中文乱码
上篇《ZBar-windows下编译和使用》已经成功解析了条形码,但目标是二维码,经测试二维码中文会出现乱码。
下图二维码的内容是“http123测试456”,解析后的内容为“http123娴嬭瘯456”

搜索了一下关键词,解决方案如下http://blog.csdn.net/zizi7/article/details/51880129
修改文件 zbar/qrcode/qrdectxt.c:


1 latin1_cd=iconv_open("GB18030","UTF-8"); 2 /*But this one is often used, as well.*/ 3 sjis_cd=iconv_open("GB2312","UTF-8"); 4 /*This is a trivial conversion just to check validity without extra code.*/ 5 utf8_cd=iconv_open("UTF-8","UTF-8"); 6 ... 7 enc_list[1]=sjis_cd; 8 enc_list[0]=latin1_cd; 9 enc_list[2]=utf8_cd;
重新编译运行后,正确输出“http123测试456”

自己实现中文解码
ZBar解析后的字符原始输出是UTF-8格式,然后使用了iconv将其转换为相应的字符编码,但最终目标是移植到STM32F4上,如果要直接输出中文编码,有几种方案:
1. 把iconv移植到STM32F4上
2. 自己实现UTF8-8转中文编码
3. 把编码工作交给上位机
字符集和编码格式
搜索了一下字符编码规则,觉得方案2比方案1,3更容易实现。这里先简单介绍下与本文相关的字符集和编码格式。
1. Unicode
Unicode是字符集,也叫万国码,顾名思义就是包含所有国家的文字。
2. GB18030
GB18030是中文字符集,可以认为是Unicode的一个子集,还有其他GBXXXXX的中文字符集,他们的关系简单来说就是包含的中文字符个数不一样。简单起见,这里只是使用2个字节的GB18030,一共20902个汉字,也基本覆盖常见的汉字了。书读得少,4个字节的汉字也没认识几个。
3. UTF-8
UTF-8是Unicode字符集的一种编码格式,还有其他UTF-16,UTF-32,ZBar使用了 UTF-8。
UTF-8最大的一个特点,就是它是一种变长的编码方式。它可以使用1~6个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8的编码规则很简单,只有二条:
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。
2)对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。
(具体例子可以参考http://blog.csdn.net/xiaolei1021/article/details/52093706)
下表总结了编码规则,字母x表示可用编码的位。
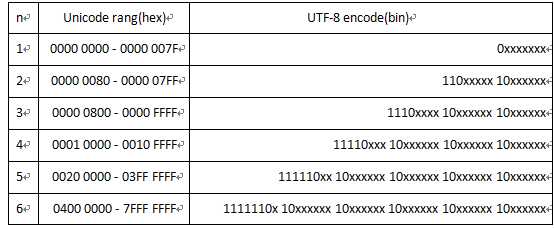
4. GB18030,Unicode,UTF-8的关系

UTF-8转GB18030实现
了解相关字符集和编码格式,可以开始写转换代码了。
1. 需要一个GB18030字符集,其实就是一个数组,实现代码如下(VS下编译)
调用UnicodeToGB18030Table函数生成一个GB18030字符集数组。
1 char* UnicodeToGB18030String(const wchar_t* unicode_str) 2 { 3 UINT code_page = 54936 ; //GB2312 :936 GB18030: 54936 4 int len=WideCharToMultiByte(code_page,0,unicode_str,-1,NULL,0,NULL,NULL); 5 char* buf=new char[len+1]; 6 WideCharToMultiByte(code_page,0,unicode_str,-1,buf,len,NULL,NULL); 7 buf[len]=0; 8 return buf; 9 } 10 int UnicodeToGB18030Table(void) 11 { 12 FILE *table; 13 wchar_t unicode[]={0x4E00,0}; 14 char* gb18030; 15 int cnt=0; 16 table = fopen("unicode_to_gb18030_table.c","w"); 17 if(table == NULL) 18 { 19 printf("can not open unicode_to_gb18030_table.c\n"); 20 system("pause"); 21 exit(0); 22 } 23 fprintf(table, "%s", "const char unicode_to_gb18030_table1[] = {\n"); 24 for(unicode[0]=0x4E00; unicode[0]<=0x9FA5; unicode[0]++) 25 { 26 gb18030 = UnicodeToGB18030String(unicode); 27 28 if(unicode[0]==0x9FA5) 29 { 30 fprintf(table, "0x%X,0x%X ", (UINT8)gb18030[0],(UINT8)gb18030[1]); 31 } 32 else 33 { 34 fprintf(table, "0x%X,0x%X, ", (UINT8)gb18030[0],(UINT8)gb18030[1]); 35 } 36 37 cnt ++; 38 if(cnt == 16) 39 { 40 cnt = 0; 41 fprintf(table, "\n"); 42 } 43 } 44 45 fprintf(table, "\n};"); 46 fclose(table); 47 }
2. 通过查表,将UTF-8转为GB18030
1 int zbar_utf8_to_gb18030 (uint8_t* utf8_code, uint32_t utf8_len, uint8_t* gb18030) 2 { 3 uint8_t utf8_bytes[3];//该数组最大为6个字节,但这里只考虑3个字节的中文编码 4 uint32_t i = 0, j = 0; 5 uint16_t unicode_value; 6 uint8_t* unicode = gb18030; 7 8 for(i=0; i< utf8_len; i+=3) { 9 utf8_bytes[0] = utf8_code[i+0] & 0x0F; 10 utf8_bytes[1] = utf8_code[i+1] & 0x3F; 11 utf8_bytes[2] = utf8_code[i+2] & 0x3F; 12 13 unicode[j] = (utf8_bytes[1] >> 2) | ((utf8_bytes[0]) << 4); 14 unicode[j+1] = utf8_bytes[2] | ((utf8_bytes[1] & 0x03) << 6); 15 unicode_value = (unicode[j]<<8) + unicode[j+1]; 16 if(unicode_value>=0x4E00){ 17 gb18030[j] = unicode_to_gb18030_table1[(unicode_value-0x4E00)*2]; 18 gb18030[j+1] = unicode_to_gb18030_table1[(unicode_value-0x4E00)*2 + 1]; 19 } 20 j += 2; 21 } 22 return 0; 23 }
中文字符集和编码转码函数有了,下一步就是替换ZBar源码的编码转换部分。
删掉zbar/qrcode/qrdectxt.c 中iconv相关的代码,将zbar_utf8_to_gb18030函数加入
qr_code_data_list_extract_text函数中:
1 int qr_code_data_list_extract_text(const qr_code_data_list *_qrlist, 2 zbar_image_scanner_t *iscn, 3 zbar_image_t *img) 4 { 5 .... 6 case QR_MODE_BYTE:{ 7 int gb18030_cnt = zbar_utf8_to_gb18030(entry->payload.data.buf, entry->payload.data.len, sa_text+sa_ntext); 8 sa_ntext += gb18030_cnt; 9 } 10 break; 11 .... 12 }
重新编译运行后
正确输出“http123测试456”
坐等下班,回家过年...................
