标签:hit write url 问题 数据 war 字体 art dcl
1.选一个自己感兴趣的主题(所有人不能雷同)。
每天都有接触各大平台推送的新闻,了解到了校园外的大小事。故此,对新浪新闻标题的关键字的爬取,看看最近发生的实时,也想比较下标题党还是和实际内容的差异。
2.用python 编写爬虫程序,从网络上爬取相关主题的数据。
3.对爬了的数据进行文本分析,生成词云。
4.对文本分析结果进行解释说明。
5.写一篇完整的博客,描述上述实现过程、遇到的问题及解决办法、数据分析思想及结论。
6.最后提交爬取的全部数据、爬虫及数据分析源代码。
实现代码:
import jieba import requests from bs4 import BeautifulSoup url = ‘http://news.sina.com.cn/china/‘ res = requests.get(url) # 使用UTF-8编码 res.encoding = ‘UTF-8‘ # 使用剖析器为html.parser soup = BeautifulSoup(res.text, ‘html.parser‘) #遍历每一个class=news-item的节点 for news in soup.select(‘.news-item‘): h2 = news.select(‘h2‘) #只选择长度大于0的结果 if len(h2) > 0: #新闻时间 time = news.select(‘.time‘)[0].text #新闻标题 title = h2[0].text #新闻链接 href = h2[0].select(‘a‘)[0][‘href‘] #打印 print(time, title, href) f = open(‘news.txt‘, ‘a‘, encoding=‘utf-8‘) f.write(title) f.close() def changeTitleToDict(): f = open("news.txt", "r", encoding=‘utf-8‘) str = f.read() stringList = list(jieba.cut(str)) notWord = {":", "“","”","“”","?","+", ".", "_", "/", "(", ")", "..", "(", ")", "【", "】", ", ", " ", ":", ";", "!", "、", "论文", "-", "D", "—", "[", "]", "了","不","的", "与", "及", "之", "中", "在", "和"} stringSet = set(stringList) - notWord title_dict = {} for i in stringSet: title_dict[i] = stringList.count(i) # print(title_dict) return title_dict # 统计前50出现的词语排序,保存在wordcound.txt title_dict = changeTitleToDict() dictList = list(title_dict.items()) dictList.sort(key=lambda x: x[1], reverse=True) f = open(‘word.txt‘, ‘a‘, encoding=‘utf-8‘) for i in range(50): print(dictList[i]) f.write(dictList[i][0] + ‘ ‘ + str(dictList[i][1]) + ‘\n‘) f.close() # 生成词云 from PIL import Image, ImageSequence import numpy as np import matplotlib.pyplot as plt from wordcloud import WordCloud, ImageColorGenerator font = r‘C:\Windows\Fonts\simhei.TTF‘ # 引入字体 title_dict = changeTitleToDict() # 读取背景图片 image = Image.open(‘./002.jpg‘) graph = np.array(image) wc = WordCloud(font_path=font, # 设置字体 background_color=‘White‘, mask=graph, # 设置背景图片 max_words=200) wc.generate_from_frequencies(title_dict) image_color = ImageColorGenerator(graph) # 绘制词云图 plt.imshow(wc) plt.axis("off") plt.show()
所用背景图:

生成云图:

总结:
遇到的问题:
1.安装wordcloud库出错
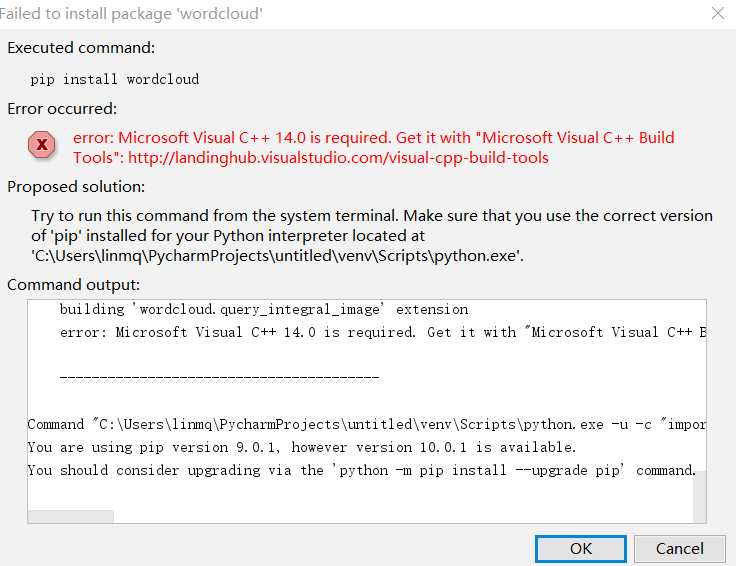
cmd终端中,运用命令pip install wordcloud 找不到pip命令

解决方法是:
找小伙伴帮助再结合百度后,在网站https://www.lfd.uci.edu/~gohlke/pythonlibs/#wordcloud下载对应版本的whl文件,
然后找对pip相应路径,在终端上进行安装就可以了。

2.由于每个网站的网页结构不一样,在找存放需要的class文件路径花了很长时间去理解。
3.可能借鉴小伙伴代码缘故,当程序运行时,会一直一直生成云图。
最后,综述:遇上问题不少,解决起来还是困难压抑。基础过分薄弱,日后勤加练习和认真听课吧!
嗯!就这样。
标签:hit write url 问题 数据 war 字体 art dcl
原文地址:https://www.cnblogs.com/lmq757036131/p/8973639.html