标签:流式 获取 状态 pip 分配 列表 png hdfs 汇报
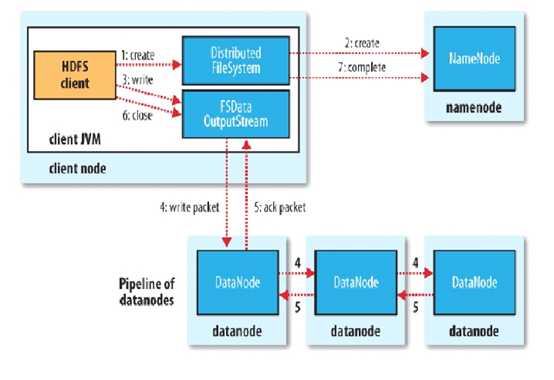
HDFS client首先会与NameNode交互元数据信息,然后NameNode制定策略,分配NameNode节点,客户端先会与离自己最近的DataNode进行socket连接,已经与DataNode建立连接的节点再与剩余节点之间进行连接构成pipeline,请注意,由于客户端只有一块网卡, HDFS客户端只与某一个DataNode连接,而非与所有的DataNode建立连接,当pipeline建立后,对于客户端来说,副本信息是透明的,并且不会因为副本数的数量多而影响传输速度,因为客户端只与其中一个DataNode传输。
Client会切分文件的Block块,按Block线性和NameNode获取DataNode列表(副本数),验证DataNode列表后以更小的单位流式传输数据,各个节点之间两两通信确定可用。
当前Block传输结束后,DataNode向NameNode汇报Block信息,DataNode向Client汇报完成,Client向NameNode汇报完成。然后获取下一个Block存放的DataNode列表,重复上述步骤,直到Client汇报完成。
最终,NameNode会在写流程更新文件状态。
标签:流式 获取 状态 pip 分配 列表 png hdfs 汇报
原文地址:https://www.cnblogs.com/7758521gorden/p/8862050.html