文[1]中也提到把权重全部设为1,对TSDF做简单的平均,也可以取得很好的效果;而如图6算法第12行,设置max weight后,可以去除场景中动态物体的影响(这一点没有特别想明白)。
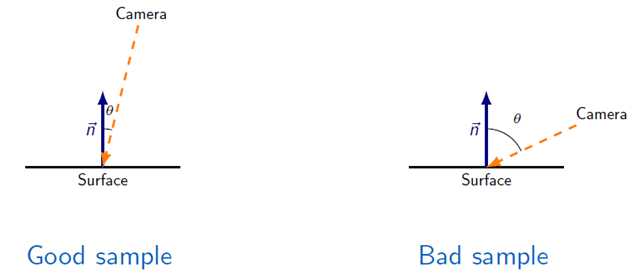
图7:TSDF的权重和相机观察方向的关系。
4. 表面的估计
??更新完TSDF值之后,就可以用TSDF来估计表面。这样估计出来的表面比直接用RGBD相机得到的深度图有更少的噪音,更少的孔洞(RGBD相机会有一些无效的数据,点云上表现出来的就是黑色的孔洞)。具体的表面估计方法叫Raycasting。这种方法模拟观测位置有一个相机,从每个像素按内参\(K\)投射出一条射线,射线穿过一个个voxel,在射线击中表面时,必然穿过TSDF值为一正一负的两个紧邻的voxel(因为射线和表面的交点的TSDF值为0),表面就夹在这两个voxel里面。然后可以利用线性插值,根据两个voxel的位置和TSDF值求出精确的交点位置。这些交点的集合就呈现出三维模型的表面。
参考文献:
[1] Newcombe R A, Izadi S, Hilliges O, et al. KinectFusion: Real-time dense surface mapping and tracking[C]//Mixed and augmented reality (ISMAR), 2011 10th IEEE international symposium on. IEEE, 2011: 127-136.
[2] Izadi S, Kim D, Hilliges O, et al. KinectFusion: real-time 3D reconstruction and interaction using a moving depth camera[C]//Proceedings of the 24th annual ACM symposium on User interface software and technology. ACM, 2011: 559-568.
[3] Rusinkiewicz S, Levoy M. Efficient variants of the ICP algorithm[C]//3-D Digital Imaging and Modeling, 2001. Proceedings. Third International Conference on. IEEE, 2001: 145-152.