标签:generate pat 数字 elf 单元格 ict 写入 otl for
通过爬游侠网的游戏资讯页面,获取新闻标题和作者,并对作者进行统计,网站
http://www.ali213.net/news/game/
首先是要对网站发送请求
下面是我的代码
from urllib.parse import quote
import string
class HtmlDownloader(object):
def download(self, url):
if url is None:
return None
s = quote(url, safe=string.printable) # url里有中文需要添加这一句,不然乱码
response = urllib.request.urlopen(s)
if response.getcode() != 200:
return None
return response.read() # 返回内容
接着是要解析并得到目标URL,通过管理器进行操作,代码如下
# -*- coding:utf8 -*-
class UrlManage(object):
def __init__(self):
self.detail_urls = set() # 详细内容页的URL
self.old_detail_urls = set() # 已经爬取过的url
def add_detail_url(self, url):
if url is None:
return
if url not in self.detail_urls and url not in self.old_detail_urls:
self.detail_urls.add(url)
# print(self.detail_urls)
# 添加多个url
def add_new_detail_urls(self, urls):
if urls is None or len(urls) == 0:
return
for url in urls:
self.add_detail_url(url)
def has_new_detail_url(self):
return len(self.detail_urls) != 0
def get_detail_url(self):
new_detail_url = self.detail_urls.pop()
self.old_detail_urls.add(new_detail_url)
return new_detail_url
观察游侠网游戏资讯的结构(如以下图片所示),构造相应的解析器

第三页和第五页的差距只是index_后的数字差别,以此类推
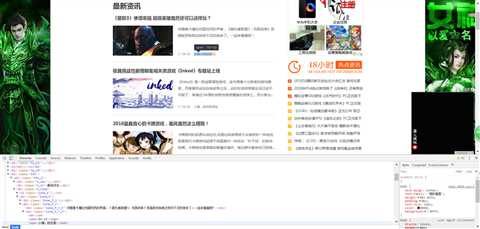
需要注意的是 这里的第三条信息是广告来的,我的方法是通过计数器来跳过这个广告
# -*- coding:utf8 -*-
import re
from urllib.parse import urlparse
from bs4 import BeautifulSoup
class HtmlParser(object):
def soup(cont):
soups = BeautifulSoup(cont, ‘html.parser‘, from_encoding=‘utf-8‘)
return soups
# 得到具体的data数据
def get_new_data(soup):
dict = {}
count = 0
if (soup.select(‘.t5c_l‘)[0].contents):
li = soup.select(‘.t5c_l‘)[0].select(‘.n_lone‘)
di = {}
for i in li:
if(count==2):
print(‘我是广告‘)
count=count+1
continue
moviename = i.select(‘h2‘)[0].select(‘a‘)[0].attrs[‘title‘] # 游戏名
print(moviename)
comment = i.select(‘.lone_f‘)[0].select(‘.lone_f_r‘)[0].select(‘.lone_f_r_f‘)[0].text
comment=comment.lstrip()
comment=comment[9:].lstrip()
# comment = re.findall(‘\d+‘, comment)[0]
# gametype=i.select(‘.tag2‘)[0].select(‘.a‘)[0].attrs[‘title‘]
di[moviename] = comment
print(moviename,di[moviename])
count=count+1
# di[‘gametype‘]=gametype
if di: # 返回的字典不为空的时候
dict.update(di)
return dict
# 得到详细内容的url
def get_detail_url(base_url):
detail_urls = set()
for k in range(1, 201):
if (k == 1):
urls = base_url
# print(urls)
else:
urls = base_url + ‘index_{}.html‘.format(k)
# print(urls)
detail_urls.add(urls)
return detail_urls
把爬到的数据存为Excel格式
# -*- coding:utf8 -*-
import xlwt # 写入Excel表的库
class HtmlOutputer(object):
def __init__(self):
self.datas = []
def output_excel(self, dict):
di = dict
wbk = xlwt.Workbook(encoding=‘utf-8‘)
sheet = wbk.add_sheet("wordCount") # Excel单元格名字
k = 0
for i in di.items():
sheet.write(k, 0, label=i[0])
sheet.write(k, 1, label=i[1])
k = k + 1
wbk.save(‘wordCount.xls‘) # 保存为 wordCount.xls文件
编写主类,代码如下
# -*- coding:utf8 -*-
from dazuoye import url_manager, html_downloader, html_parser, html_outputer
class SpiderMain(object):
def __init__(self):
self.urls = url_manager.UrlManage()
self.downloader = html_downloader.HtmlDownloader()
self.htmlparser = html_parser.HtmlParser
self.outputer = html_outputer.HtmlOutputer()
def craw(self, root_url):
count = 1
dictdata = {}
try:
detail_urls = self.htmlparser.get_detail_url(root_url)
self.urls.add_new_detail_urls(detail_urls)
except:
print(‘craw failed‘)
while self.urls.has_new_detail_url():
try:
detail_url = self.urls.get_detail_url()
print(‘crow %d : %s‘ % (count, detail_url))
html_cont = self.downloader.download(detail_url)
soup = self.htmlparser.soup(html_cont)
dict = self.htmlparser.get_new_data(soup)
dictdata.update(dict)
if count == 200:
break
count = count + 1
except:
print(‘craw failed‘)
self.outputer.output_excel(dictdata)
# 程序入口
if __name__ == "__main__":
url = ‘http://www.ali213.net/news/game/‘
obj_spider = SpiderMain()
obj_spider.craw(url)
运行主类,结果如下
然后再把作者存进列表,再通过字典统计词频,最后生成词云
# -*- coding:utf8 -*-
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import xlrd
from PIL import Image, ImageSequence
import numpy as np
file = xlrd.open_workbook(‘wordCount.xls‘)
sheet = file.sheet_by_name(‘wordCount‘)
list_li=[]
for i in range(sheet.nrows):
rows = sheet.row_values(i)
list_li.append(rows[1].rstrip(‘\n‘))
list_di={}
for i in list_li:
if list_li.count(i)>1:
list_di[i]=list_li.count(i)
print(list_di)
image = Image.open(‘./005.jpg‘)
graph = np.array(image)
wc = WordCloud(font_path=‘./fonts/simhei.ttf‘, background_color=‘white‘, max_words=50, max_font_size=100,
min_font_size=10,mask=graph,random_state=10)
wc.generate_from_frequencies(list_di)
plt.figure()
# 以下代码显示图片
plt.imshow(wc)
plt.axis("off")
plt.show()


如图所示(哈哈哈哈哈哈哈)
说说码代码的时候遇到的问题吧
就是解析数据的那里,因为有广告,所以经常报错,试过通过判断标签获得的数据是否为空来跳过此次循环 不过还是不行 最后另辟蹊跷,设计了一个计数器,当计数为2(即第三条)时跳过此次循环,
说起来也是因为网站固定第三条为广告,才能这样做的。
还有一个就是读取Excel转化为字典那里,本来想通过jieba的,不过发现我的方法更简单后就这样弄了
总的来说 此次大作业令我对Python兴趣大增,致使我觉得Python是世界上最好的语言!
标签:generate pat 数字 elf 单元格 ict 写入 otl for
原文地址:https://www.cnblogs.com/xjh602545141/p/8964983.html