参考资料
《算法(java)》 — — Robert Sedgewick, Kevin Wayne
《数据结构》 — — 严蔚敏
为什么要使用哈希表
查找和插入是查找表的两项基本操作,对于单纯使用链表,数组,或二叉树实现的查找表来说,这两项操作在时间消耗上仍显得比较昂贵。 以查找为例:在数组实现的查找表中,需要用二分等查找方式进行一系列的比较后,才能找到给定的键值对的位置。而二叉树的实现中也存在着一个向左右子树递归查找的过程。 而现在,我们希望在查找/插入/删除这三项基本操作里, 能不通过比较,而是通过一个哈希函数的映射,直接找到键对应的位置,从而取得时间上的大幅优化, 这就是我们选用哈希表的原因。
相比起哈希表,其他的查找表中并没有特定的“键”和“键的位置”之间的对应关系。所以需要在键的查找上付出较大的开销。而哈希表则通过一个映射函数(哈希函数)建立起了“键”和“键的位置”(即哈希地址)间的对应关系,所以大大减小了这一层开销
哈希表的取舍
所谓选择,皆有取舍。哈希表在查找/插入/删除等基本操作上展现的优越性能,是在它舍弃了有序性操作的基础上实现的。因为哈希表并不维护表的有序性,所以在哈希表中实现有序操作的性能会很糟糕。例如:max(取最大键),min(取最小键), rank(取某个键的排名), select(取给定排名的键),
floor(向下取整) ceiling(向上取整)。 而相对的, 用二叉树等结构实现的查找表中,因为在动态操作(插入/删除)中一直维护着表的有序性,所以这些数据结构中实现的有序操作开销会小很多。
使用哈希表的前提
使用哈希表的前提是: 这个表存储的键是无序的,或者不需要考虑其有序性
哈希函数的构造
哈希函数有许多不同的构造方法,包括:1.直接定址法 2.数字分析法 3.平方取中法 4.折叠法 5. 除留取余法
1.直接定址法
取键或键的某个线性函数值为哈希地址。设 f 为哈希函数,key为输入的键,则f(key) = key或者 f(key) = k*key+b (k,b为常数)
例如,有一个解放后的人口调查表, 键为年份,则可设置哈希函数为: f(key) = key+ (-1948),如下图所示:


1949对应的哈希函数值为1, 1950对应的为2,依次类推
2.数字分析法
如下图所示,有80个记录,每一行为一个记录中的键,假设表长为100,则可取两位十进制数组成哈希地址。

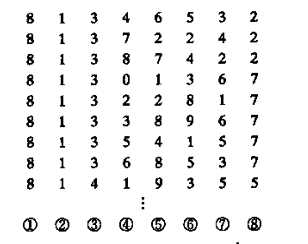
通过观察可以得出,第1,2列对应的数字都是相同的,而第3列和第8列存在大量重复的数字(分别是3和2,7),不能选做哈希地址。而中间4位可以看作是随机的,可以从中任选两位作为哈希地址
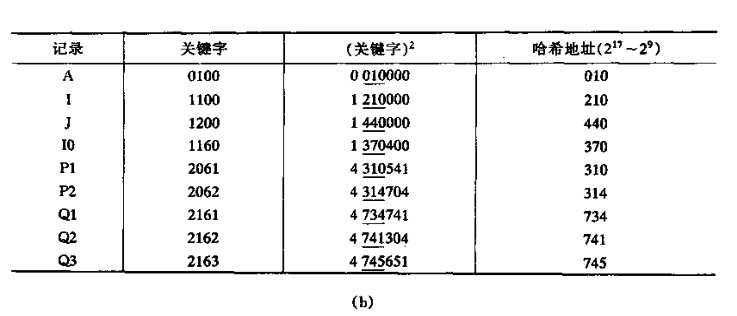
3. 平方取中法
取关键字平方后的中间几位为哈希地址,这种方法叫做平方取中法。它弥补了数字分析法的一些缺陷,因为我们有时并不能知道键的全部情况,取其中几位也不一定合适,而一个数平方后的中间几个数和原数的每一位都相关,由此我们就能得到随机性更强的哈希地址取的位数由表长决定。

4.折叠法
将关键字分成位数相同的几部分(最后一位可以不同),然后取叠加和作为哈希地址,这一方法被称为折叠法。当表的键位数很多,而且每一位上数字分布比较均匀的时候, 可以考虑采用这一方法。 折叠法有移位叠加和间位叠加两种方法例如国际标准图书编号0-442-20586-4的哈希地址可以用这两种方法表示为


5.除留余数法
除留余数法是最基础的,最常用的取得哈希函数的方法。选定一个统一的基数, 对所有的键取余,从而得到对应的哈希地址。下图中的M就表示这个统一的基数,在实现上,它一般是数组的长度

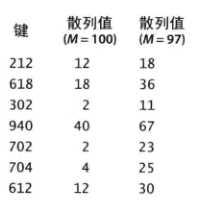
这也是我们接下来实现哈希表时采用的哈希函数方法。
哈希地址的冲突
一个经常会碰到的问题是; 不同的键经过哈希函数的映射后,得到了一个同样的哈希地址。这种现象叫做冲突(或者碰撞)如下图所示。

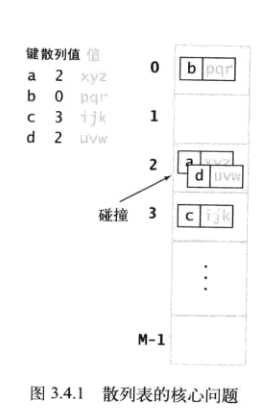
解决冲突的方法
冲突并不是一件严重的事情,因为我们可以用一些方式去解决它
解决冲突的方式有三种: 拉链法,线性探测法和再哈希法
拉链法
拉链法是基于链表实现的查找表去实现的,关于链表查找表可以看下我之前写的这篇文章:
拉链法处理冲突的思路是: 利用链表数组实现查找表。即建立一个数组, 每个数组元素都是一条链表。当不同的键映射到同一个哈希地址(数组下标)上时, 将它们挂到这个哈希地址(数组下标)对应的链表上, 让它们成为这条链表上的不同结点。

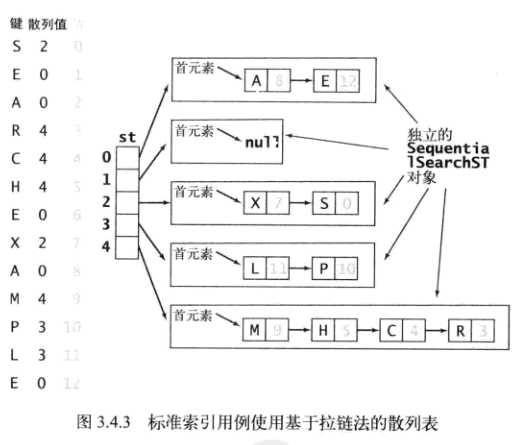
在拉链法中,哈希表的任务是根据给定键计算哈希值,然后找到对应位置的链表对象。剩下的查找/插入/删除的操作,就委托给链表查找表的查找/插入/删除接口去做。
即:
哈希表的查找操作 = 计算哈希值 + 链表查找表的查找操作
哈希表的插入操作 = 计算哈希值 + 链表查找表的插入操作
哈希表的删除操作 = 计算哈希值 + 链表查找表的删除操作


编写哈希函数
在Java中, 默认的hashCode方法返回了一个32位的整数哈希值,因为hashCode可能为负,所以要通过hashCode() & 0x7fffffff)屏蔽符号位,将一个32位整数变成一个31位非负整数。同时因为我们要将其运用到数组中,所以要再用数组大小M对其取余。这样的话就能取到在0和M-1间(数组下标范围内)分布的哈希值。
/** * @description: 根据输入的键获取对应的哈希值 */ private int hash (Key key) { return (key.hashCode() & 0x7fffffff) % M; }
下面给出拉链法的具体实现
- SeparateChainingHashST.java: 拉链法实现的哈希表
- SequentialSearchST.java: 链表查找表
- Test.java: 测试代码
SeparateChainingHashST.java(哈希表)
public class SeparateChainingHashST<Key,Value> { private int M; // 数组的大小 private SequentialSearchST<Key, Value> [] st; // 链表查找表对象组成的数组 public SeparateChainingHashST (int M) { st= new SequentialSearchST [M]; this.M = M; // 初始化数组st中的链表对象 for (int i=0;i<st.length;i++) { st[i] = new SequentialSearchST(); } } /** * @description: 根据输入的键获取对应的哈希值 */ private int hash (Key key) { return (key.hashCode() & 0x7fffffff) % M; } /** * @description: 根据给定键获取值 */ public Value get (Key key) { return st[hash(key)].get(key); } /** * @description: 向表中插入键值对 */ public void put (Key key, Value val) { st[hash(key)].put(key, val); } /** * @description: 根据给定键删除键值对 */ public void delete (Key key) { st[hash(key)].delete(key); } }
SequentialSearchST.java (链表查找表)
public class SequentialSearchST<Key, Value> { Node first; // 头节点 int N = 0; // 链表长度 private class Node { Key key; Value value; Node next; // 指向下一个节点 public Node (Key key,Value value,Node next) { this.key = key; this.value = value; this.next = next; } } public int size () { return N; } public void put (Key key, Value value) { for(Node n=first;n!=null;n=n.next) { // 遍历链表节点 if(n.key == key) { // 查找到给定的key,则更新相应的value n.value = value; return; } } // 遍历完所有的节点都没有查找到给定key // 1. 创建新节点,并和原first节点建立“next”的联系,从而加入链表 // 2. 将first变量修改为新加入的节点 first = new Node(key,value,first); N++; // 增加字典(链表)的长度 } public Value get (Key key) { for(Node n=first;n!=null;n=n.next) { if(n.key.equals(key)) return n.value; } return null; } public void delete (Key key) { if (N == 1) { first = null; return ; } for(Node n =first;n!=null;n=n.next) { if(n.next.key.equals(key)) { n.next = n.next.next; N--; return ; } } } }
测试代码
Test.java:
public class Test { public static void main (String args[]) { SeparateChainingHashST<String, Integer> hashST = new SeparateChainingHashST<>(16); hashST.put("A",1); // 插入键值对 A - 1 hashST.put("B",2); // 插入键值对 B - 2 hashST.delete("B"); // 删除键值对 B - 2 System.out.println(hashST.get("A")); // 输出 1 System.out.println(hashST.get("B")); // 输出 null } }
线性探测法
解决冲突的另一个方法是线性探测法,当冲突发生的时候,我们检查冲突的哈希地址的下一位(数组下标加一),判断能否插入,如果不能则再继续检查下一个位置。
【注意】线性探测法属于开放定址法的一种。 开放定址法还包括二次探测,随机探测等其他方法
实现类的结构如下:
public class LinearProbingHashST<Key, Value> { private int M; // 数组的大小 private int N; // 键值对对数 private Key [] keys; private Value [] vals; public LinearProbingHashST (int M) { this.M = M; keys = (Key []) new Object[M]; vals = (Value[]) new Object[M]; } /** * @description: 获取哈希值 */ private int hash (Key key) { return (key.hashCode() & 0x7fffffff) % M; } /** * @description: 插入操作 */ public void put (Key key, Value val) // 具体代码下文给出 /** * @description: 根据给定键获取值 */ public Value get (Key key) // 具体代码下文给出 /** * @description: 删除操作 */ public void delete (Key key) // 具体代码下文给出 }
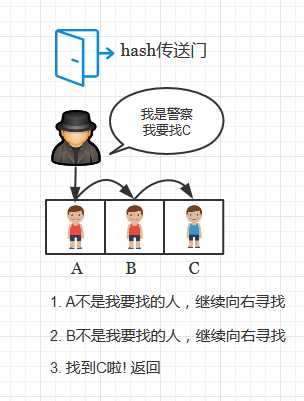
为了较好地理解, 下面我将线性探测表的实现比喻为一个“警察抓小偷”的游戏。把被插入的键值对看成”小偷“,把数组元素看成”小偷“躲藏的箱子。 则:
- 插入操作是小偷藏进箱子的过程;
- 查找操作是警察寻找某个小偷的过程;
- 删除操作是小偷被警察抓获,同时离开箱子的过程
插入操作
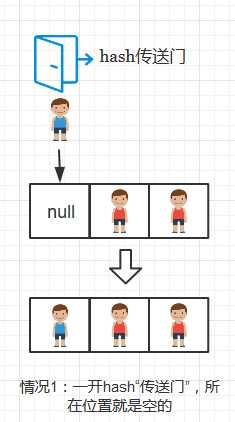
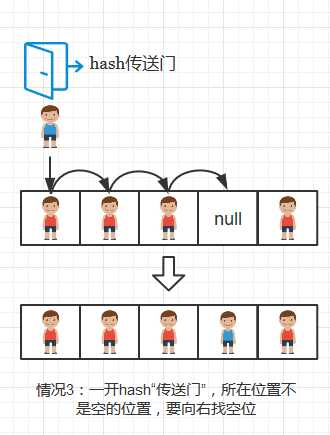
对某个位置进行插入操作时候,可分三种情况处理:
- 该位置键为空,则插入键值对
- 该位置键不为空,但已有键和给定键相等,则更新对应的值
- 该位置键和给定键不同,则继续检查下一个键
将插入键值对的过程比作游戏中小偷藏进箱子的过程,那么情况1和情况3可用下图表示:
情况1:

情况3:

插入操作代码
/** * @description: 调整数组大小 */ private void resize (int max) { Key [] temp = (Key [])new Object[max]; for (int i =0;i<keys.length;i++) { temp[i] = keys[i]; } keys = temp; } /** * @description: 插入操作 */ public void put (Key key, Value val) { // 当键值对数量已经超过数组一半时,将数组长度扩大一倍 if(N>(M/2)) resize(2*M); // 计算哈希值,求出键的位置 int i = hash(key); // 判断该位置键是否为空 while(keys[i]!=null) { if(key.equals(keys[i])) { // 该位置的键和给定key相同,则更新对应的值 vals[i] = val; return; } else { // 该位置的键和给定key不同,则检查下一个位置的键 i = (i+1) % M; } } // 该位置键为空则插入键值对 keys[i] = key; vals[i] = val; N++; return; }
可循环的哈希表
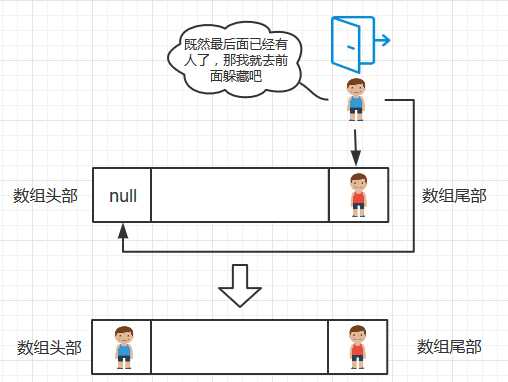
i = (i+1) % M这一语句使得线性探测的哈希表是可循环的
i = (i+1) % M的作用表现为两方面:
1. 如果当前的元素不是keys数组的最后一个元素, 那么游标i会移动到数组下一个元素的位置
2. 如果当前的元素是keys数组的最后一个元素, 那么游标i会移动到数组的头部,即第一个元素,这样就避免了当哈希值恰好为数组尾部元素而尾部元素非空时候插入失败
如下图所示:

及时调整数组大小的必要性
1. 在拉链法实现的哈希表中,因为链表的存在,可以弹性地容纳键值对,而对于线性探测法实现的哈希表,其容纳键值对的数量是直接受到数组大小的限制的。所以必须在数组充满以前调整数组的大小
2. 在另一方面,即使数组尚未充满,随着键值对的增加,线性探测的哈希表的性能也会不断下降。可以用键值对对数 / 数组大小来量化地衡量其对性能的影响, 如下图所示:

简单思考下就能明白为什么随着键值对占数组长度的比例的增加, 哈希表的性能会下降: 因为在这个过程中,将更容易形成长的键簇(一段连续的非空键的组合)。而哈希表的查找/插入等一般都是遇到空键才能结束, 因此,长键簇越多,查找/插入的时间就越长,哈希表的性能也就越差

因此,我们要及时地扩大数组的大小。如我们上面的代码中, 每当总键值对的对数达到数组的一半后,我们就将整个数组的大小扩大一倍。
查找操作
线性探测的查找过程也分三种情况处理
1.该位置键为空,则停止查找
2.该位置键不为空,且和给定键相等,则返回相应的值
3.该位置键不为空,且和给定键不同,则继续检查下一个键
如下图A,B, 将查找操作比喻成警察寻找某个小偷的过程:
图A:

图B:
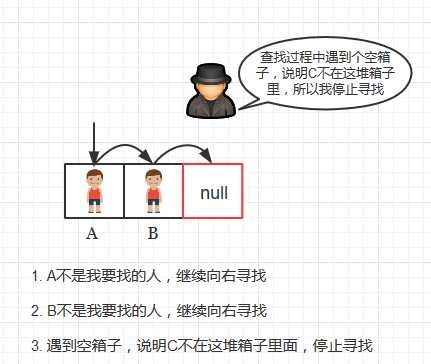

为什么遇到空键就返回?
因为插入操作是遇到空的位置就插入, 所以如果不考虑删除操作的话,哈希值相同的键一定是分布在连续的非空的键簇上的。 反之,遇到空的位置, 就说明这后面没有哈希值相同的键了, 所以这时就停止了查找操作
查找操作代码如下
/** * @description: 根据给定键获取值 */ public Value get (Key key) { for (int i=hash(key);keys[i]!=null;i=(i+1)%M) { if (key.equals(keys[i])) { return vals[i]; } } return null; }
删除操作
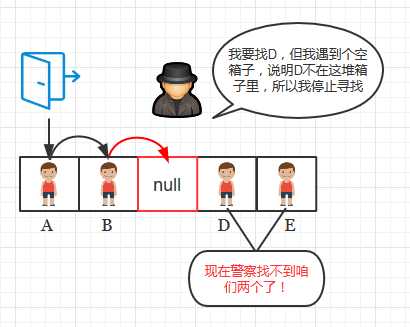
能直接删除某个键值对而不做后续处理吗? 这是不能的。因为在查找操作中,我们在查找到一个空的键的时候就会停止查找, 所以如果直接删除某个位置的键值对,会导致从该位置的下一个键到键簇末尾的键都不能被查找到了,如下图1,2所示, 将删除操作比喻成警察抓获某个小偷, 并让小偷离开箱子的过程
图1:

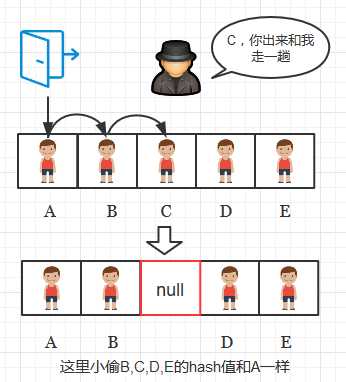
图2:

删除操作的正确方法
删除操作的正确方法是: 删除某个键值对,并对被删除键后面键簇的所有键都进行删除并重新插入

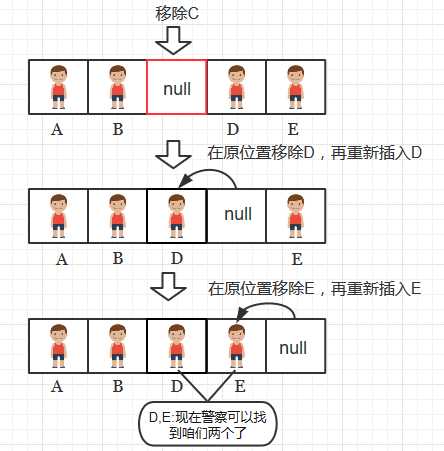
代码如下:
/** * @description: 删除操作 */ public void delete (Key key) { // 给定键不存在,不进行删除 if (get(key) == null) return ; // 计算哈希值, 求得键的位置 int i = hash(key); // 获取给定键的下标 while (!key.equals(keys[i])) { i = (i+1) % M; } // 删除键值对 keys[i] = null; vals[i] = null; // 对被删除键后面键簇的所有键都进行删除并重新插入 i = (i+1)%M; while (keys[i]!=null) { Key redoKey = keys[i]; Value redoVal = vals[i]; keys[i] = null; vals[i] = null; put(redoKey,redoVal); i = (1+1) % M; } N--; }
线性探测全部代码:
public class LinearProbingHashST<Key, Value> { private int M; // 数组的大小 private int N; // 键值对对数 private Key [] keys; private Value [] vals; public LinearProbingHashST (int M) { this.M = M; keys = (Key []) new Object[M]; vals = (Value[]) new Object[M]; } /** * @description: 获取哈希值 */ private int hash (Key key) { return (key.hashCode() & 0x7fffffff) % M; } /** * @description: 调整数组大小 */ private void resize (int max) { Key [] temp = (Key [])new Object[max]; for (int i =0;i<keys.length;i++) { temp[i] = keys[i]; } keys = temp; } /** * @description: 插入操作 */ public void put (Key key, Value val) { // 当键值对数量已经超过数组一半时,将数组长度扩大一倍 if(N>(M/2)) resize(2*M); // 计算哈希值,求出键的位置 int i = hash(key); // 判断该位置键是否为空 while(keys[i]!=null) { if(key.equals(keys[i])) { // 该位置的键和给定key相同,则更新对应的值 vals[i] = val; return; } else { // 该位置的键和给定key不同,则检查下一个位置的键 i = (i+1) % M; } } // 该位置键为空则插入键值对 keys[i] = key; vals[i] = val; N++; return; } /** * @description: 根据给定键获取值 */ public Value get (Key key) { for (int i=hash(key);keys[i]!=null;i=(i+1)%M) { if (key.equals(keys[i])) { return vals[i]; } } return null; } /** * @description: 删除操作 */ public void delete (Key key) { // 给定键不存在,不进行删除 if (get(key) == null) return ; // 计算哈希值, 求得键的位置 int i = hash(key); // 获取给定键的下标 while (!key.equals(keys[i])) { i = (i+1) % M; } // 删除键值对 keys[i] = null; vals[i] = null; // 对被删除键后面键簇的键的位置进行删除并重新插入 i = (i+1)%M; while (keys[i]!=null) { Key redoKey = keys[i]; Value redoVal = vals[i]; keys[i] = null; vals[i] = null; put(redoKey,redoVal); i = (1+1) % M; } N--; } }
测试代码:
public class Test { public static void main (String args[]) { LinearProbingHashST<String, Integer> lst = new LinearProbingHashST<>(10); lst.put("A",1); lst.put("B",2); lst.delete("A"); System.out.println(lst.get("A")); // 输出null System.out.println(lst.get("B")); // 输出 2 } }
再哈希法
设计多个哈希函数作为备份,如果发当前的哈希函数的计算会草成冲突,那么就选择另一个哈希函数进行计算,依次类推。这种方式不易产生键簇聚集的现象, 但会增加计算的时间
什么是好的哈希函数
在介绍完了解决冲突的方式后,我们再回过头来看什么是“好”的哈希函数, 一个“好”的哈希函数应该是均匀的, 即对于键的集合中的任意一个键,映射到哈希值集合中的的任意一个值的概率是相等的。
这样的哈希函数的效果进一步表现为两个方面:
1. 当冲突可以不发生的时候(如线性探测实现的哈希表),能尽可能地减少冲突的发生
2. 当冲突不可避免地要发生的时候(如拉链法实现的哈希表), 能使不同的哈希值发生冲突的概率大致相等, 从而保证哈希表动态变化时仍能保持较为良好的结构(各条链表的长度大致相等)
最后用一张图总结下文章内容:

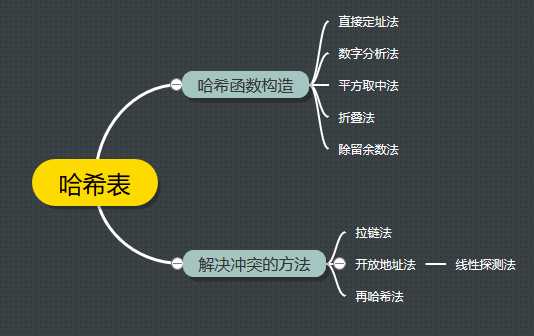
【完】
