标签:contex seq 结构 没有 分享图片 公式 影响 encode 基础上
一、什么是seq2seq模型
seq2seq全称为:sequence to sequence ,是2014年被提出来的一种Encoder-Decoder结构。其中Encoder是一个RNN结构(LSTM、GRU、RNN等)。
主要思想是输入一个序列,通过encoder编码成一个语义向量c(context),然后decoder成输出序列。这个结构重要的地方在于输入序列和输出序列的长度是可变的。
应用场景:机器翻译、聊天机器人、文档摘要、图片描述等
二、Encoder-Decoder结构
最初Encoder-Decoder模型由两个RNN组成
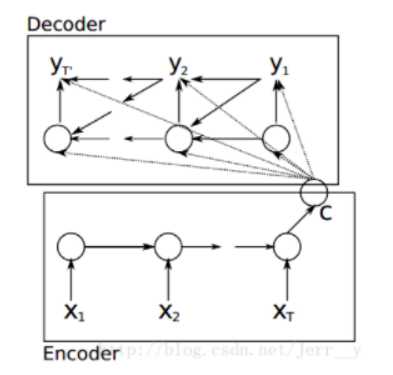
这个结构可以看到,输入一个句子后,生成语义向量c,编码过程比较简单;
解码时,每个c、上一时刻的yi-1,以及上一时刻的隐藏层状态si-1都会作用到cell,然后生成解码向量。
三、常用的四种seq2seq结构
对于上面模型中的编码模型,是一种比较常用的方式,将编码模型最后一个时刻的隐层状态做为整个序列的编码表示,但是实际应用中这种效果并不太好。
因此,对于常用的模型中,通常直接采用了整个序列隐层编码进行求和平均的方式得到序列的编码向量。因此通常有四种模式:
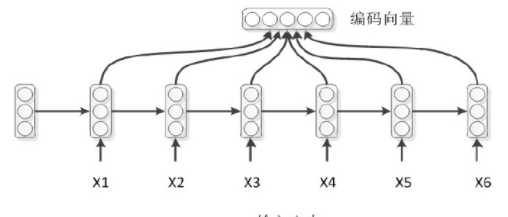
对于解码模式:
普通作弊模式
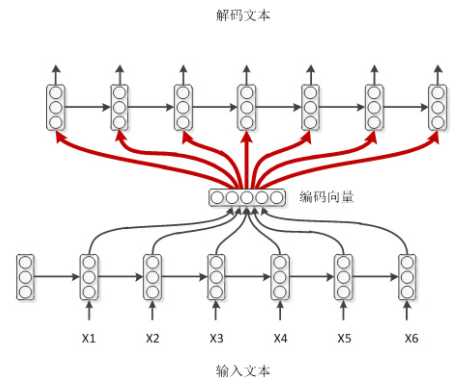
如上,编码时,RNN的每个时刻除了上一时刻的隐层状态,还有输入字符,而解码器没有这种字符输入,用context作为输入,即为一种比较简单的模式。
学霸模式
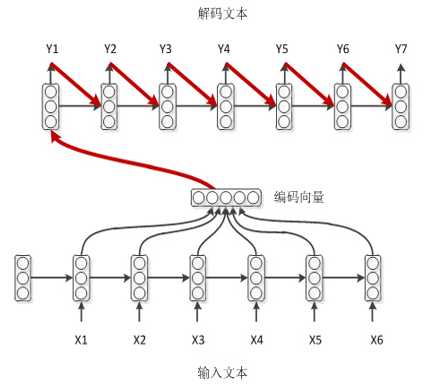
如上是一种带输出回馈的方式。输入即为上一时刻的输出。
学弱模式
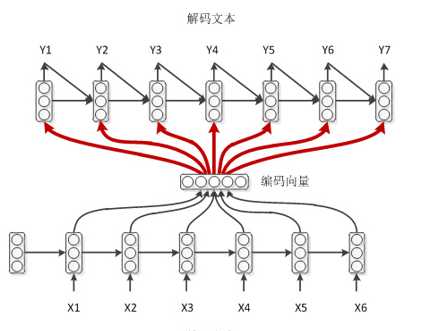
学渣作弊模式
学渣作弊模式就是在学弱的基础上在引入Attention机制,加强对于编码输入的特征的影响。
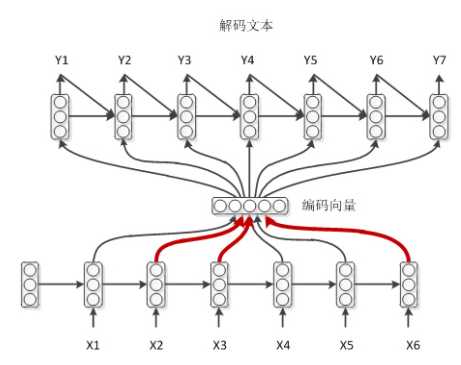
下面主要梳理带attention机制的seq2seq模型:
四、带attention的seq2seq
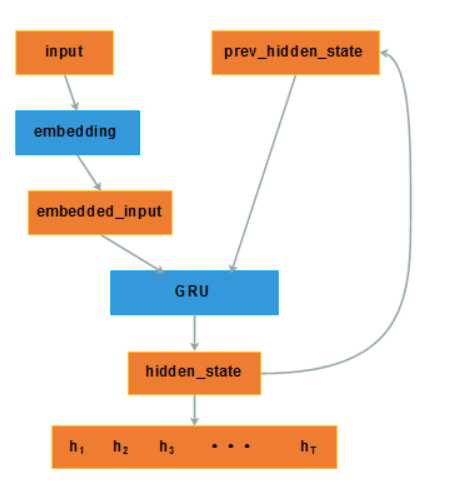
编码器如上,公式不再赘述。
注意:对于使用双向的GRU编码时,得到的两个方向上的hi,通常进行contact作为输入。
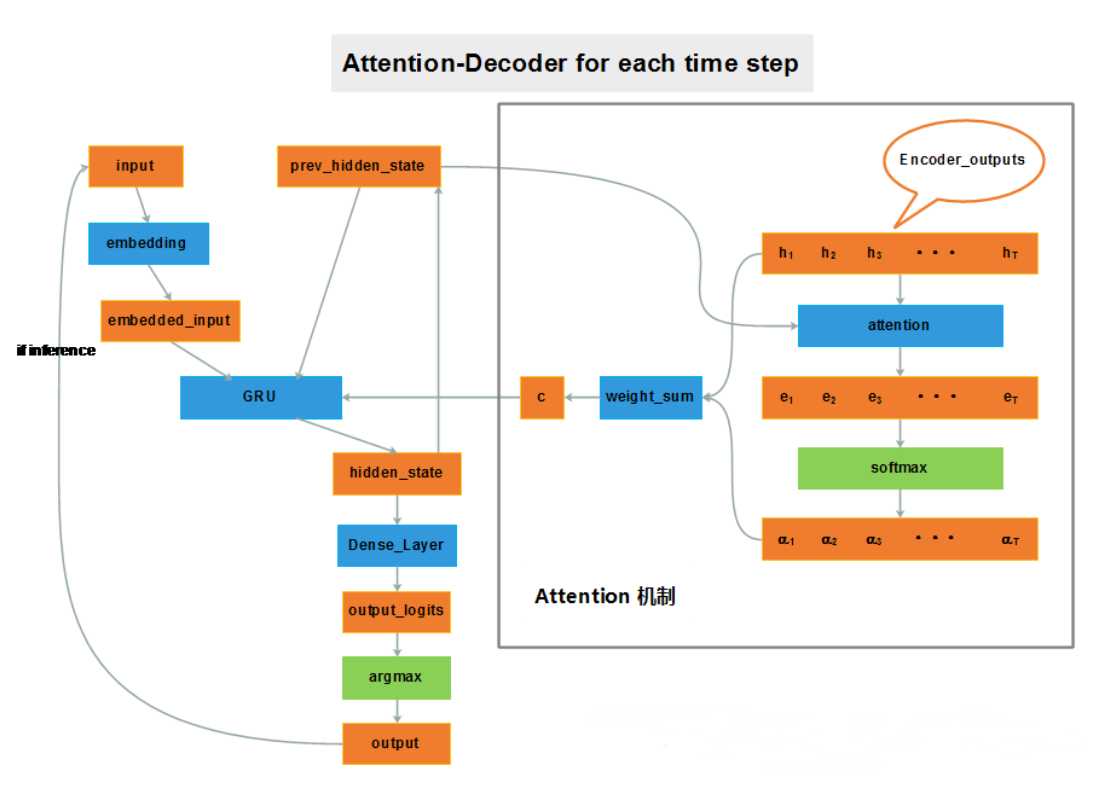
对于解码的过程,可以看到,在语义向量C的求解的过程中,添加了attention。
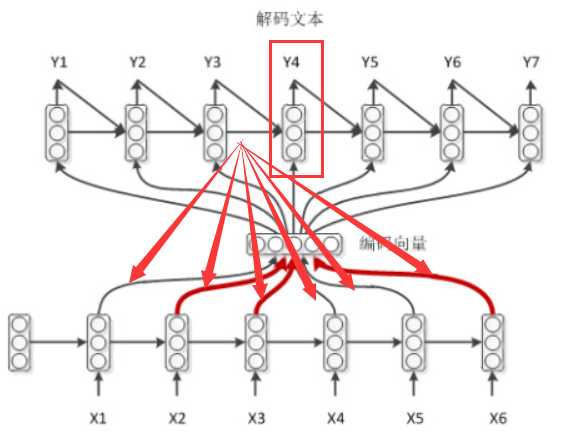
如上,当计算Y4时,上一时刻解码的隐层状态会作用于编码器的输入,这样会从新计算context,过程就是这样的,公式不在赘述。
标签:contex seq 结构 没有 分享图片 公式 影响 encode 基础上
原文地址:https://www.cnblogs.com/pinking/p/9092594.html