? 标记后的信息可形成信息组织结构,增加了信息的维度
? 标记的结构与信息一样具有重要价值
? 标记后的信息可用于通信、存储或展示
? 标记后的信息更利于程序理解和应用
HTML的信息标记:
? 文本,超文本(声音、图像、视频)
HTML通过预定义的<>...</>标签形式组织不同类型的信息。
信息标记的三种形式:
? XML、JSON、YMAL
XML(eXtensible Markup Language):

空元素的缩写形式:<img src = "china.jpg" size = "10"/>
注释书写形式:<!-- This is a comment , very useful -->
<name>...</name>
<name / >
<!-- -->
XML实例:

JSON(JaveScript Object Notation):
有类型的键值对 key : value
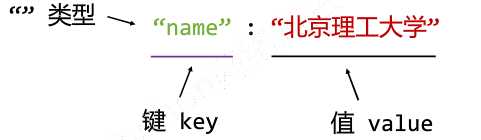
多值用[ , ]组织
键值对嵌套用{ , }
"name" : {
? "newName" : "北京理工大学",
? "oldName" : "延安自然科学院"
? }
JSON实例:

YAML(YMAL Ain‘t Markup Language) :
无类型键值对 key : value
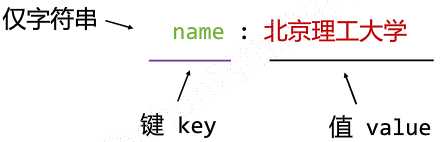
缩进表达所属关系
name :
? newName : 北京理工大学
? oldName : 延安自然科学院
减号( - )表达并列关系
name :
? -北京理工大学
? -延安自然科学院
|表达整块数据 #表示注释
key : value
key : #Comment
-value1
-value2
key :
? subkey : subvalue
YAML实例:

三种信息标记形式的比较:
XML : 最早的通用信息标记语言,可扩展性好,但繁琐
? Internet上的信息交互与传递
JSON : 信息有类型,适合程序处理(js),较XML简洁
? 移动应用云端和节点的信息通信,无注释
YMAL : 信息无类型,文本信息比例最高,可读性好
? 各类系统的配置文件,有注释易读
信息提取:从标记后的信息中提取所关注的内容
方法一:完整解析信息的标记形式,再提取关键信息
XML、JSON、YAML, 需要标记解析器,例如:bs4库的标签树遍历
? 优点:信息解析准确;
? 缺点:提取过程繁琐,速度慢;
方法二:无视标记形式,直接搜索关键信息
搜索 对信息的文本查找函数即可
? 优点:提取过程简介,速度较快;
? 缺点:提取结果准确性与信息内容相关;
融合方法:结合形式解析与搜索方法,提取关键信息
XML、JSON、YAML、搜索, 需要标记解析器及文本查找函数
实例:提取HTML中所有的URL链接
? 思路:搜索到所有的<a>标签;
? 解析<a>标签格式,提取herf后的链接内容;
>>> from bs4 import BeautifulSoup >>> import requests >>> r = requests.get("http://python123.io/ws//demo.html >>> demo = r.text >>> soup = BeautifulSoup(demo,‘html.parser‘) >>>for link in soup.find_all(‘a‘): print(link.get(‘href‘))
运行结果:
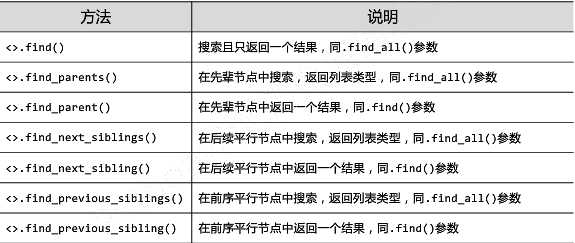
<>.find_all (name,attrs,recursive,string,**kwargs)
返回一个列表类型,存储查找的结果
? name:对标签名称的检索字符串;
? attrs :对标签属性值的检索字符串,可标注属性检索;
? recursive : 是否对子孙全部检索,默认True;
? string : <>...</>中字符串区域的检索字符串。
>>> soup.find_all(‘a‘) [<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>, <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>] >>> soup.find_all([‘a‘,‘b‘]) [<b>The demo python introduces several python courses.</b>, <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>, <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>]
? <tag>(..)等价于<tag>.find_all(..)
? <soup>(..)等价于<soup>.find_all(..)
实例:“大学排名定向爬虫”
? 输入:大学排名URL链接
? 输出:大学排名信息的屏幕输出(排名,大学名称,总分)
? 技术路线:request-bs4
? 定向爬虫:仅对输入URL进行爬取,不扩展爬取。
网址:http://www.zuihaodaxue.com/FieldSCI2016.html
#University rank li.py import requests from bs4 import BeautifulSoup import bs4 def getHTMLText(url): try: r = requests.get(url, timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "" def fillUnivList(ulist, html): soup = BeautifulSoup(html, "html.parser") for tr in soup.find(‘tbody‘).children: if isinstance(tr, bs4.element.Tag): tds = tr(‘td‘) ulist.append([tds[0].string, tds[1].string, tds[3].string]) def printUnivList(ulist, num): print("{:^10}\t{:^6}\t{:^10}".format("排名","学校名称","总分")) for i in range(num): u=ulist[i] print("{:^10}\t{:^6}\t{:^10}".format(u[0],u[1],u[2])) def main(): uinfo = [] url = ‘http://www.zuihaodaxue.com/FieldSCI2016.html‘ html = getHTMLText(url) fillUnivList(uinfo, html) printUnivList(uinfo, 20) # 20 univs main()
运行结果:

爬取2016年世界大学工科排名前二十:
网页链接:http://www.zuihaodaxue.com/FieldENG2016.html
#University Rank import requests from bs4 import BeautifulSoup import bs4 def getHTMLText(url): try: r = requests.get(url, timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "" def fillUnivList(ulist, html): soup = BeautifulSoup(html, "html.parser") for tr in soup.find(‘tbody‘).children: if isinstance(tr, bs4.element.Tag): # tds = tr(‘td‘) ulist.append([tds[0].string, tds[1].string, tds[3].string]) def printUnivList(ulist, num): tplt = "{0:^10}\t{1:{3}^10}\t{2:^10}" print(tplt.format("排名","学校名称","总分",chr(12288))) for i in range(num): u=ulist[i] print(tplt.format(u[0],u[1],u[2],chr(12288))) def main(): uinfo = [] url = ‘http://www.zuihaodaxue.com/FieldENG2016.html‘ html = getHTMLText(url) fillUnivList(uinfo, html) printUnivList(uinfo, 20) # 20 univs main()
结果截图:
