标签:his 最新 虚拟机 set short zoo.cfg 安装路径 org com
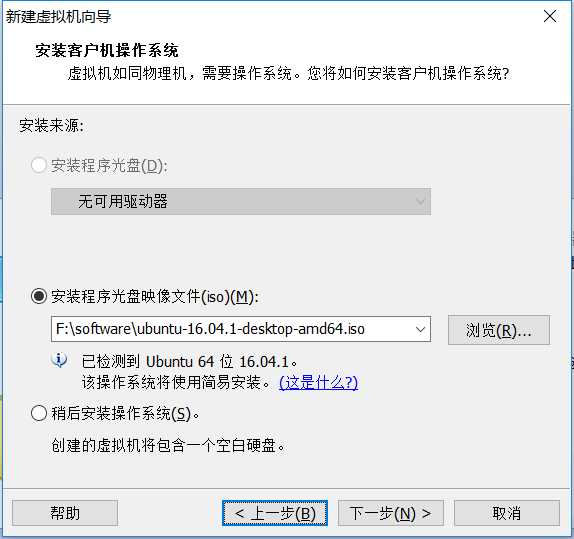
(1) 安装vim
yum install vim
(2) 更改hostname为hadoop_master
sudo vim /etc/hostname
(3) 关闭防火墙
sudo ufw disable
(4) 安装rz sz用于服务器文件与本地文件交互
apt-get install lrzsz
(5) 安装 vm tools
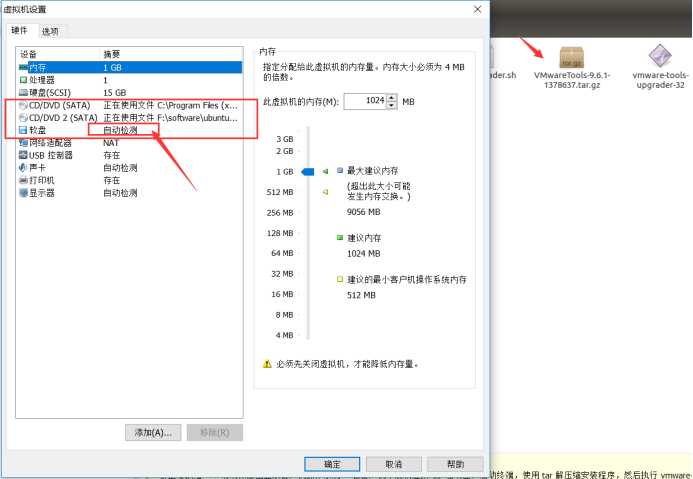
(6) 将 tar.gz 包复制到其他目录,解压后,

1 Java下载的jdk包放到root用户下的 /usr/local/java下
解压包tar xvf jdk1.8.*
2 配置JAVA环境变量
(1) Root用户权限下,在 /etc/profile.d 文件夹下创建java.sh
(2) 在java.sh里写入以下内容,保存后用 source java.sh 刷新配置文件是配置文件生效:
注:很多网上资料是说在 /etc/profile 文件里直接加以下设置,但比较新的Ubuntu版本里,系统会先读 profile 文件,然后由 profile 文件遍历 profile.d 文件夹下所有 *.sh 文件, 这样就比把所有配置都写在一个 profile 文件里容易管理。

(3) 上一步是在root 下配置,接下来在 Hadoop 用户下将环境变量写入 ~/.bashrc 里,同样,保存后用 source ~/.bashrc刷新。
注:每个用户根目录有独立的 ~/.bashrc 文件
如果还不成功,可以root账号下试试以下命令:
执行赋权语句即可:
chmod 777 /etc/java/jdk1.8
备注:chmod是赋权限命令,777表示赋值所有权限对本用户,本组用户、其他用户。
设置完成后,可以用 java –version 测试是否成功。
sudo apt-get install openssh-server
测试:ssh localhost
此时,要输入密码,还要按一次确认 yes
(1),避免输入密码
ssh-keygen -t rsa
一路回车,最后在 home/hadoop/.ssh 下有两个文件

运行:cat id_rsa.pub >> authorized_keys
这样就可以避免输入密码了。等克隆玩从机,使用同样的操作,并且将主机的 id_rsa.pub 追加到从机的 authorized_keys 中,这样,主机可以无密码访问从机了。
(2) 避免需要输入yes
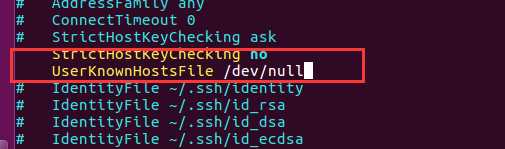
在文件 /etc/ssh/ssh_config 添加以下两行
StrictHostKeyChecking no
UserKnownHostsFile /dev/null
sudo apt-get install rsync
因为之前更新了Ubuntu系统,已经是最新的了

修改网卡
原先的ip信息
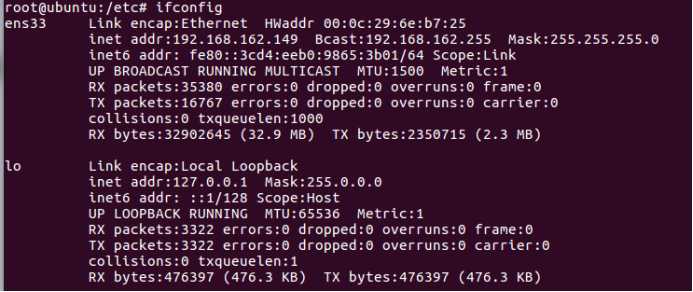
查看host信息

键入命令:
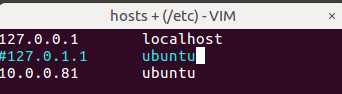
vi hosts
注释掉 127.0.1.1 ubuntu
新增一行 10.0.0.81 ubuntu
(这里必须改,否则后面会遇到连接拒绝问题)
添加一个hadoop组
sudo addgroup hadoop
将当前用户hadoop 加入到Hadoop组
sudo usermod -a -G hadoop hadoop
将hadoop组加入到sudoer
sudo vi etc/sudoers
在root ALL=(ALL) ALL后 hadoop ALL=(ALL) ALL
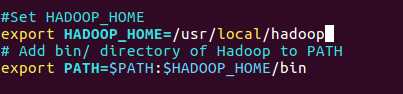
(1) 修改 ~/.bashrc 文件
添加以下这些行到 ~/.bashrc 文件的末尾,内容如下所示:
#Set HADOOP_HOME
export HADOOP_HOME=/usr/local/hadoop
# Add bin/ directory of Hadoop to PATH
export PATH=$PATH:$HADOOP_HOME/bin
(2) 配置关联HDFS
设置 JAVA_HOME 在文件 /usr/local/hadoop/etc/hadoop/hadoop-env.sh 中,使用以下行代替,即写上完整的 Java 安装路径。如下所示:

(3) core-site.xml 配置
在 $HADOOP_HOME/etc/hadoop/core-site.xml 文件中还有两个参数需要设置:
1. ‘hadoop.tmp.dir‘ - 用于指定目录让 Hadoop 来存储其数据文件。
2. ‘fs.default.name‘ - 指定默认的文件系统
为了设置两个参数,打开文件 core-site.xml
<configuration> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop/dfs/tmp</value> <description>Parent directory for other temporary directories.</description> </property> <property> <name>fs.defaultFS </name> <value>hdfs://master:9000</value> <description>The name of the default file system. </description> </property> </configuration>
现在创建一个目录,如上面配置 core-site.xml 中使用的目录:/usr/local/hadoop/dfs/tmp
sudo mkdir -p /usr/local/hadoop/dfs/tmp
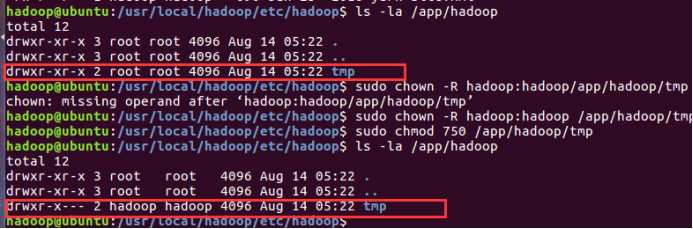
授予权限目录 /app/hadoop/tmp,执行如下的命令:
sudo chown -R hadoop:hadoop /usr/local/hadoop/dfs/tmp
sudo chmod 750 /usr/local/hadoop/dfs/tmp
(4) Map Reduce 配置
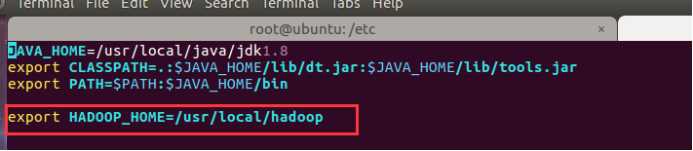
在设置这个配置之前, 我们需要设置 HADOOP_HOME 的路径,执行以下命令:
sudo vi /etc/profile.d/hadoop.sh
然后输入以下一行,
export HADOOP_HOME=/usr/local/hadoop
再执行以下命令:
hadoop@ubuntu: sudo chmod +x /etc/profile.d/hadoop.sh
退出命令行终端再次进入,并输入以下命令:echo $HADOOP_HOME 以验证 hadoop 的路径:
hadoop@ubuntu: echo $HADOOP_HOME
/usr/local/hadoop
现在复制文件,执行以下命令:
sudo cp $HADOOP_HOME/etc/hadoop/mapred-site.xml.template $HADOOP_HOME/etc/hadoop/mapred-site.xml
使用vi 打开文件 mapred-site.xml
sudo vi $HADOOP_HOME/etc/hadoop/mapred-site.xml
添加以下的设置内容到标签<configuration> 和 </configuration> 中,如下图所示:
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property> </configuration>
hdfs-site.xml配置
打开 $HADOOP_HOME/etc/hadoop/hdfs-site.xml 文件如下:
sudo vi $HADOOP_HOME/etc/hadoop/hdfs-site.xml
添加以下的设置内容到标签<configuration> 和 </configuration> 中,如下图所示:
<configuration> <property> <name>dfs.namenode.name.dir</name> <value>/usr/local/hadoop/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/usr/local/hadoop/dfs/data</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>master:9001</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> </configuration>
创建以上配置指定的目录并授权目录给用户,使用以下命令:
sudo mkdir -p /usr/local/hadoop/dfs/name sudo mkdir -p /usr/local/hadoop/dfs/data sudo chown -R hadoop:hadoop /usr/local/hadoop/dfs/name sudo chown -R hadoop:hadoop /usr/local/hadoop/dfs/data sudo chmod 750 /usr/local/hadoop/dfs/name sudo chmod 750 /usr/local/hadoop/dfs/data
(5) 格式化HDFS
在第一使用 Hadoop 之前,需要先格式化 HDFS,使用下面的命令
hadoop namenode -format
输入:y,继往下..
(6) 启动/停止 Hadoop 的单节点集群
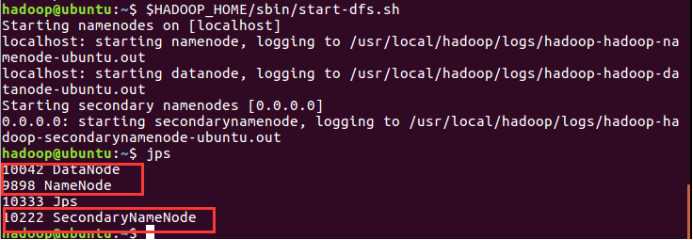
$HADOOP_HOME/sbin/start-dfs.sh
$HADOOP_HOME/sbin/start-yarn.sh
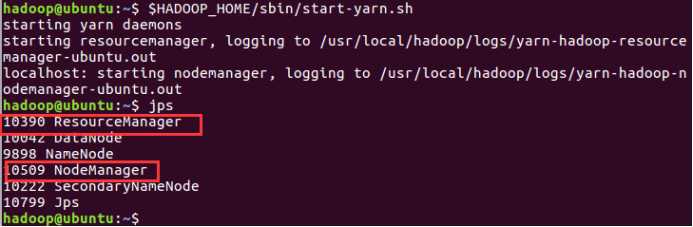
现在使用 ‘jps‘ 工具/命令, 验证是否所有 Hadoop 相关的进程正在运行。
如果 Hadoop 成功启动,那么 jps 输出应显示: NameNode, NodeManager, ResourceManager, SecondaryNameNode, DataNode.
停止 Hadoop 的单节点集群
$HADOOP_HOME/sbin/stop-dfs.sh $HADOOP_HOME/sbin/stop-yarn.sh
或
$HADOOP_HOME/sbin/stop-all.sh
上述步骤只是安装测试虚拟机使用,实际生产环境中,这几个配置文件都还要根据实际需求做很多调优设置。特别是cpu,内存,日志路径等等都需要调
前三步是single模式的环境,接下来是做完全分布式环境,添加从机。
*原本是直接在复制粘贴两份虚拟机作为slave1和slave2,但后来发现不能上网,会出现连不上网络的问题,用克隆出来的虚拟机可以避免这个问题。
VMware ==》 虚拟机 ==》 管理 ==》 克隆
克隆出 Hadoop_slave1 Hadoop_slave2
修改 etc/hostname ,分别将ubuntu 改为 master , slave1, slave2
*千万别设置成有下划线格式的如: hadoop_master ,会导致启动namenode时出错。

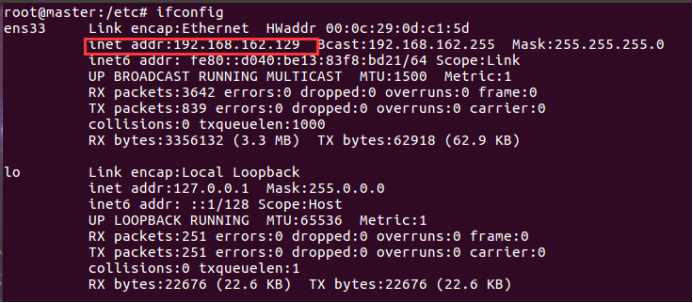
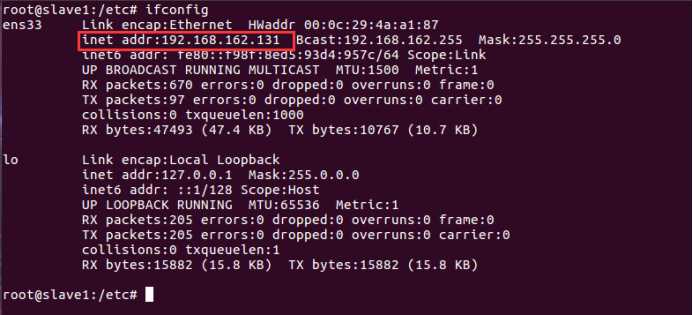
通过命令 ifconfig 查看三个虚拟机的ip4 地址
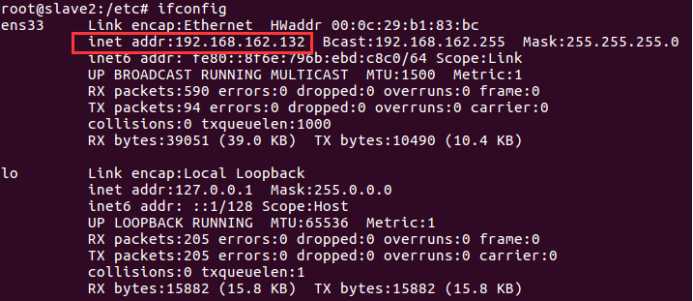
然后在三个虚拟机里都添加三行ip hostname映射,如下:
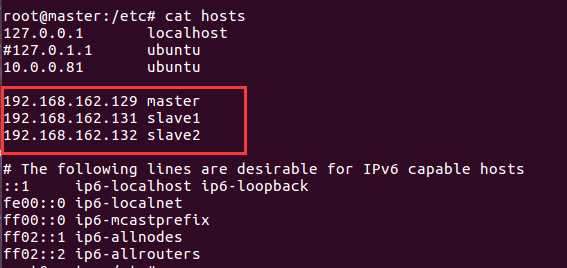
添加完后,三个虚拟机就可以互相用hostname Ping通了,
master机ping slave2结果:

无密码登陆,效果也就是在master上通过 ssh slave1或 ssh slave2 就可以登陆到对方计算机上。而且不用输入密码。
3台虚拟机上,使用 ssh-keygen -t rsa 一路按回车就行了。
刚才都作甚了呢?主要是设置ssh的密钥和密钥的存放路径。 路径为~/.ssh下。
打开~/.ssh 下面有三个文件,输入命令 ls -la
authorized_keys,已认证的keys
id_rsa,私钥
id_rsa.pub,公钥 三个文件。
下面就是关键的地方了,(我们要做ssh认证。进行下面操作前,可以先搜关于认证和加密区别以及各自的过程。)
(1)在master上将公钥放到authorized_keys 里。命令:sudo cat id_rsa.pub >> authorized_keys,在slave机上也同样操作,这一步使本机可以无密码操作。
(2) 将master上的authorized_keys放到其他linux的~/.ssh目录下。
sudo scp authorized_keys hadoop@slave1:~/.ssh
sudo scp authorized_keys hadoop@slave2:~/.ssh
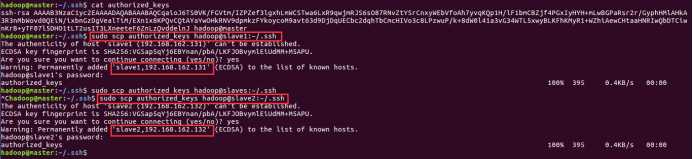
sudo scp authorized_keys 远程主机用户名@远程主机名或ip:存放路径。

slave机上,一个master的,一个本机的
master机上,只有master的
(3)修改authorized_keys权限,命令:chmod 644 authorized_keys
(4)测试是否成功
ssh slave1输入用户名密码,然后重启master虚拟机,再次ssh slave1不用密码,直接进入系统。这就表示成功了。
配置/usr/local/hadoop/etc/hadoop目录下的slaves
删除默认的localhost,增加2从节点,
192.168.159.132
192.168.159.133
http://192.168.159.129:50070/dfshealth.html#tab-datanode
http://192.168.159.130:8088/cluster/scheduler
集群上个服务器时间上可能不同步,这会导致很多麻烦事,要同步集群时间。
(未装成功,先跳过,但是Hbase对时间同步有要求)
(1)安装ntpdate工具
sudo apt-get install ntpdate
(2)设置系统时间与网络时间同步
sudo ntpdate cn.pool.ntp.org
(3)将系统时间写入硬件时间
sudo hwclock --systohc
安装lrzsz,使用rz或sz命令可以方便地上传和下载文件

下载地址:
http://pan.baidu.com/s/1qWyoFhU?errno=0&errmsg=Auth%20Login%20Sucess&&bduss=&ssnerror=0
执行:
解压后
sudo mv zookeeper-3.4.5.tar.gz /usr/local/zookeeper
cd /usr/local/zookeeper/conf
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
修改:dataDir=/usr/local/zookeeper/data
添加:
server.0=master:2888:3888
server.1=slave1:2888:3888
server.2=slave2:2888:3888
创建/usr/local/zookeeper/data 文件夹,并创建myid文件
并设置第一台server为0
echo 0 > myid
复制zookeeper目录至其余两台服务器中:
scp -r /usr/local/zookeeper slave1:/usr/local/
scp –r /usr/local/zookeeper slave2:/usr/local/
scp –r /usr/local/zookeeper slave3:/usr/local/
如果没权限,就先复制到 /tmp 文件夹,然后在 mv 到/usr/local
或者修改 /usr/local 权限,添加写权限
复制环境变量配置文件至其余两台服务器中:
scp /etc/profile.d/zookeeper.sh hadoop@slave1:/etc
scp /etc/profile.d/zookeeper.sh hadoop@slave2:/etc
scp /etc/profile.d/zookeeper.sh hadoop@slave3:/etc
在其余几台服务器中修改myid文件:设置为1和2,3;
启动ZooKeeper,分别在每个节点中执行命令:zkServer.sh start

查看状态 /usr/local/zookeeper/bin/zkServer.sh status



(11)可以使用以下命令来连接一个zk集群:
/usr/local/zookeeper/bin/zkCli.sh -server master:2181,slave1:2181,slave2:2181,slave3:2181

标签:his 最新 虚拟机 set short zoo.cfg 安装路径 org com
原文地址:https://www.cnblogs.com/zjc10203/p/9064927.html