标签:pipeline 网络 ted span pip sch schedule dde 一个
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。
其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy 使用了 Twisted异步网络库来处理网络通讯。整体架构大致如下
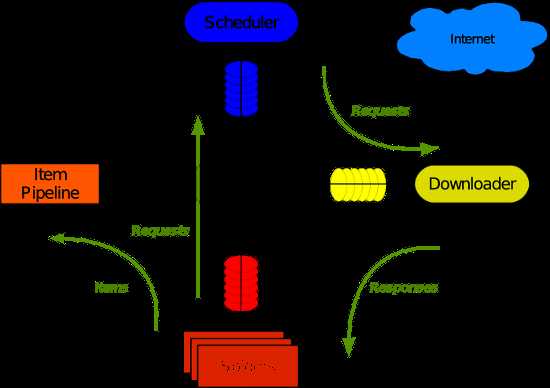
Scrapy主要包括了以下组件:
Scrapy运行流程大概如下:
解析出实体(Item),则交给实体管道进行进一步的处理
解析出的是链接(URL),则把URL交给调度器等待抓取
安装
Linux pip3 install scrapy Windows a. pip3 install wheel b. 下载twisted http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted c. 进入下载目录,执行 pip3 install Twisted?17.1.0?cp35?cp35m?win_amd64.whl d. pip3 install scrapy e. 下载并安装pywin32:https://sourceforge.net/projects/pywin32/files/
标签:pipeline 网络 ted span pip sch schedule dde 一个
原文地址:https://www.cnblogs.com/chengrongfu/p/9072911.html