标签:style blog http 使用 java strong 文件 数据 2014
实现一个控制台应用程序,来统计一个文件夹下的单词频率
要求
1.递归地进行统计
2.统计的文件格式为 .txt , .cpp , .h , .cs
3.单词定义:开头有至少3个英文字母,后面可以追加英文字母或数字
4.分隔符定义:空白符,非英文数字的字符
5.大小写:同一个单词大小写不同不区分开统计
6.输出:输出到 "邮件地址.txt"中
7.输出格式:每一条都形如"单词:出现次数",其中"单词"需要是文件夹下出现过的同一个单词中字典序最靠前的那个(基于ASCII),各条之间按照出现次数降序排序,如果出现次数相同,按单词字典序排序
8.模式:简单模式--在控制台使用程序,输入文件夹路径参数,输出简单的词频统计
扩展模式--(1):在控制台使用程序,输入两个参数,第一个是-e2,第二个是文件夹路径,输出出现次数最频繁的前10个双词词组,双词词组形如: 单词+单个空格+单词
(2):在控制台使用程序,输入两个参数,第一个是-e3,第二个是文件夹路径,输出出现次数最频繁的前10个三词词组,三次词组形如: 单词+单个空格+单词+单个空格+单词
程序设计
程序分为以下部分:
模式判断部分:判断命令行参数的正确性,并确定程序运行模式
遍历部分:递归地遍历文件夹
文档分词部分:分隔出文档中的单词,并记录每个单词与相邻单词之间的间隔符号情况
文档单词词组统计部分:统计一个文档中各单词出现的频率,并记录各单词出现过的字母表排序最靠前的形式
统计汇总部分:将单个文档的统计数据汇总到总统计中
排序部分:将总统计中的单词按照字典序排序
输出部分:按照参数给予不同的输出
预计时间
1.学习C++语言,查找需要用到的工具函数:6~8小时
2.遍历部分:2小时
3.文档分词部分:2小时
4.文档单词词组统计部分:2小时
5.统计汇总部分:1小时
6.排序+输出:1小时
总计:16小时
实际时间
1.学习C++语言,查找需要用到的工具函数: 10小时
2.遍历部分:半小时左右
3.文档分词部分:3小时
4.文档单词词组统计部分:3小时
5.统计汇总部分:1小时
6.排序+输出:1小时
7.代码优化: 3小时
总计:21小时左右
代码质量分析
分析过程中,报出2个警告:
第一个警告是提醒在调用string的size()方法时返回的是无符号整数. 我直接将其赋值给整形了,发现后进行了类型转换,消除了警告
第二个警告是提醒数组可能读取越界. 原因是我判断跳出循环的条件中对计数器的限制条件放在了与表达式的后面,而前面的条件中要访问计数器所指元素,发现后将限制条件提至最前,消除了警告.
性能分析
刚刚调试好程序后,就使用程序扫描了某软件的目录,性能分析报表如下:
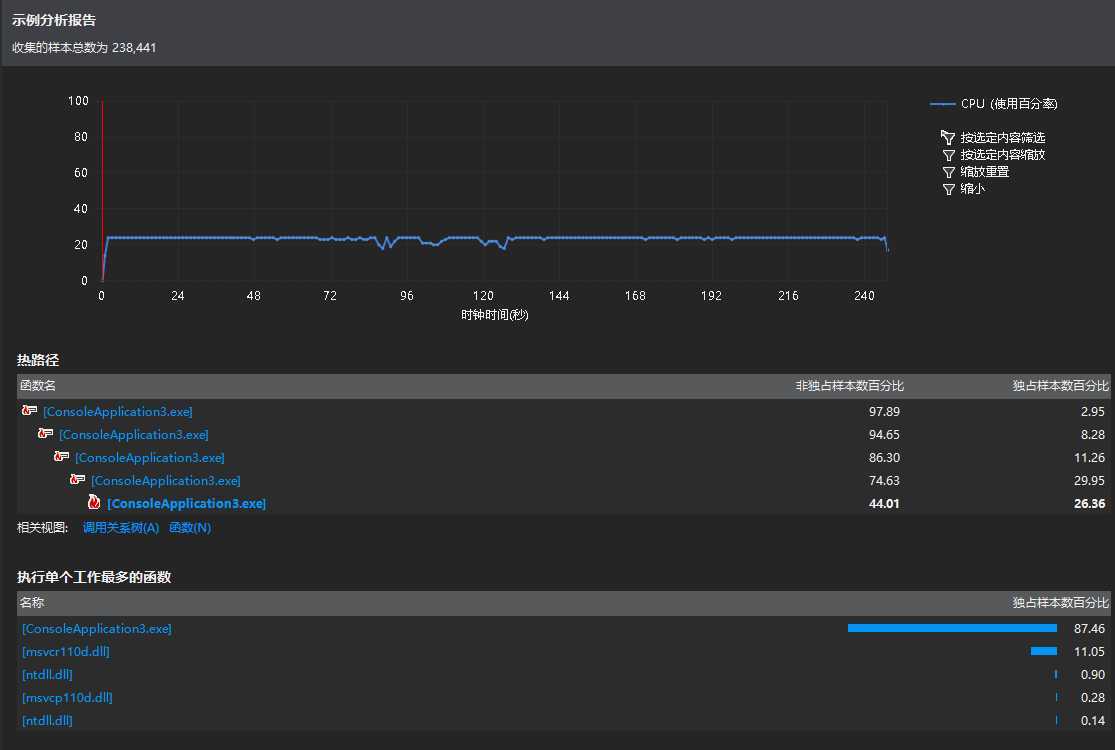
完成整个统计过程大概用了4分钟.
由于并没有使用哈希,二叉树搜索效率较高的结构,所以速度相对慢很多.
所以尝试着将单词的存储结构转变为了二叉树,以期提高一些效率.
将存储结构转变为二叉树后,统计同样的文件夹,性能分析报表如下:
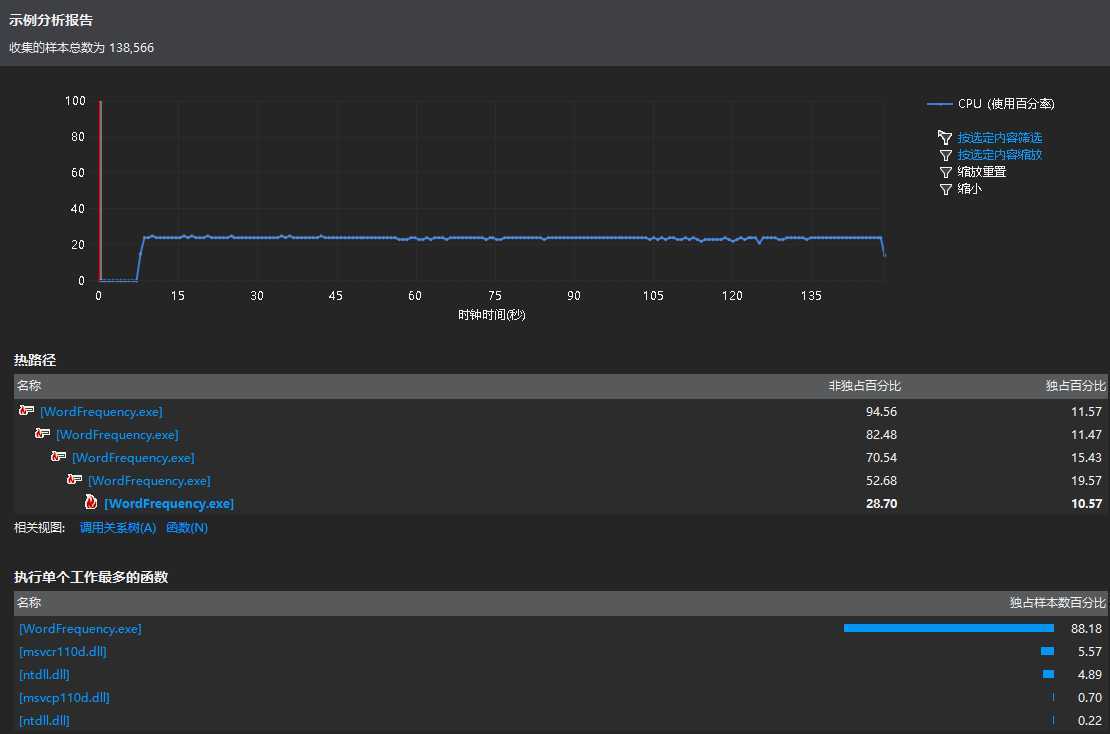
这次大约花费2分30秒的时间,就此例来看,大约节省了30%~40%的时间.
测试用例
1.空文件夹和空文件: 统计路径是一个空文件夹,输出了空的txt文件.
统计路径下是一个空文件夹和一个空txt文件,输出了空的txt文件.
2.大小写单词的合并: 路径下建立了一个cs文件,内容为:
"Morning moRning MoRnIng MOrNiNG MoRNING MORning"
程序输出为:

MORning是基于ASC2码字典序最靠前的,输出正确
3.单词的识别:路径下建立一个cpp文件,内容为:
"qwehs4f;r1if2233usdas3rs4sss4dshadssf4ui[qasasdw[shue"
程序输出为:

分词格式是正确的.
4.双词三词的识别: 路径下建立了一个h文件,内容为:
"good morning afternoon evening , have a good great awesome 123time asdf "
使用-e2模式,程序输出为:
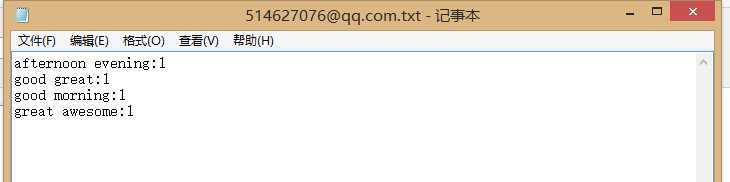
可见,程序能正确的判断双词词组,多个空格或者是中间隔着不是单词的字符串的相邻两个词都会被排除,连续的双词词组也能正确地统计.
使用-e3模式,程序输出为:
good great awesome:1
三词词组也是可以正确判断的.
5.单词的频率排序:路径下建立了一个txt文件,内容为:
"green red gray gray orange orange blue orange red blue blue orange gray gray purple black white gray white blue white black pink"
程序输出为:
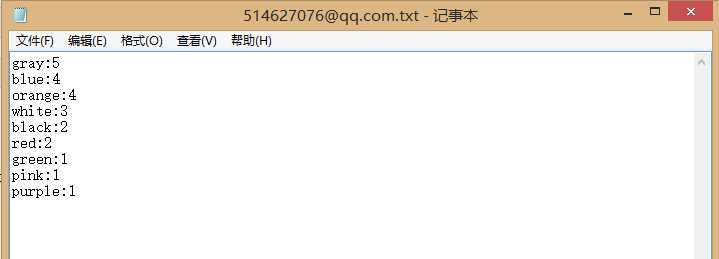
词频是降序的,输出正确.
6.同频率单词的字典序:路径下建立了一个txt文件,内容为
"Disk OpeN alert computer apple water light heaVy"
程序输出为:
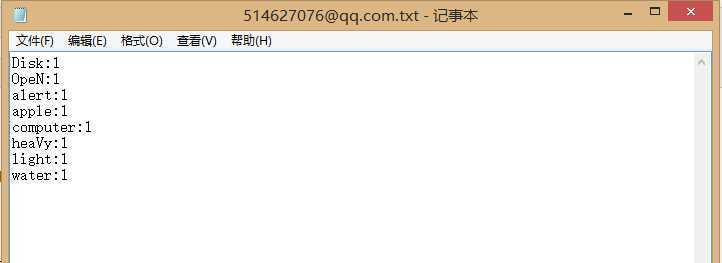
同频率单词是按字典序排序的,输出正确.
7.递归能力:在路径下建立文件夹1和2个内容同上的txt文件,文件夹1内建立文件夹2和2个内容同上的txt文件,文件夹2内是2个内容同上的txt文件.
输出如下:
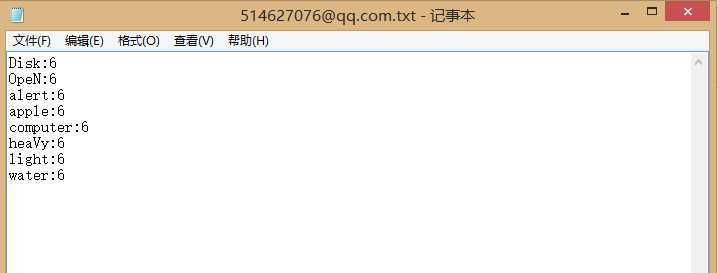
单词出现次数均为6,证明所有文件都被统计到了,递归正确.
8.测试非法命令:输入命令行参数"hsdfiudsd",输出"参数不正确!",输入命令行参数"-e2 iaufoq",输出"路径不存在" (均输出在控制台).
9.测试文件格式:上述用例的文件格式包含所有支持的格式,运行结果正确
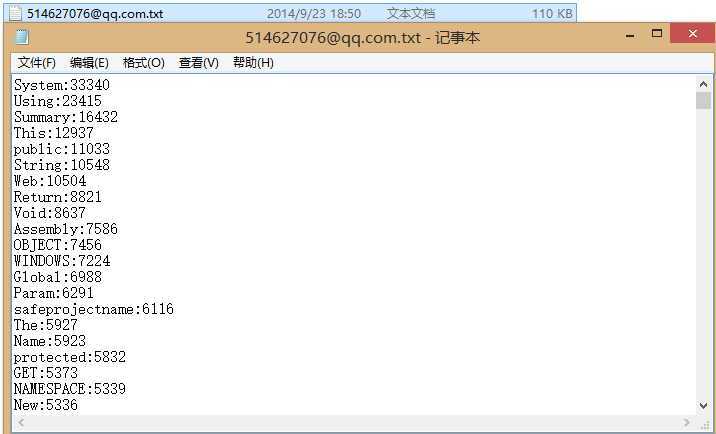
10.测试数据较多的文件夹:统计VS2012下的Common7文件夹
结果的前段如图,生成了一个110kb的txt输出文件.
感想
这次的编程经历是比较难得的 , 这是我第一次用不熟悉的语言直接编写一个几百行的程序.
虽然在编写之前看了很多函数和类型用法 , 但实际使用的时候还是很生疏 , 编的时候甚至有一种迷茫的感觉 , 因为没有办法校准函数的参数和返回值 , 不知道接下来要用的东西在跟哪个函数有关.
因为生疏 , 所以要不停地百度 , 在编写程序的过程中大概在网上看了四五十篇文章 , 才算初步的掌握了这个程序中使用的函数.
在翻阅文章的过程中 , 我开始觉得 , 现代程序语言还远没有想象中的那么方便 .
在查找所需函数时 , 我发现了这样一个事实 : 之前在JAVA编程中一直都在使用的方法在C++中基本都没有完美的替代品 .
读过的好几篇文章也都出现了 "重复造轮" , "不方便" , "反人类" 等等词语 . 很遗憾 , 它们都是用来形容C++的 .
看来如果想用的方便 , 唯一的方法就是让自己足够熟悉这门语言了.
完成这个程序后 , 我开始考虑我编写程序的过程 , 我发现我的构思过程一直都不怎么注重程序效率 , 每次都是先想好怎么解决问题 , 程序效率的问题就被逐渐地忽略掉了.
其实程序的效率与构思的关系是密不可分的 , 解决问题优先的算法无论怎么优化也不如那些一开始就兼顾正确性与效率的算法好 , 以后的程序构思我还是从最开始就考虑效率的问题吧.
还有一点 , C++提供的类和函数真的很重要 , 如果能基于一些十分优秀的类与函数构思算法 , 能起到事半功倍的效果 , 以后编程构思之前不妨先翻翻帮助文档.
标签:style blog http 使用 java strong 文件 数据 2014
原文地址:http://www.cnblogs.com/suwako/p/3983850.html