标签:有关 幸运 .com 解决办法 高可用 新版本 信息 size 高负载
硬件环境:问题现象:
系统陆续出现断续无法访问的现象;nginx虚机、mysql虚机阶段性频繁宕机;无Dump日志,kernel日志无异常, message无错误信息;
问题排查过程
最开始我们怀疑是因为软件程序的问题,所以最先查看了linux系统日志,可是日志中并没有留下任何蛛丝马迹。
然后我们又分析了nginx的access日志和error日志同样一无所获,之后根据访问量打印出了top url,收集宕机之前的最后几次请求进行比对,同样没有任何线索。宕机是没有规律且随机发生的事件。
考虑到业务量问题,我们紧接着对nginx所在虚拟机进行了内核优化,包括tcp等参数的调整,期望从这上面找到答案,并且从官方获取到系统镜像的md5进行校验,然而宕机依旧发生,并且发生的时间都是访问的高峰时期或者在磁盘负载很大的时候。主备机制虽然生效了,但是主机宕掉备机宕,为了保证系统正常运行,我们只能是靠人肉运维来支持。
现在已经排除了由服务或者系统引起的宕机,只能从宿主机和硬件设备上找原因了。由于客户的Vmware技术支持服务已经到期,无法取得官方,只能通过网上搜索或者查看官方资料来排查问题了。
所幸vmware是基于linux内核编写的,为排查降低了一定的难度,但是我们对vmware没有任何经验,也只能是摸着石头过河。
为了对系统运行情况有更全面的检测,我们对Vmware ESX服务器系统软件日志进行了深入的分析。经分析我们在“vmkernel.log”文件中发现下列情况,磁盘阵列子系统系统响应不稳定。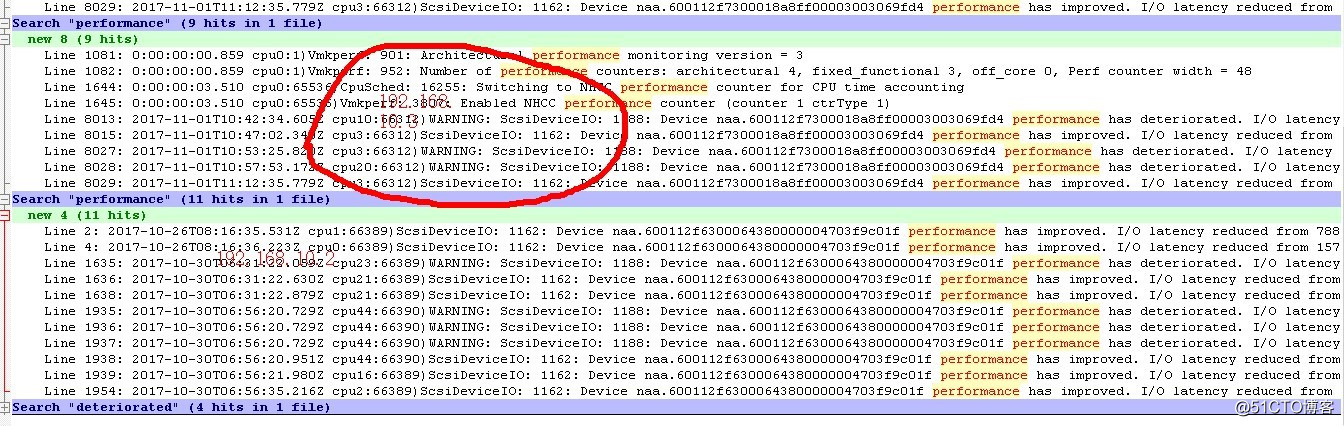
? 如下图,磁盘阵列子系统延迟响应时间在9044到1671965微秒之间徘徊(根据经验磁盘平均响应时间一般在30-40毫秒之间),最大延迟达到1.7秒: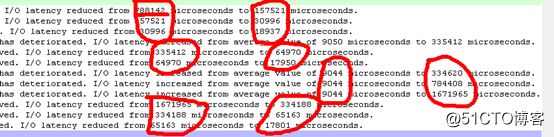
? 根据VMware官网相关资料介绍,出现响应延迟的主要原因有4种:A,硬件被改变了;B,磁盘介质有错误;C,出现高负载;D,容错机制生效。在我们的环境下,唯一的可能性是B,即磁盘介质有错误或C,即由于某个磁盘介质出错引起阵列中的容错磁盘进行代偿的容错机制;
https://kb.vmware.com/s/article/2007236?language=en_US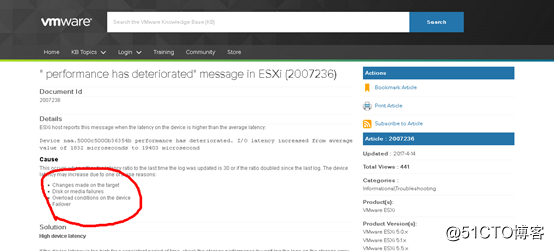
? 为了证实我们的判断,我们有针对系统对磁盘阵列子系统的请求情况进行进一步排查,磁盘阵列子系统("naa.600112f6300064380000004703f9c01f"即本机的磁盘阵列子系统)的请求出现1082次失败。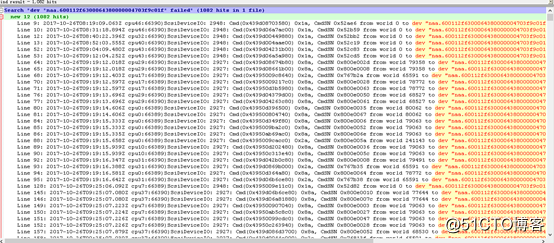
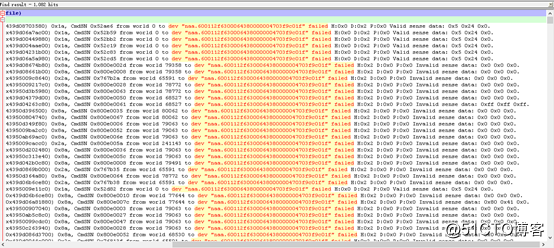
其中:磁盘阵列子系统返回H:0x2或D:0x2表示RAID卡或磁盘子系统没有准备好,出现没有准备好的原因可能有两种:A,此时磁盘负荷较重;B,磁盘介质有错误。
经过对上述排查资料进行综合分析,我们得出如下初步结论:
磁盘阵列子系统工作不稳定可能是造成近期系统间断无法访问的主要原因;
紧接着我们将如上结论反馈至服务器供应商,联系到供应商后答复为可能是raid卡驱动对vmware不兼容造成的故障,新版本已经修复该问题。经过一系列的协商,我们在约定的时间停掉生产系统对raid卡驱动按照供应商的要求进行了一次升级。
第二天,我们将系统从新上线,当看到网页出现时候我们充满着澎湃和期望。
当系统稳定运行了几天之后,本以为皆大欢喜我们终于解决了该问题,系统有一次宕机了。。。
我们又回到了原点,没有线索没有思绪,我们向供应商反馈可能硬件存在问题,但是由于种种原因供应商并不接受和承认我们的说法。
于是我们不得不从新分析vmwere日志,在这之间我们向客户请求购买官方技术支持或者更换戴尔服务器,客户都以预算为由拒绝了。
紧接着又是一系列的压力和排查!!!
我们怀疑过内存负载过大导致的该问题,于是将生产数台虚机迁移到客户测试环境上,由内存64G已使用60G降到已使用45G进行观察,故障依旧。。。。
这时候我们突然想到,虚拟机是由kvm的qcow2镜像转至成vmdk镜像的,会不会和这有关,于是我们开始对虚机的加载日志进行分析。
在这之中我们发现了一个诡异的信息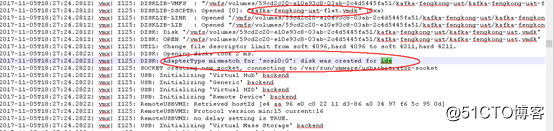
虚拟机磁盘的接口定义为“ide“,而不是VMwareESX上定义的“SCSI“接口,即接口定义不匹配。
原因是由于所有虚拟机磁盘文件都是从公司内部的KVM虚拟机文件移植过来,在创建虚机的时候选择了默认的接口格式ide。
根据官方资料,ESXI 6.5版本并不支持IDE模式的接口,我们仿佛找到了突破口,紧接着我们网上搜索资料进行修改
http://blog.sina.com.cn/s/blog_7120c0be0101exol.html
根据上面链接的教程,我们对虚机进行了修改并且经过测试,该修改对虚机无影响,于是我们在夜里对生产虚机进行了修改。
事与愿违,希望越大失望越大。经过一周的测试,故障依旧。。。
最终的解决办法:
幸运的是,虚拟机宕机后有很大的几率会马上重新启动起来,nginx我们用keepalived做了高可用,并且通过脚本和zabbix进行监控和故障转移。即使宕机,对生产并没有很直观的影响。数据库虚机也会重启,但是从来都是在夜里,因为夜里做大量的数据处理。
最终总结:
到目前为止该故障还会偶尔的出现,我们并没有找到根本原因,其他服务的机器也会宕机(所有服务器都有负载均衡或者高可用),但是不如nginx和mysql频繁。
我们最终怀疑的两个方向:1,硬盘问题 2,镜像转制问题
但是如上的怀疑也是猜测,我们无法找到有力的证据证明,并且也没有权利要求更换硬件。
最最终总结:
我们在切换虚机硬盘接口格式的时候,由于快照问题,又发生了重大的生产事故,一系列的小偏差导致了最终的结果“重要生产数据丢失”。不过最终我们拯救了回来,这件事也是我运维生涯中的一次大事记了。这个故事我将会写在另外的文章里。
rc.local在某些特殊情况下并不靠谱不靠谱不靠谱,重要的事情说三遍,在未知原因宕机的时候,我们发现rc.local中的命令并没有被执行,但是在正常启动或者重启的时候又可以正常执行里面的启动命令。最终我们将服务都修改为用chkconfig来管理。
标签:有关 幸运 .com 解决办法 高可用 新版本 信息 size 高负载
原文地址:http://blog.51cto.com/eisen/2130366