标签:code encoding 文档 from off html gen cloud pre
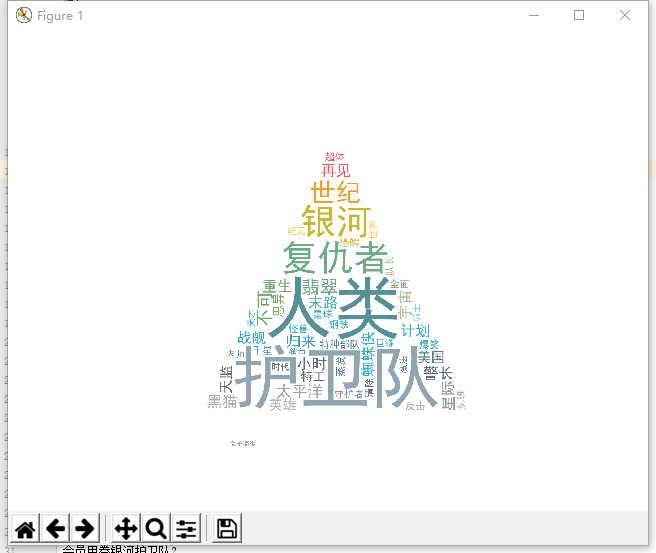
import jieba.analyse from PIL import Image,ImageSequence import numpy as np import matplotlib.pyplot as plt from wordcloud import WordCloud,ImageColorGenerator import requests from urllib import parse from bs4 import BeautifulSoup def getWord(): lyric = ‘‘ # 打开文档,进行编译,防止错误 f = open(‘youku.txt‘, ‘r‘, encoding=‘utf-8‘) # 将文档里面的数据进行单个读取,便于生成词云 for i in f: lyric += f.read() # 进行分析 result = jieba.analyse.textrank(lyric, topK=50, withWeight=True) keywords = dict() for i in result: keywords[i[0]] = i[1] print(keywords) # 获取词云生成所需要的模板图片 image = Image.open(‘789.jpg‘) graph = np.array(image) # 进行词云的设置 wc = WordCloud(font_path=‘./fonts/simhei.ttf‘, background_color=‘White‘, max_words=50, mask=graph) wc.generate_from_frequencies(keywords) image_color = ImageColorGenerator(graph) plt.imshow(wc) plt.imshow(wc.recolor(color_func=image_color)) plt.axis("off") plt.show() wc.to_file(‘dream.png‘) name = ‘youku‘ unique = parse.quote(name) print(unique) url = ‘http://list.youku.com/category/show/c_96_g_%E7%A7%91%E5%B9%BB_s_1_d_1.html?spm=a2hmv.20009921.m_86982.5~5~5!3~1~3!5~A‘ print(url) res = requests.get(url) res.encoding = ‘utf-8‘ soup = BeautifulSoup(res.text, ‘html.parser‘) titles = soup.select(".info-list .title a") for i in range(0,len(titles)): title = titles[i].text f = open(‘youku.txt‘, ‘a‘, encoding=‘utf-8‘) f.write(title) f.write("\n") f.close() # print(title) getWord()

标签:code encoding 文档 from off html gen cloud pre
原文地址:https://www.cnblogs.com/darkhate/p/8922674.html