标签:ane work ebe mem int learn mil bvs lsp
Title:《视觉显著性预测综述》---孙夏
本文针对视觉显著性预测这一热点问题,通过介绍和对比了基于认知型,基于图论模型、基于频谱模型、和基于模式识别模型等视觉显著性预测算法的优缺点,得出基于模式识别模型在现有数据库效果的最好结论。同时,本文探究了已有的数据库特色以及适用范围。 除此之外,本文分析了Auc、NSS 和 EMD 等性能评估方法对于评估各种视觉显著性预测算法性能的优势和劣势 。文章最后针对已有视觉显著性预测方法和数据库的问题,对现有的视觉显著性预测方面的研究做了总结和展望。
1 视觉显著性预测
鉴于许多研究者经常混淆视觉显著性预测与显著性物体检测这两个概念,本文将简单地阐述视觉显著性预测与显著性物体检测的异同:
视觉显著性预测,即预测人类的视觉凝视点和眼动;
显著性物体检测,是基于视觉显著性在图像大小调整上的应用而得来的概念。
1)两者的标准集的定义不同
觉显著性预测只需预测出人类在 3~5 秒的凝视中所关注的点;显著性物体检测的目标是检测出最显著的物体。 其中显著性物体作为一个整体被检测出来,需要精确到像素级别;理论上,在显著性预测模型上成功的方法在显著性物体检测的标准中会失败。
2) 两者的评估标准不同
视觉显著性预测的评估方法需要评估显著性图的相似程度,而显著性物体检测方法需要基于显著性物体区域中每个像素点的命中率来计算准确率和回召率。

2 常用的视觉显著性预测方法
2.1 认知模型
几乎所有的显著性模型都直接或间接地受认知模型启发而来。 认知模型的一大特点是与心理学和神经学有着十分紧密的关联。从心理学特征出发,Itti的基本模型使用了三个特征通道,颜色,属性,方向。模型通过对这三个特征图加权形成最终的显著性图。 这一模型是后来需要衍生模型的基础。 同时,也成为了许多基准在比较过程中使用的比较对象。一个输入图像被下采样为高斯金字塔, 每个金字塔层次σ 被分解为通道红色 R,绿色 G,蓝色 B,黄色 Y,属性 I,和方向 O。 对于不同的通道,基于中心计算并归一化其特征图。 在每个通道,相加特征图并归一化,
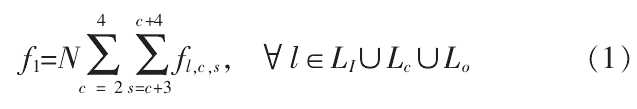

2.2 信息论模型
信息论模型的本质是最大化来自所处视觉环境的信息。其中最有影响力的模型是 AIM 模型。首先,

2.3 图论模型
一个图模型是一个基于图的概率框架, 这个图是基于随机变量间的条件独立结构。 基于图论的显著性模型把眼动数据看成时间序列。 因为有隐藏变量在影响眼动的顺序, 因此方法如隐马尔科夫模型(HMM), 动态贝叶斯网络 (DBN), 条件随机场被囊括在内。 Salah 提出一种基于图论的显著性模型并将其应用到手写数字化以及人脸识别。 Harel 提出基于图论的方法 (GBVS)。 他们在多个空间尺度提取特征。 接下来, 建立一个基于各个特征图的全连接的图。 两个节点间的权重与两个节点的特征相似度和空间距离成正比。 特征图中位置(i,j) 和位置(p,q)的不相似度表示为
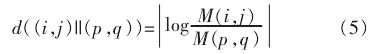

最终的结果图为经过权重归一化和平衡的马尔科夫链。 在平衡过程中,与邻接顶点的相似度非常低的店被赋予大的显著数值。 图论可以帮助研究者为显著性模型构建更复杂的显著性机制。 然而,图论模型的缺点是模型的复杂度太高。
2.4 频域模型
2.5 模式分类模型
机器学习方法也同样被应用于视觉显著性预测领域。 一般的模型需要选择特征,再评估权重,整合等 3 个步骤。 因为常常会加入人脸,文字等高层视觉信息,这些方法也不是纯粹的自底向上方法。Kienzle提出一种基于学习的非参数的自底向上方法。该模型通过训练一个支持向量街(SVM)[17-18]来决定显著性。他们还在视频上学习了一组空域滤波器来寻找显著性区域。 这种方法的优势是不需要事先定义哪些特征对显著性有影响,哪些特征对显著性的影响大。当然,这种方法的结果也更倾向于在图像中心。Judd,与 Kienzle 相似,训练了一个基于低层视觉,中层视觉,高层视觉特征的线性支持向量机 (SVM)。他们的方法在 1 003 张图片上测试效果显著。随着眼动数据库的增多,以及眼动仪的普及,模式分类模型越来越受欢迎。 在现有的数据库评估中,排名最高的模型大多都是基于模式分类的模型。然而,这种模型是完全依赖于大量数据以及数据内容的。这样的一个弊端是使得显著性模型的评估,计算速度。同时,容易造成研究者疏于研究视觉显著性模型的内机理。
3 视觉显著性数据库
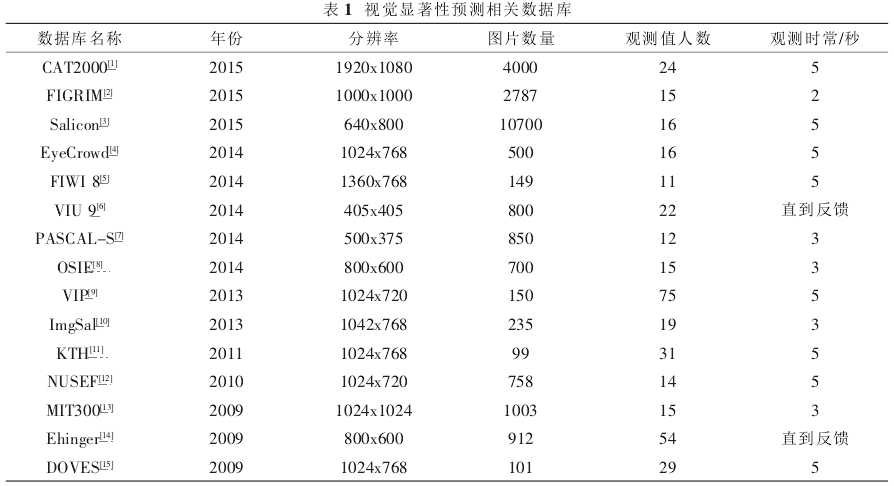
为评估视觉显著性模型的效果, 相关研究者提供了丰富的数据库。 早期的数据库情景单一,背景和前景颜色对比强烈。 近年,一些数据库包含了复杂的背景和多个显著物体。表一介绍了近些年的用于视觉显著性预测的图像数据库,其中包括数据库年份,图像分辨率,图像数量,观测者数量,观测时长等重要信息。每个数据库都有它的优点和局限性。评估一个视觉显著性预测模型的最好方法是在不同的数据库上同时评估。Salicon[3]是迄今为止规模最大的眼动数据集,目前公开的图像超过 10 000 张。与传统的使用眼动仪来收集标注集的方法不同, 该数据库使用了一种鼠标点击的方法来收集标准集。数据库中图像来源于内容复杂的 MSCOCO。 这为今后基于机器学习的显著性预测方法提供了大规模可训练数据。
4 性能评估
4.1 Area Under ROC

4.2 SImilarity Score

4.3 Linear Correlation Coefficent

4.4 Earth Mover‘s Distance


4.5 Normalized Scanpath Saliency

4.6 String Editing Distance

5 研究趋势
目前,随着针对显著性算法的不断探索,大规模显著性数据库的增多,计算机器性能的提升,视觉显著性预测模型已经在现有的数据库上达到不错的效果。 然而,数据库本身的局限性和偏差,使得显著性预测模型所受的调整降低, 基于复杂情景的显著性预测结果仍与标准集有一定差距。 一方面,创建一个情景更加复杂,多显著性物体,颜色更加相似,基于语义的显著性图像数据库将极大地促进视觉显著性预测的发展;另一方面,针对具体情景的研究将更具有实际意,比如,公共交通中的显著性预测,平面广告设计中的显著性预测, 超市物品摆放的显著性预测等。
6 结论
目前, 关于视觉显著性的研究日益增多因为其广泛的应用前景。 因此,鉴于目前学术界对视觉显著性预测综述性质的文章很少, 本文对现有的显著性预测算法做了一个总结和概述, 同时展望了该领域未来的研究趋势。 本文的目的是方便研究者对显著性预测有一个总体的认识和把握,因为篇幅有限,算法的具体实施可以参考文中对应的参考文献, 希望对大家在相关领域的科研有所帮助或启示。
参考文献
[1] Borji A, Itti L. CAT2000: A large scale fixation
dataset for boosting saliency research [C]//. CVPR
2015 workshop on “Future of Datasets”, 2015.
ar Xiv.
[2] Bylinskii Z, Isola P, Bainbridge C,et al. Intrinsic
andextrinsic effects on image memorability [J].
Vision research, 2015,116:165-178.
[3] Jiang M, Huang S, Duan J, et al. SALICON:
Saliency in Context [C]// The IEEE Conference on
Computer Vision and Pattern Recognition (CVPR).
2015:1072-1080.
[4] Jiang M, Xu J, Zhao Q. Saliency in crowd [C]. In
Computer Vision -ECCV2014, Springer, 2014:
17-32.
[5] Shen C, Zhao Q. Webpage saliency [C]. In Computer
Vision-ECCV 2014, Springer,2014:33-46.
[6] Koehler K, Guo F, Zhang S,et al. What do
saliency modelspredict [J]. Journal of vision,
2014,14(3):14-14.
[7] Li Y, Hou X, Koch C,et al. The secrets of salient
objectsegmentation [J]. In Proceedings of the IEEE
Conference on Computer Vision and Pattern
Recognition, 2014:280-287.
[8] Xu J, Jiang M, Wang S,et al. Predicting huma-
ngaze beyond pixels[J]. Journal of vision, 2014,14
(1):28-28.
[9] Ma K T, Sim T, Kankanhalli M. VIP: A unifying
framework for compu-tational eye-gaze research[J].
In Human Behavior Understanding,Springer,2013:
209-222.
[10]Li J, Levine M D, An X,et al. Visual saliency
based on scale -space analysis in the frequency
domain. Pattern Analysis and Machine Intelli -
gence[J]. IEEE Transactions on, 2013,35(4):996-1010.
[11]Kootstra G, de Boer B, Schomaker L R.Predicting
eye fixations oncomplex visual stimuli using local
symmetry [J]. Cognitive computation, 2011,3 (1):
223-240.
[12] Chikkerur S, Serre T, Tan C,et al. What and
where: A Bayesianinference theory of attention [J].
Vision research, 2010,50(22):2233-2247.
[13]Ramanathan S, Katti H, Sebe N,et al. An eye
fixation database for saliency detection inimages[J].
Computer Vision-ECCV2010, 2010:30-43.
[14]Judd T, Ehinger K,Durand F,et al. Learning to
predict where humans look[J]. Proceedings, 2009,
30(2):2106-2113.
[15]Borji A, Sihite D N, Itti L. What stands out in a
scene A study of humanexplicit saliency judgment
[J]. Vision research, 2013,91:62-77.
[16]Van D L I, Rajashekar U, Bovik A C, et al.
DOVES: a database of visual eye movements. [J].
Spatial Vision, 2009,22(2):77-161
标签:ane work ebe mem int learn mil bvs lsp
原文地址:https://www.cnblogs.com/ariel-dreamland/p/9156879.html