标签:line lib inf tin ... integer ima 正则 而且
https://github.com/ChAnYaNG97/wcPro.git
| PSP2.1 | PSP阶段 | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 25 | 30 |
| · Estimate | · 估计这个任务需要多少时间 | 30 | 40 |
| Development | 开发 | 60 | 70 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 60 |
| · Design Spec | · 生成设计文档 | 10 | 10 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 40 | 45 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| · Design | · 具体设计 | 40 | 40 |
| · Coding | · 具体编码 | 100 | 120 |
| · Code Review | · 代码复审 | 60 | 60 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 120 | 180 |
| Reporting | 报告 | 60 | 60 |
| · Test Report | · 测试报告 | 60 | 70 |
| · Size Measurement | · 计算工作量 | 100 | 90 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 20 |
| 合计 | 627 | 865 |
提供的接口:
IOController(String fileName)
IOController类的自定义构造函数,需要传入String类型的fileName参数
String readLine()
即每次调用都会返回文件的一行
void writeFile(HashMap<String, Integer> wordMap)
传入一个HashMap,将结果按照要求写入到文件中提供的接口:
void countWord(String input)
传入String类型的参数input,统计input中单词的数量,并存入HashMap中因为是使用正则表达式来对单词进行匹配,没有使用词法分析,所以程序结构简单,没有太多分支。
| 测试用例 | 预期输出 | 实际输出 |
|---|---|---|
| case.txt(单词数小于100) | 将统计好的单词词频写入result.txt | 正确写入文件 |
| case2.txt(单词数大于100) | 将统计好的前100个单词词频写入result.txt | 正确写入文件 |
| case2.c | "wrong file format!" | "wrong file format!" |
4.2.1 首先是对WordCounter类的测试
| 等价类 | 等价方法 |
|---|---|
| 等价类1 | 无连字符,无常见字符和数字 |
| 等价类2 | 无连字符,带常见字符和数字 |
| 等价类3 | 带连字符,无常见字符和数字 |
| 等价类4 | 带连字符且位于单词间,无常见字符和数字 |
| 等价类5 | 带连字符且位于单词后,无常见字符和数字 |
| 等价类6 | 带连字符且位于数字间,无常见字符 |
| 等价类7 | 带两个连字符且位于单词后,无常见字符和数字 |
| 等价类8 | 带连字符,带常见字符和数字 |
| 等价类9 | 输入为空 |
public class WordCounterTest
{
WordCounter wc;
HashMap<String, Integer> expected;
@Before
public void before()
{
wc = new WordCounter();
expected = new HashMap<>();
}
//test1:无连字符,无常见字符和数字
@Test
public void testCountWord1()
{
wc.countWord("this is a test a a a ");
expected.put("this",1);
expected.put("is",1);
expected.put("a",4);
expected.put("test",1);
assertEquals(expected, wc.countList);
}
//test2:无连字符,带常见字符和数字
@Test
public void testCountWord2()
{
wc.countWord("this]]‘$‘is‘a123test");
expected.put("this",1);
expected.put("is",1);
expected.put("a",1);
expected.put("test",1);
assertEquals(expected, wc.countList);
}
//test3:带连字符,无常见字符和数字
@Test
public void testCountWord3()
{
wc.countWord("this-is-a-test is is");
expected.put("this-is-a-test",1);
expected.put("is",2);
assertEquals(expected, wc.countList);
}
//test4:带连字符且位于单词间,无常见字符和数字
@Test
public void testCountWord4()
{
wc.countWord("this is a test this-is-a-test");
expected.put("this",1);
expected.put("is",1);
expected.put("a",1);
expected.put("test",1);
expected.put("this-is-a-test",1);
assertEquals(expected, wc.countList);
}
//test5:带连字符且位于单词后,无常见字符和数字
@Test
public void testCountWord5()
{
wc.countWord("this- is a-test");
expected.put("this",1);
expected.put("is",1);
expected.put("a-test",1);
assertEquals(expected, wc.countList);
}
//test6:带连字符且位于数字间,无常见字符
@Test
public void testCountWord6()
{
wc.countWord("this is1-2 a-test");
expected.put("this",1);
expected.put("is",1);
expected.put("a-test",1);
assertEquals(expected, wc.countList);
}
//test7:带连字符,带常见字符和数字
@Test
public void testCountWord7()
{
wc.countWord("(see Box 3–2).8885d_c01_016");
expected.put("see",1);
expected.put("box",1);
expected.put("d",1);
expected.put("c",1);
assertEquals(expected, wc.countList);
}
//test8:输入为空
@Test
public void testCountWord8()
{
wc.countWord("");
assertEquals(expected, wc.countList);
}
//test9:带两个连字符的单词
@Test
public void testCountWord9()
{
wc.countWord("this is a--simple-test.");
expected.put("this",1);
expected.put("is",1);
expected.put("a",1);
expected.put("simple-test",1);
assertEquals(expected, wc.countList);
}
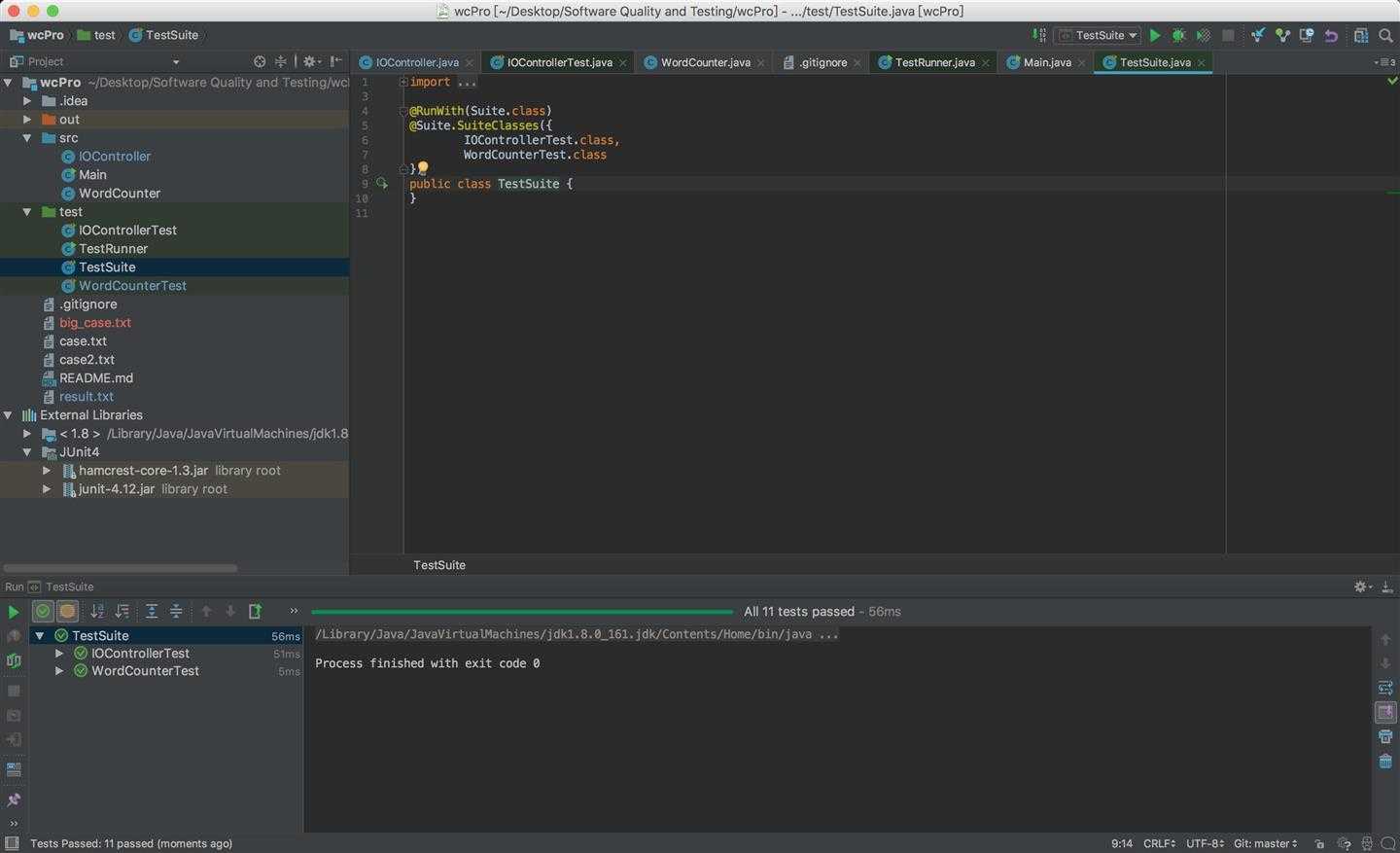
}4.2.2 对IOControllerTest的测试类
public class IOControllerTest {
@Test
public void testReadLine()
{
IOController input = new IOController("case2.txt");
String line = input.readLine();
String expected = "a-b-c f s d d";
assertEquals(expected, line);
}
@Test
public void testWriteFile()
{
HashMap<String, Integer> map = new HashMap<>();
IOController input = new IOController("result.txt");
map.put("k",1);
input.writeFile(map);
String result = input.readLine();
String expected = "k 1";
assertEquals(expected, result);
}
} 
选定的开发规范是阿里巴巴的Java开发规范,参考资料为《阿里巴巴Java开发手册》,具体可见第8部分的说明。
说明代码评审对象,分析结论清晰,有理有据。
使用的扫描工具是Alibaba Java Coding Guidelines,下载地址https://github.com/alibaba/p3c
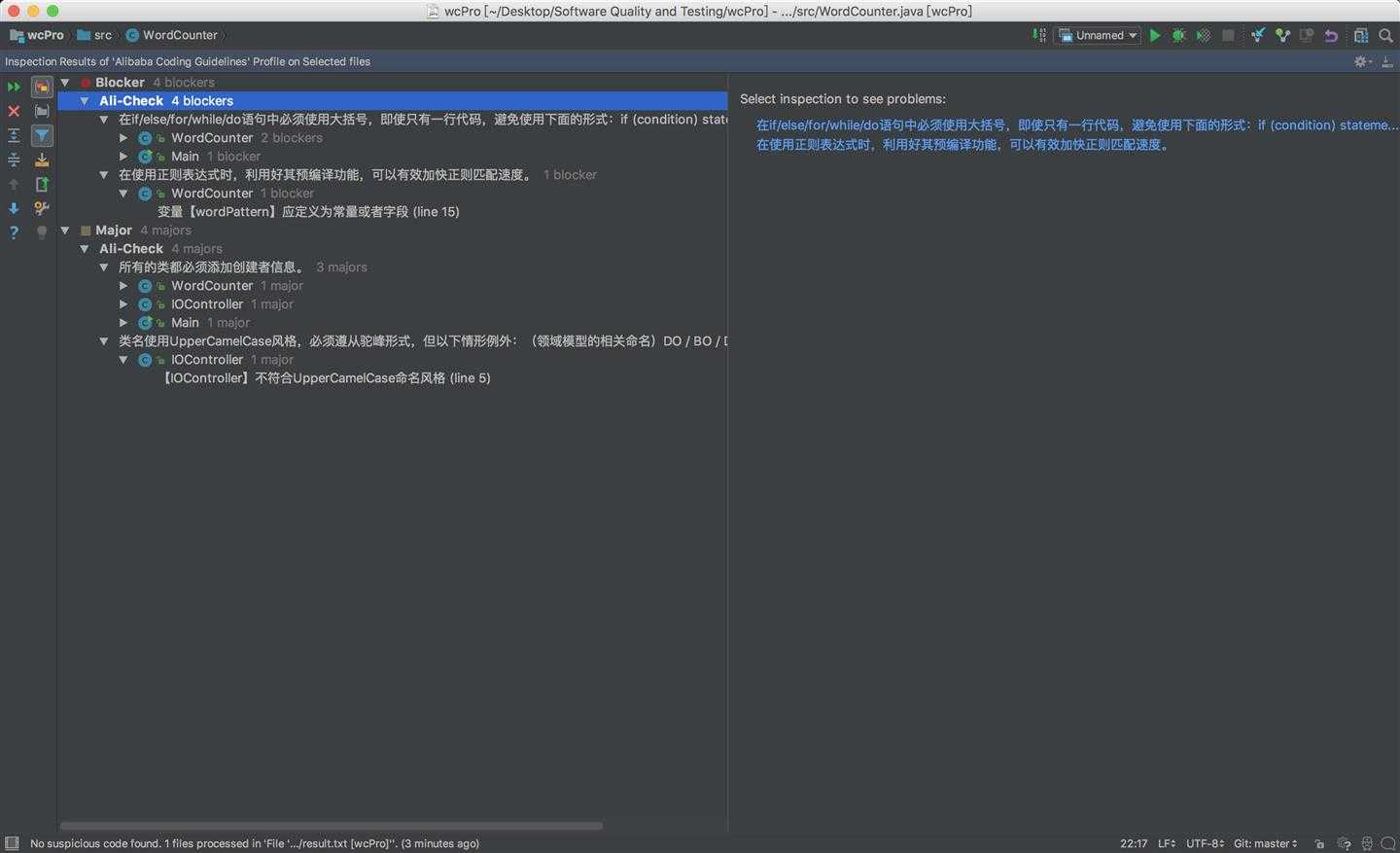
1.正则表达式的预编译问题
改进前的写法:
void countWord(String input)
{
...
Pattern wordPattern = Pattern.compile("[a-zA-Z]+(-[a-zA-Z]+)*-?");
Matcher m = wordPattern.matcher(input);
...
}这种写法存在的问题是:每调用一次countWord()函数,都会编译一次正则表达式,产生了很多不必要的开销。而且通过查阅资料,还了解到正则表达式需要使用预编译来提高效率。
改进后的写法:
public Class WordCounter
{
...
private static Pattern WORD_PATTERN = Pattern.compile("[a-zA-Z]+(-[a-zA-Z]+)*-?");
void countWord(String input)
{
...
Matcher m = WORD_PATTERN.matcher(input);
...
}
...
}2.if/else/while/do一行语句的大括号问题
大括号这种东西,从代码易读性,出bug的可能性,调试难易度上来说,都是需要加的。
不加大括号,代码修改的时候,如果需要在if语句中插入若干代码,则必须记着加上括号,忘掉则是bug;不加括号的话,设置断点比较麻烦,单步执行也不太容易看到是否执行到了if语句内部;加上绝对没有任何坏处,但是不加,就有可能造成问题(转载自知乎https://www.zhihu.com/question/37578053/answer/72753923来源:知乎著作权归作者所有)
所以我就直接按照规范进行了修改
3.所有的类都要添加创建者信息:也是话不多说,直接加上了。创建者信息无论是对于代码审查还是代码重构,都更容易将功能和开发者对应起来。
我们小组使用了big_case.txt文件进行性能测试,文件大小为24.8M,行数为8246行
以下是运行结果:
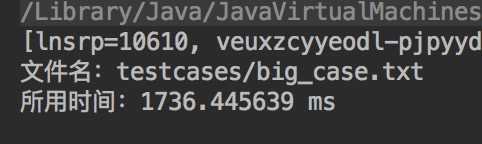
我们分析了之后觉得主要开销应该在两个方面
1.I/O时间
2.词频统计时间
对于这两个时间的权衡问题,我们进行了以下分析:
因为输出的文本量并不大,输出时间耗时影响很小,瓶颈应该是输入时间。我们采用了两种方法:第一种是将输入文本全部读入内存的字符数组中,并直接在字符数组中进行词频统计,这样的优点是I/O次数较少,缺点是内存占用量太大,而且在词频分析时开销也因数组规模太大而增大。第二种是每次只读一行,并对这一行进行词频统计,循环该步骤,直到读到文本的末尾,这种方法的优点是内存占用少,每次统计的开销较小,缺点是I/O次数较多,更新数据的次数也更多。我们尝试了两种方法并编码进行了对比,最终选择执行时间较少的第二种方法。
0.3
标签:line lib inf tin ... integer ima 正则 而且
原文地址:https://www.cnblogs.com/liuqianx/p/8748089.html