监督学习算法工作流程
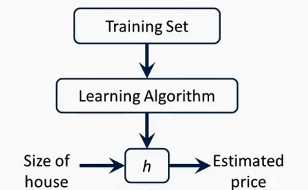
h代表假设函数,h是一个引导x得到y的函数
如何表示h函数是监督学习的关键问题
线性回归:h函数是一个线性函数
代价函数
在线性回归问题中,常常需要解决最小化问题。代价函数常用平方误差函数来表示
代价函数就是用于找到最优解的目的函数,这也是代价函数的作用
ps:尽可能简化问题去理解一些抽象概念,如单一的参数变化等等
可以利用代价函数去寻找你拟合效果最好的假设函数的参数
当参数很多时,利用图表来寻找最小代价函数就变得比较复杂,故引出梯度下降法。
梯度下降法最小化任意代价函数J

梯度下降法的思路:给定初始值,一般初始值为0.然后不断修改参数直到目标函数取到最小值
梯度下降法示意图:
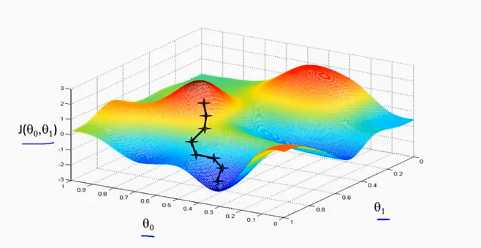
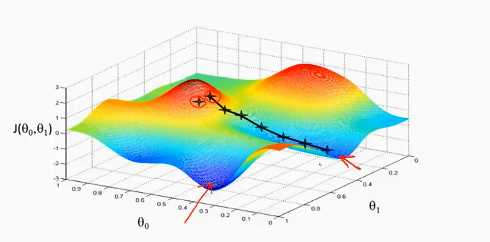
一、把图像看做一座山,梯度下降法就是寻找最快下山的路径。给定初始位置,寻找当前点下降最快的方向并往前迈进一小步,不断重复直到找到局部局部最优解。
二、当初始位置不同时,所得到的局部最优解也是不同的。
梯度下降法公式分析:

实现这个算法的关键是采用同步更新,即 。
。
梯度下降法可以收敛到局部最低点的原因:当处于最低点时,导数为0,此时的参数和原来的参数是一样的,而且学习率α保持不变且不为0(因为趋近于最低点时,导数的数值在不断地变小),最终θj依然可以保持不变。
此外,α的取值需要合适。太小算法运行时间较长,太大有可能越过局部最低点导致算法不收敛。