标签:style blog http color io os 使用 ar strong
TF-IDF(term frequency–inverse document frequency)是一种用于资讯检索的常用加权技术。TF-IDF是一种统计方法,用以评估某个单词对于一个文档集合(或一个语料库)中的其中一份文件的重要程度。单词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜寻引擎应用,作为文件与用户查询之间相关程度的度量或评级。
在一份给定的文件里,词频 (term frequency, TF) 指的是某一个给定的单词在该文件中出现的次数。这个数字通常会被归一化,以防止它偏向长的文件(同一个单词在长文件里可能会比短文件有更高的词频,而不管该词语重要与否)。
逆向文件频率 (inverse document frequency, IDF) 是一个单词普遍重要性的度量。某一特定单词的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。IDF是一个全局因子,其考虑的不是文档本身的特征,而是特征单词之间的相对重要性。特征词出现在其中的文档数目越多,IDF值越低,这个词区分不同文档的能力就越差。
IDF(w)=log(n/docs(w, D))
TF-IDF的主要思想是:如果某个单词在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
比如我们要想提取一篇新闻的关键词,先要对该新闻进行分词,然后根据TF-IDF计算每个单词的权重,并将权重最大的N个单词作为此新闻的关键词。
计算大概过程如下(更详细内容可参考这里):
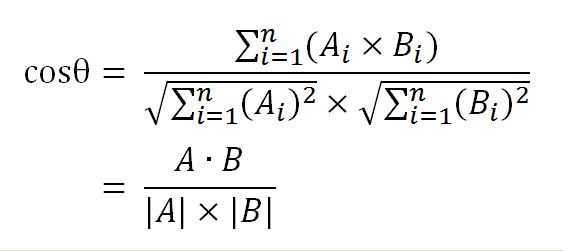
参考文档:
http://www.cnblogs.com/biyeymyhjob/archive/2012/07/17/2595249.html
http://www.ruanyifeng.com/blog/2013/03/tf-idf.html
http://www.ruanyifeng.com/blog/2013/03/cosine_similarity.html
http://www.ruanyifeng.com/blog/2013/03/automatic_summarization.html
标签:style blog http color io os 使用 ar strong
原文地址:http://www.cnblogs.com/chenny7/p/4002368.html