背景
nginx其实有自带的limit_req和limit_conn模块,不过它们需要在配置文件中进行配置才能发挥作用,每次有频控策略的增删都需要直接改动配置文件,再让nginx重新加载配置文件,以配置文件的形式来管理导致整个流程不够灵活,因此它的实用性其实并不强,而且这也不适合大量的差异化的配置策略,不然配置文件更难维护了。基于此,下面展开了基于nginx的频率控制方案思考。本文不是最终的系统设计文档,很多地方都显得比较啰嗦和发散。
正文
上面简单谈了使用nginx自带的限流模块的局限性,下面谈谈我想要达到的目标。
目标
1 配置方面
支持组合频率控制,如对具体的ip地址,userid,参数值的组合项进行频率控制。在这里我打算只对固定元素进行频率控制,如对ip 1.2.3.4进行频率控制,或者对ip 为1.2.3.4且userid为u1024的请求进行频率控制,在这里不考虑集合性质的参数,如以ip为key做频率控制(因为这会涉及到元素的淘汰)
2 控制方面
可即时更改,即时生效,控制灵活,毕竟nginx自带的频率控制模块在使用上最大的缺陷就是不够灵活,导致实用性不强。
整体设计
针对上面的两点目标,再简单看一下整体设计
1开发人员在配置页面上配置相关限制策略,通过配置cgi将其写入DB
2 agent服务定期从DB中拉取全量最新的配置内容,处理后存储于共享内存中
3 接入层编写nginx模块,在Pre_Access阶段定期更新配置内容,同时获取请求信息,根据配置内容和请求信息进行频率控制
整体结构如下
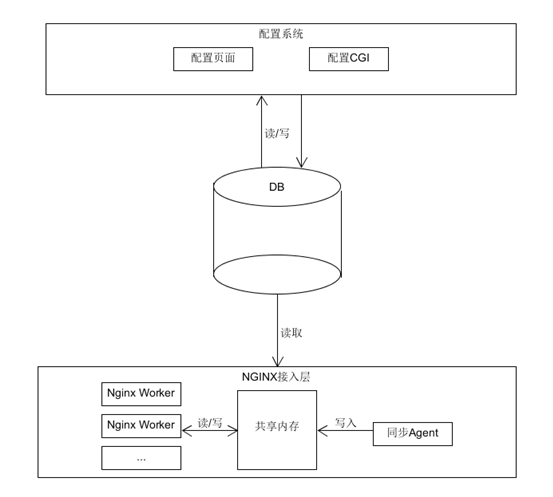
结构非常简单,其中同步agent直连db取配置这里在nginx接入层机器较少时是可以接受的。不过如果是为了长远考虑,可以在DB到nginx接入层之间加一层频率配置服务,由频率配置服务来处理配置信息,agent直接请求该服务即可。
详细设计
1 配置模块设计
配置系统较为简单,可采用配置页面+配置cgi+mysql的模式,主要作用为将用户的配置项落地db,此处直接略过。
2 限流算法选取
采用漏桶算法或者令牌桶算法,两种算法各有优劣
漏桶算法模型
此处引用一下网上的图
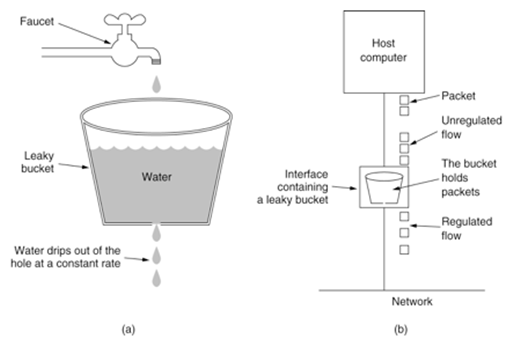
算法逻辑
1 根据配置的速率,按固定速率处理请求
2 当有请求到达时,计算桶内当前水量
3 若当前水量超过桶容量,请求被限制,直接返回错误(503)
4 若当前水量小于桶容量,请求根据当前水量进行休眠,休眠结束后处理请求
算法特性
流量稳定,均匀
令牌桶算法模型
此处引用一下网上的图
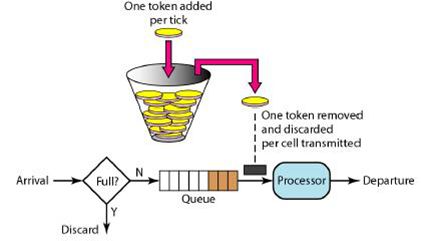
算法逻辑
1 根据配置的速率,按固定速度往桶中添加令牌,若桶内令牌数已满,则放弃
2 请求到达时从桶中获取一个令牌,获取失败则返回错误(503)
3 获取成功则放行请求
算法特性
允许并发,其中最高并发数为令牌桶容量
Nginx限流模块参考
Nginx的limit_req模块采取的限流算法是漏桶算法,但是做了一些改进,允许一定程度的并发(允许的并发大小由用户配置,当未配置并发时,则采用的就是原生的漏桶算法了)。
3 共享内存设计
1 全局设计
共享内存一共分为2块,分别是配置块,统计块,分别存储配置信息和请求统计信息。其中配置块又均分为A/B配置块用于实现RCU
配置块的表头结构如下(单位为byte)
| flag | segment | padding | seq | bitset |
|---|---|---|---|---|
| 4 | 1 | 3 | 4 | 128 |
1 flag
初始化flag,标识该块内存是否被初始化
2 segment
当nginx worker需要更新配置内容时进行读取,指向当前应该读哪片内存
3 padding
填充字节以及作为保留字节,用于保证seq 4字节对齐
4 seq
为总的配置操作流水,所有的nginx worker每次处理请求时都会读取该值,判断跟本地保存的配置内容的seq是否相等,如果相等的话,则是最新配置,无需更新,如果不相等,则触发配置更新逻辑
5 bitset
128字节,共1024bit,每个bit表示对应偏移的统计slot(用于统计请求信息,下文会提到)是否已被使用,因此系统最多可配置1024条策略(此处采用bit并不是为了节省内存占用,而是为了加速寻找到未被使用的统计slot,以8字节进行操作时,每次可判断64个bit的状态)
2 A/B内存块设计
由agent负责创建和管理,分为 A/B两块区域,通过RCU来避免agent与nginx worker的读写冲突。对于每个配置策略,agent都将分配一个统计slot用于统计请求信息。
| magic | size | item |
|---|---|---|
| 2 | 2 | ... |
1 magic
固定值,检测内存是否出现异常
2 size
表示后面有多少条策略item
3 item
策略item的内容
3策略item
即用户配置的具体限流策略
3 策略item
即用户配置的具体限流策略
| magic | version | length | padding | s_id | seq | offset | rate | size | cgi | key | value | ... |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 2 | 2 | 2 | 4 | 2 | 2 | 4 | 2 | ... | ... | ... | ... |
1 magic
固定值,用于检测当前的策略item是否出现异常,当读到错误值时,说明后续内容可能已经错乱,将跳出策略的加载逻辑,并进行错误上报
2 version
版本号,为后续功能扩展考虑
3 length
length为该条策略的总长度
4 padding
padding为填充和保留字段
5 s_id
策略id
6 seq
seq为该条策略的操作流水号,对配置更新时,大部分配置内容都是无需更新的,通过判断seq是否相等完成配置内容的增量更新
7 offset
用于定位对应的统计slot,初始化时将配置内容按s_id从小到大写入内存中,offset从0开始自增,策略更新时,不会影响offset值。(该字段的值与上面的bitset有关联)
8 rate
配置速率
9 cgi
需要限制的接口名,字符串,为length+value模式,使用2字节表示长度,后面跟上length个字节存储对应字符串
9 size
维度数量,即有几对key/value组合
10 key
Key表示限流维度,如为ip,userid或者业务参数等等,其存储结构为length+value的组合,表示具体的限流纬度
11 value
同key的设计,表示具体的值
4 统计表
根据配置内存块的策略item的offset值以及统计共享内存的初始地址,可以确定每条策略对应的统计slot
统计slot设计
| magic | padding | timestamp | count |
|---|---|---|---|
| 2 | 6 | 4 | 4 |
1 magic
固定值,用于检测当前的slot是否出现异常,当出现异常时,将初始化该块slot
2 padding
保留及填充区域,用于保证字节对齐
3 timestamp
统计周期时间戳
4 count
当前周期的统计量
字节对齐,共16byte
5 初始化及更新
初始化
共享内存的初始化工作由agent来做。
这里再回顾一下配置块表头的结构
| flag | segment | padding | seq | bitset |
|---|---|---|---|---|
| 4 | 1 | 3 | 4 | 128 |
初始化流程如下:
agent:
1 获取或者创建共享内存
2 如果是获取成功,则判断头4个字节是否为初始化完成flag,如果是的话则直接跳过初始化流程,否则进入4
3 如果是新创建的共享内存,则清0头4个字节
4 根据从db中读取到的数据初始化共享内存
5 将共享内存的头4个字节赋值为初始化完成flag
nginx worker:
1 获取共享内存地址失败,则直接放行请求
2 判断头4个字节是否为初始化完成flag,不是的话直接放行请求
2 将配置load进进程内存
6 配置策略存储
在各进程初始化完毕之后,开始加载共享内存中的配置策略,策略的加载按顺序读取共享内存中的信息即可,配置信息的存储结构如下
typedef strcut {
uint32_t s_id;
uint16_t seq;
uint16_t offset;
uint32_t rate;
uint32_t burst;
uint8_t *slot;
map<string,string> limits;
} LimitConf;7 配置策略快速查找
当请求进来时,依次遍历所有限制策略,对匹配的策略执行限流算法相关的逻辑,直至请求被限制,或请求通过所有策略为止,流程如下
1 遍历限流策略
2 策略是否匹配,不匹配则返回1,匹配则进入3
3 记录下该条命中策略的offset,在统计更新逻辑中将被使用到
4 遍历结束
5 对命中策略的统计slot信息进行更新
查找优化
假设我们有N条策略,每条策略平均有M个限制维度,那么遍历算法下的时间复杂度为O(MN)。
根据实际情况,一个请求不可能命中所有策略,以平均值计算,一个请求对于每条策略的维度匹配次数为M/2,每次匹配都需要2次字符串比较(key匹配后,还要进行value的匹配)
那么平均情况下也一共要进行N*M/2*2 = MN次字符串匹配
当策略变得很多时,策略的查找将会成为性能消耗的大头,如何解决呢?
每次请求进来时,我们都进行一次策略的遍历,很明显这是在做重复的事情,我们是否可以把每个请求中属于限流维度的信息提取出来,组成一个key,然后缓存这个key命中的策略呢?
在当前的设计下是不可行的,因为我们的限流纬度包括ip,userid这种扩散性太强的维度。既然如此,我们是否可以把ip,userid这类参数单独提取出来?毕竟对于此类参数,我们经常需要的是黑名单的功能。这里的取舍需要结合实际情况来考虑,在这里分了两种情况来考虑,1是将ip与userid拿出来,设计一个黑名单模块。2是维持上面的设计,即依然把ip,userid作为限流纬度。在情况1的前提下,我们还可以再次发散,那就是频率控制的对象肯定是各个接口,那我们还可以以接口作为索引,再做遍历,这样也能减少字符串匹配的次数。
下面我们来看看如果维持上面的设计,该如何优化一下查找性能。
集合匹配
以Key+Value的维度对限流策略进行集合划分,如ARG_A:test_value的为一个集合,ARG_B:*的为一个集合,USER_ID:u1024为一个集合。当请求到来时,根据M个限流维度,我们可以得到该请求的M个元素,分别为PT:XXX, CHID:XXX 等等....,之后查找出各个元素对应的集合(以map结构进行存储,key即各个元素字符串,value为下面的StrategyColl),再对各个集合取交集,得到的交集即命中的策略
存储结构设计
集合
typedef struct{
int max_offset;
uint64_t elts[16];//最多存放1024条策略
} StrategyColl;elts存储该集合拥有的元素,由于每条策略都有自己的offset值(该值由0开始递增),因此elts对应的第offset个bit为1即表示对应的策略在此集合中
max_offset表示该集合中的所有策略中的最大的offset值
集合求交集过程
伪代码如下
i = 0;
offset = (max(A.max_offset,B.max_offset)>>6)+1
while(i < offset){
C.elts[i] = A.elts[i]&B.elts[i];
cur_offset = (i<<6) + max_bit(C.elts[i]);
C.max_offset = cur_offset > C.max_offset?cur_offset:C.max_offset;
}假设有N条策略,维度数为M,每一个维度下用一个map结构进行存储,则至多有M个大小为N的集合,查询的时间复杂度为M*logN。
在取交集时的max_bit可使用二分法求出其位数为1的最高位bit。现在考虑一下实际的消耗,算上取交集的消耗后,总消耗为M*logN + kM(k为一次求交集的性能损耗,常数)。可根据最后的M与N的条数来采取遍历方案或者集合匹配方案
8多进程统计
由于nginx是多进程模型,而对于同一个限制策略我们都是在同一块共享内存上进行操作(读/写),这样会带来一个问题:如何解决读写冲突。
冲突的内存有如下位置:
1 配置策略
配置策略的冲突来源为多个nginx worker进程的读与agent的写。由于是单写多读的模式,采用RCU的模式可以完美解决该问题,将内存分为A/B两块区域,由变量X(1 byte)的值来决定使用哪块内存,如X=1使用A区域,X =2使用B区域。
2 统计slot
对于slot的统计由于我们需要同时更新水量(4字节)和时间戳(8字节),并且一个请求可能同时命中多条策略,因此需要使用锁来保证互斥。
统计逻辑
在这里我们以漏桶算法(令牌痛算法也类似)为例。
1 获取当前时间戳(cur_time)
2 使用自旋锁上锁
3 遍历命中的策略
4 对每一个策略,根据上一次请求被处理的时间戳(last_time),以及配置的速率rate,和上一次遗留的水量(pre_burst),计算当前的水量(cur_burst),根据当前水量和桶的最大容量MAX_BURST决定是否需要限流,伪代码如下
cur_burst =pre_burst - (cur_time - last_time) * rate + 1;
cur_burst = cur_burst > 0 ? cur_burst : 0;5 如果需要限流,释放锁,直接返回错误
6 不需要限流,则继续遍历
7 遍历结束后,对所有的命中策略进行更新,同时记录需要休眠的最大时间
8 释放锁
9 根据需要休眠的最大时间开始休眠,休眠结束后放行请求。
选取自旋锁的原因
自旋锁实现原理伪代码如下
while(!cas(p,0,1))
cpu_pause();其中cas为原子操作,如果p指向的地址中的值为0,则将其设置为1。返回true或者false,cpu_pause()并不是要让该进程放弃cpu,进入阻塞或者就绪状态,而是让CPU以一种节能的方式空转。通过下面的pause指令实现
__asm__ ("pause" )实际上使用时我们对于cpu_pause()的使用还会进行优化,用于减少激烈的cas操作,另外为了避免有进程上锁后core了,导致其它进程死循环,我们会对循环次数加上限制,最后的伪代码如下
cnt = 1;
while(!cas(p,0,1) && cnt <= MAX_LOOP){
for(i = 1; i <= cnt;i++ )
cpu_pause();
cnt=cnt<<1;
}解锁只需要
cas(p,1,0);由于我们上锁后的逻辑都属于计算型,且计算量较小,此处使用自旋锁的效率是很高的
风险
这里存在死锁的风险,一旦有进程上锁后,还没来得及释放,nginx重启了,那就没法再上锁了。由于共享内存的初始化是由agent做的,但是agent很难感知nginx是否重启(当然也是可以做到的,但是由agent去感知nginx重启以及找到死锁也是非常繁琐的一件事),因此需要有一种死锁识别和恢复策略,一种简单的策略是这样的:
1 在A/B块共享内存的信息头里扩展一个2字节的fail_cnt变量,每次有进程成功获取到slot锁都将对fail_cnt清0。
2 每次有进程在对该内存上锁失败后对fail_cnt进行value = fetch_and_add(p,1)的原子操作, 通过判断value的值,比如当value >= MAX_FAIL_CNT之后(另外我们可以在value>=MAX_FAIL_CNT时将value值进行上报,以此来监控是否有死锁出现),就认为此时出现了死锁,从而实现了死锁的识别。
识别之后,自然还需要对死锁进行恢复,恢复逻辑中可以采用文件锁,获取到文件锁的认为成功获取到了slot锁,进而清零fial_cnt变量,一切如初。
采用文件锁的原因:如果继续对一个新的变量使用自旋锁,那么由于自旋锁还是存在可能造成死锁的风险,导致这成为了一个死结。而文件锁在进程重启或者core时会自动释放掉。
当然,其实还有一种更优的方案,我们可以通过原子操作对fail_cnt进行清0,伪代码如下
update = true;
do{
fail_cnt = *pt_fail_cnt;
If(fail_cnt < MAX_FAIL_CNT){
update = false;
break;
}
}while( !cas(pt_fail_cnt,fail_cnt,0) );通过判断update值可知道是否是本进程清0成功,清0成功的认为获取到了锁。
如何无锁
在上述的频率控制方案中我们不得不使用自旋锁来实现互斥,原因有2点:
1 上述方案中一个请求可能命中多条策略,为了实现统计的精准度我们对共享内存进行了加锁
2 上述方案下多个进程都需要对burst(4byte) 和 timestamp(8byte)进行读和写,没法做到一次内存访问,但这两片内存的数据是有逻辑关联的,一荣俱荣,一损俱损,因此对它们的更新也需要做到原子性。
因此如果想做到无锁,需要针对以上两点做出如下两点对策
1 牺牲掉命中多条策略情况时的统计精准度
2 将上面对burst和timestamp的两次读/写操作合并为一次原子读/写操作
在实际的频率控制需求上,可以允许少量的误差,因此牺牲掉一定的精准度以换取更高的性能,在这里是可以接受的。
先设想这样一种情况,对于任何一个请求它都只会命中一条限制策略。在这种情形下,命中策略的查找能做到O(1),同时能轻松的实现无锁。
方案如下:
新的统计slot的结构如下
| magic | padding | timestamp | count |
|---|---|---|---|
| 2 | 6 | 4 | 4 |
共16个字节,这里不再采用漏桶算法,而是采用分时统计算法,当然相应的配置策略结构那边也需要调整,如不再需要burst变量来存储桶容量了。
1 count
统计变量
2 padding
填充字节,用于保证count,timestamp整体8字节对齐,timestamp 4字节对齐
3 timestamp
保存最新的时间周期,秒级。
更新逻辑
所有的更新操作都需要判断当前的时间戳(以下简称进程时间戳)与共享内存中的时间戳(以下简称共享时间戳)
当共享时间戳>=进程时间戳时,共享时间戳不需要更新
当共享时间戳< 进程时间戳时,count以及timestamp都需要更新。
更新时,count清0,同时更新时间戳,由于低32位就足够存储秒为单位的时间戳,以及机器字节序为小端模式,因此cas原子操作8字节(以uint64_t类型表示)直接赋值时间戳即可
伪代码如下
uint64_t cur_time = time(NULL);
uint64_t *pt_mix = p+offsetof(struct,timestamp);
uint64_t shm_mix;
uint32_t shm_time;
do{
shm_mix = *pt_mix;
shm_time = shm_mix & 0xFFFFFFFF;
if(shm_time >= cur_time)
break;
}while(!cas(pt_mix ,shm_mix,cur_time )//更新失败,则继续循环
以此保证最新的时间开始时,统计量也将被清0。以一个实例来说明该方案的运转。
当请求到来时,我们获取当前的时间戳(秒为单位),对共享时间戳执行判断和更新逻辑。
更新时统一采用原子操作,伪代码如下
origi_value = fetch_and_add(pt,1);通过origi_value可以知道请求是当前时间周期内的第多少个请求,再根据配置的速率决定是否限流。
现在回到之前的一个请求可能命中多条策略的情况。依然采用上述的无锁方案。更新逻辑将变成如下:
方案一
1 遍历命中的策略
2 对命中策略执行更新逻辑,用于保证统计新周期开始时,该策略的count会被清0
3 读取当前策略的count来判断是否会超过限流策略,如果会超过则直接返回503
4 遍历结束
5 再次遍历命中策略,对各条命中策略的统计变量count原子加1
方案二
1 遍历命中的策略
2 对命中策略执行更新逻辑,用于保证统计新周期开始时,该策略的count会被清0
3 对各策略的统计变量count原子加1,通过判断origi_value可知是否会超过限制,超过限制则进入5
4 遍历结束,请求放行
5 反向遍历已经统计过的策略,进行原子减1操作,遍历结束后,返回503
方案一误差分析
该方案的误差主要有如下2点:
1 由于一个请求可能命中多条策略,因此方案一中对统计变量count的限流逻辑判断和自增分离开了,即有可能连续的两个请求,上个请求通过后,还没来得及自增统计变量,或者只自增完部分统计变量,进程被切走,这时候落在另一个worker进程的下一个请求到达时,使用的还是上次的统计变量。不过这一点在方案二中会得到缓解,但是方案二在性能方面可能要落后一些(主要原因是原子加1和减1需要锁住系统总线),更重要的是由于原子减1时会在时间交界处带来误差,因此这里其实只是把方案二提出来供参考而已。
2 来自时间周期交界处的误差。设想一种极端情况,一个请求在某一秒的999ms时开始进行限流处理,当它更新完时间戳之后,进程被切走了,再切回来时shm_time已经变成了下一秒(这说明count变量也被清0过一次了),这会使本应属于上一周期的请求被统计到当前周期了,同理,当统计周期连续时,本周期的请求也可能被统计到下一周期。不过这个误差是可以定量分析的,其最大误差即系统的nginx work进程数-1。
隐患
隐患来自于分时统计算法本身的不稳定性,在漏桶算法下,流量将均匀的下传,这就像水坝一样,先对流量进行围堵,再通过闸门进行泄洪。而分时统计算法下,流量是可能在一个极小的时间片段中集中下传,容易对下层服务造成冲击(特别是一些涉及到访问db的服务)。
黑名单
讲到这里,内容其实已经快结束了,不过上面有提过将ip,userid一类扩散性极强的参数提取出来实现一个黑名单那模块,让我们来看看如何高效实现这一点。
黑名单内容只存放在共享内存,采用多阶hash(其中最后一阶采用线性探测来处理冲突,用于兜底)存储userid的hash值,ip地址由于本身可转化为一个uint32_t值,为避免误杀,因此不进行hash,直接使用。
表头结构如下
| magic | step_num | max_slot | current_num | seq |
|---|---|---|---|---|
| 2 | 2 | 4 | 4 | 4 |
1 magic
固定值,检测异常
2 max_slot
多阶hash的最大阶的slot数
3 step_num
多阶hash的阶数
4 current_num
当前的黑名单数量
5 seq
当前的公共seq值,每个slot也会有一个seq值,slot的seq值大于等于公共seq值才是有效的slot
黑名单slot设计
| hash_value | seq |
|---|---|
| 4 | 4 |
1 hash_value
Hash值
2 seq
当前slot的seq,当slot的seq大于等于公共seq时,才是有效的
黑名单更新
黑名单更新操作由agent来做,更新时将从db中将全量黑名单数据取出来,先将hash值全部计算出来,找到对应的slot将其seq值置为公共seq值+1,当slot冲突时,判断冲突slot的seq值是否大于头部的seq值,若小于等于的话直接替换,否则在下一阶继续寻找。若最后一阶依然冲突,则开始进行线性探测,若最后无slot可用,则上报错误。更新完毕后,公共seq值+1。此种更新方案下,可保证多阶hash不会出现断层,即在多阶hash表中不会有无效的策略位于有效策略前面(hash值取模后相同时将会产生slot冲突,保证了位于多阶hash前面的阶数的一定是最新的要被使用的策略)。
黑名单查找
黑名单查找工作由nginx worker来做,分别取出用户端ip,guid值计算hash值,经hash后,看slot中的hash值是否一致,再看对应的slot是否有效,当有效时拒绝掉请求。共享内存还未初始化时,将跳过黑名单查找过程,直接放行。
最后
以上为对固定元素进行频率控制时的方案思考。全文较长,很多地方都进行了发散,同时对碰到的技术问题也均提供了解决方案,正所谓代码未写,系统已成,我们在设计系统方案时就应该将系统的各个技术难点攻破,当然最终的方案肯定不能像我写的如此啰嗦,同时也需要跟实际情况结合来进行选取,在这里只是将我所想到的一些情况分享出来。
为什么最后的无锁方案中采用了分时统计算法而不是漏桶算法?
主要原因:在这里一旦采用漏桶算法后,性能将变得无法预期。
一般而言漏桶算法的时间精确度至少会为ms,这是因为一般而言我们的配置速率都是以s为单位,漏桶算法采用的时间精确度至少要小它一个数量级才行,否则无法对其进行精确划分,均匀控制流量。因此timestamp必须占用6个字节才行,下面是使用上述无锁方案,同时采用漏桶算法的伪代码。
uint64_t cur_time = time_ms(NULL);
uint64_t *pt_mix = p+offsetof(struct,timestamp);
uint64_t shm_mix;
Uint64_t cur_mix;
uint64_t shm_time;
Uint64_t shm_burst;
uint64_t cur_burst;
do{
shm_mix = *pt_mix;
shm_time = shm_mix & 0xFFFFFFFFFFFF;//低48位
shm_burst = shm_mix >> 48;
cur_burst =shm_burst - (cur_time - shm_time) * rate + 1;
cur_burst = cur_burst > 0 ? cur_burst : 0;
If(cur_burst > MAX_BURST)
fail();//请求结束,该请求被拒绝
cur_mix = cur_time + (cur_burst << 48)
}while(!cas(pt_mix ,shm_mix,cur_mix )//更新失败,则继续循环由于shm_time很可能会大于cur_time(持续的几次更新失败之后,就可能出现这种情况了),这时必须再次获取当前时间戳,否则算出来的cur_burst的误差会比较大。所以真正的伪代码如下:
uint64_t cur_time = time_ms(NULL);
uint64_t *pt_mix = p+offsetof(struct,timestamp);
uint64_t shm_mix;
uint64_t cur_mix;
uint64_t shm_time;
uint64_t shm_burst;
uint64_t cur_burst;
do{
shm_mix = *pt_mix;
shm_time = shm_mix & 0xFFFFFFFFFFFF;//低48位
shm_burst = shm_mix >> 48;
If(shm_time > cur_time)
cur_time = time_ms(NULL);
cur_burst =shm_burst - (cur_time - shm_time) * rate + 1;
cur_burst = cur_burst > 0 ? cur_burst : 0;
If(cur_burst > MAX_BURST){
fail();//请求结束,该请求被拒绝
return;//可以返回了
}
cur_mix = cur_time + (cur_burst << 48)
}while(!cas(pt_mix ,shm_mix,cur_mix )//更新失败,则继续循环 不同于分时统计算法当shm_time > cur_time时,它能跳出循环,即当别的进程更新成功时,本进程也能跳出循环,所有进程的目标都是让shm_time保持最新,它在性能方面的最差表现是当所有的nginx进程都进入新的统计周期时间戳后,必定会有进程更新成功,因为此时count变量不会再有变化,而所有worker的时间戳又都是一致的。
在采用漏桶算法时,当别的进程更新成功时,还将影响本进程的更新逻辑(需要重新获取时间戳),同时这里的cas操作成功的难度也非常高,在实现时自旋锁时,自旋锁的cas只有两种值,非0即1,而这里有无数种值,在性能方面的表现将变得很难预期,因此在无锁方案中放弃了漏桶算法。