标签:分离 解压 serve address key dep tools red 工作
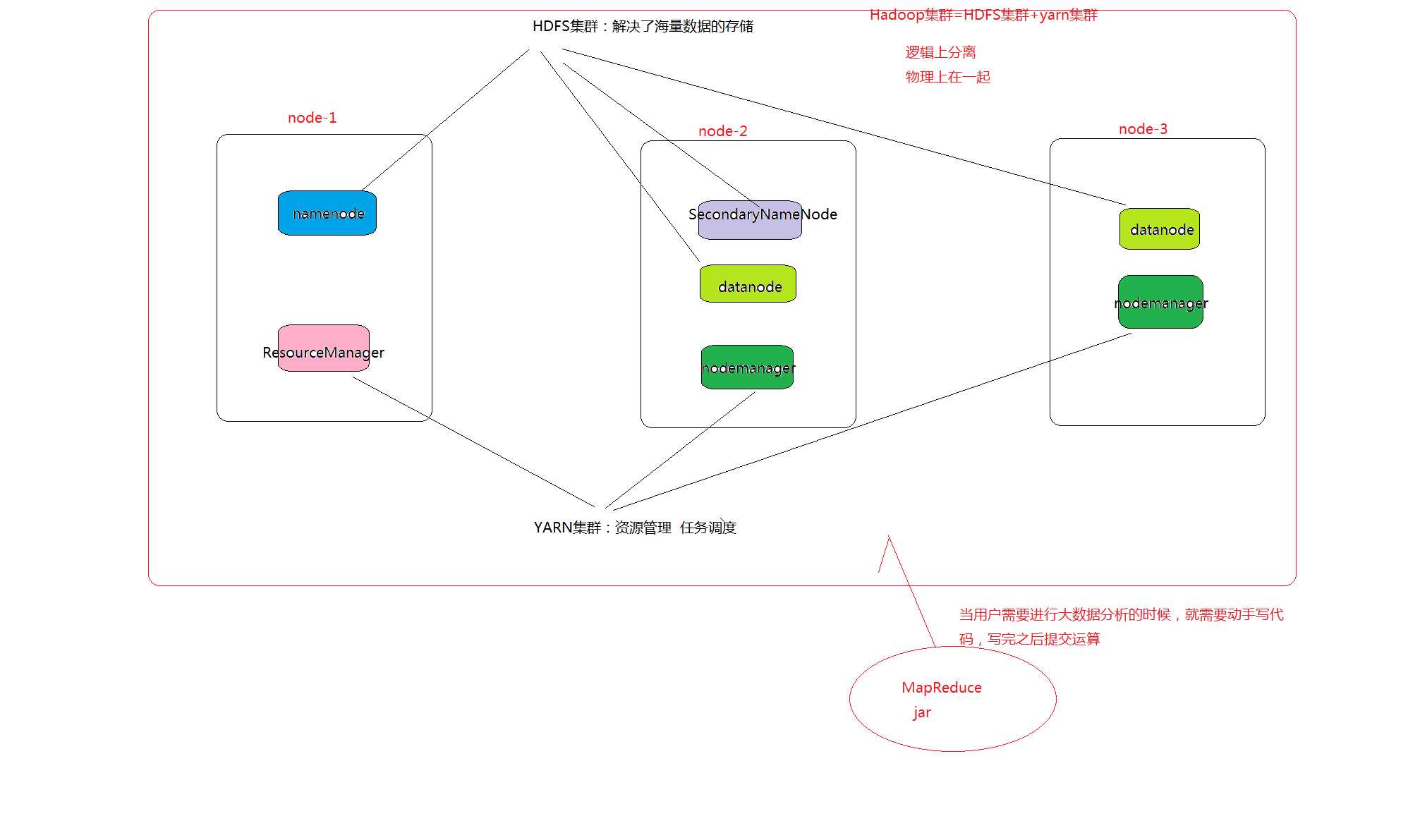
HADOOP 集群具体来说包含两个集群:HDFS 集群和 YARN 集群,两者逻辑上分离,但物理上常在一起。
HDFS 集群负责海量数据的存储,集群中的角色主要有:
NameNode、DataNode、SecondaryNameNode
YARN 集群负责海量数据运算时的资源调度,集群中的角色主要有:
ResourceManager、NodeManager
MapReduce 是一个分布式运算编程框架,是应用程序开发包,由用户按照编程规范进行程序开发,后打包运行在 HDFS 集群上,并且受到 YARN 集群的资源调度管理。
Hadoop 部署方式分三种,Standalone mode (独立模式)、Pseudo-Distributedmode(伪分布式模式)、Cluster mode(群集模式)。其中前两种都是在单机部署。
独立模式又称为单机模式,仅 1 个机器运行 1 个 java 进程,主要用于调试。
伪分布模式也是在 1 个机器上运行 HDFS 的 NameNode 和 DataNode、YARN 的ResourceManger 和 NodeManager,但分别启动单独的 java 进程,主要用于调试。
集群模式主要用于生产环境部署。会使用 N 台主机组成一个 Hadoop 集群。这种部署模式下,主节点和从节点会分开部署在不同的机器上。
我们以 3 节点为例进行搭建,角色分配如下:
node-01(主机名) NameNode DataNode ResourceManager
node-02(主机名) DataNode NodeManager SecondaryNameNode
node-03(主机名) DataNode NodeManager
yum install ntpdate
ntpdate ntp1.aliyun.com
vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=node-1
vi /etc/hosts
192.168.175.151 node-1
192.168.175.152 node-2
192.168.175.153 node-3
#生成 ssh 免登陆密钥
ssh-keygen
#将公钥拷贝到要免密登陆的目标机器上
ssh-copy-id node-1
ssh-copy-id node-2
ssh-copy-id node-3
#立即关闭防火墙,但重启后自动开启
service iptables stop
#关闭防火墙开机启动
chkconfig iptables off
rpm -qa|grep java
rpm -e --nodeps xxxxxxxxxxxxxxxxxxx
jdk-8u65-linux-x64.tar.gz
tar zxvf jdk-8u65-linux-x64.tar.gz -C /root/apps
/etc/profile
export JAVA_HOME=/root/apps/jdk1.8.0_65
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
source /etc/profile
scp -r /root/apps/jdk1.8.0_65 root@node-2:/root/apps/
scp -r /root/apps/jdk1.8.0_65 root@node-3:/root/apps/
目录结构如下:
bin:Hadoop 最基本的管理脚本和使用脚本的目录,这些脚本是 sbin 目录下管理脚本的基础实现,用户可以直接使用这些脚本管理和使用 Hadoop。
etc:Hadoop 配置文件所在的目录,包括 core-site,xml、hdfs-site.xml、mapred-site.xml 等从 Hadoop1.0 继承而来的配置文件和 yarn-site.xml 等Hadoop2.0 新增的配置文件。
include:对外提供的编程库头文件(具体动态库和静态库在 lib 目录中),这些头文件均是用 C++定义的,通常用于 C++程序访问 HDFS 或者编写 MapReduce程序。
lib:该目录包含了 Hadoop 对外提供的编程动态库和静态库,与 include 目录中的头文件结合使用。
libexec:各个服务对用的 shell 配置文件所在的目录,可用于配置日志输出、启动参数(比如 JVM 参数)等基本信息。
sbin:Hadoop 管理脚本所在的目录,主要包含 HDFS 和 YARN 中各类服务的启动/关闭脚本。
share:Hadoop 各个模块编译后的 jar 包所在的目录。
hadoop-2.7.4-with-centos-6.7.tar.gz
tar zxvf hadoop-2.7.4-with-centos-6.7.tar.gz /export/servers/
cd /export/servers/hadoop-2.7.4/etc/hadoop
文件中设置的是 Hadoop 运行时需要的环境变量。JAVA_HOME是必须设置的,即使我们当前的系统中设置了 JAVA_HOME,它也是不认识的,因为 Hadoop 即使是在本机上执行,它也是把当前的执行环境当成远程服务器
vi hadoop-env.sh
#修改export JAVA_HOME=jdk的安装目录
export JAVA_HOME=/root/apps/jdk1.8.0_65
hadoop 的核心配置文件,有默认的配置项 core-default.xml。
core-default.xml 与 core-site.xml 的功能是一样的,如果在 core-site.xml 里没有配置的属性,则会自动会获取 core-default.xml 里的相同属性的值。
vi core-site.xml #在文件的<configuration>标签内加入以下配置
<!-- 用于设置 Hadoop 的文件系统,由 URI 指定 --> <property> <name>fs.defaultFS</name> <value>hdfs://node-1:9000</value> </property> <!-- 配置 Hadoop 的临时目录,默认/tmp/hadoop-${user.name} --> <property> <name>hadoop.tmp.dir</name> <value>/export/data/hadoopdata</value> </property>
HDFS 的核心配置文件,有默认的配置项 hdfs-default.xml。
hdfs-default.xml 与 hdfs-site.xml 的功能是一样的,如果在 hdfs-site.xml 里没有配置的属性,则会自动会获取 hdfs-default.xml 里的相同属性的值。
vi hdfs-site.xml #在文件的<configuration>标签内加入以下配置
<!-- 指定 HDFS 副本的数量 --> <property> <name>dfs.replication</name> <value>2</value> </property> <!-- secondary namenode 所在主机的 ip 和端口--> <property> <name>dfs.namenode.secondary.http-address</name> <value>node-2:50090</value> </property>
MapReduce 的核心配置文件,有默认的配置项 mapred-default.xml。
mapred-default.xml 与 mapred-site.xml 的功能是一样的,如果在 mapred-site.xml 里没有配置的属性,则会自动会获取 mapred-default.xml 里的相同属性的值。
vi mapred-site.xml #在文件的<configuration>标签内加入以下配置
<!-- 指定 mr 运行时框架,这里指定在 yarn 上,默认是 local --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
YARN 的核心配置文件,有默认的配置项 yarn-default.xml。
yarn-default.xml 与 yarn-site.xml 的功能是一样的,如果在 yarn-site.xml 里没有配置的属性,则会自动会获取 yarn-default.xml 里的相同属性的值。
vi yarn-site.xml #在文件的<configuration>标签内加入以下配置
<!-- 指定YARN的老大(ResourceManager)的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>node-1</value> </property> <!-- NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序默认值:"" --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>
slaves 文件里面记录的是集群主机名。一般有以下两种作用:
一是:配合一键启动脚本如 start-dfs.sh、stop-yarn.sh 用来进行集群启动。这时候 slaves 文件里面的主机标记的就是从节点角色所在的机器。
二是:可以配合 hdfs-site.xml 里面 dfs.hosts 属性形成一种白名单机制。
那么所有在 slaves 中的主机才可以加入的集群中。
vi slaves
node-1
node-2
node-3
vi /etc/profile
export HADOOP_HOME= /export/servers/hadoop-2.7.4
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
#刷新配置文件
source /etc/profile
scp -r /export/servers/hadoop-2.7.4 root@node-2:/export/servers/
scp -r /export/servers/hadoop-2.7.4 root@node-3:/export/servers/
scp -r /etc/profile root@node-2:/etc/
scp -r /etc/profile root@node-3:/etc/
#在node-2和node-3服务器上刷新配置文件
source /etc/profile
要启动 Hadoop 集群,需要启动 HDFS 和 YARN 两个集群。
注意: 首次启动 HDFS 时,必须对其进行格式化 操作。本质上是一些清理和准备工作,因为此时的 HDFS 在物理上还是不存在的。
初始化操作只做一次,在集群首次搭建完毕之后,第一次启动之前
#只在node-1中执行一次
hdfs namenode -format 或者 hadoop namenode -format
在主节点上使用以下命令启动 HDFS NameNode:
hadoop-daemon.sh start namenode
在每个从节点上使用以下命令启动 HDFS DataNode:
hadoop-daemon.sh start datanode
在主节点上使用以下命令启动 YARN ResourceManager:
yarn-daemon.sh start resourcemanager
在每个从节点上使用以下命令启动 YARN nodemanager:
yarn-daemon.sh start nodemanager
以上脚本位于$HADOOP_PREFIX/sbin/目录下。如果想要停止某个节点上某个角色,只需要把命令中的 start 改为 stop 即可。
如果配置了 etc/hadoop/slaves 和 ssh 免密登录,则可以使用程序脚本启动所有 Hadoop 两个集群的相关进程,在主节点所设定的机器上执行。
#一键启动HDFS集群
start-dfs.sh
#一键启动yarn集群
start-yarn.sh
#一键停止HDFS集群
stop-dfs.sh
#一键停止yarn集群
stop-yarn.sh
#一键启动HDFS和yarn两个集群
start-all.sh
#停止两个集群
stop-all.sh
#因为hadoop是java代码写的,可以通过jps查看进程
jps
一旦 Hadoop 集群启动并运行,可以通过 web-ui 进行集群查看
如:NameNode http://nn_host:port/ 默认 50070.
ResourceManager http://rm_host:port/ 默认 8088
启动我们的集群后,我们可以通过 node-1:50070 进行访问NameNode,
node-1:8088 进行访问ResourceManager
50070为HDFS的NameNode 的外部访问端口
9000为集群中NameNode所在机器的端口
50090为集群中Secondary NameNode所在机器的端口
8088为YARN的ResourceManager 的外部访问端口
标签:分离 解压 serve address key dep tools red 工作
原文地址:https://www.cnblogs.com/jifengblog/p/9265398.html