标签:class nbsp src pip3 obd call header first 设置
1,本节学习体会、心得 :
本章的内容非常多,scrapy框架的使用。对于学过django的人来说。可能要更好理解一些把。个人感觉还是挺简单的。所有的知识点一听就懂,唯一不好的就是时间太紧迫了,不的不快速观看,只能等以后拐回来再细细品味了。本章的难点再下载中间件,实际上跟django差不多,但是仍然需要认真听才能听懂,而且要结合自己敲代码联系。这样就能够很好掌握了。其它的应用方面就简单多了,可以快速浏览,知道功能和使用方法,联系的时候可以随时翻笔记完成。对与时间紧迫的小伙伴们来说,还是挑重点学习更好
2,本节的知识点总结:
总结:
1. 安装scrapy
linux安装 pip3 install scrapy
windows安装 pip3 install wheel 下载twisted http://www.lfb.uci.edu/~gohlke/pythonlibs/#twisted pip3 install Twisted-18.4.0-cp36-cp36m-win_amd64.whl 安装scrapy Pip3 install scrapy 安装pywin32 Pip3 install pywin32
2. scarpy 的基本使用
创建project scrapy startproject day710 #创建一个项目 d day 710 #进入项目目录 scrapy genspider example example.com 创建要爬取的网站的文件 scrapy crawl chouti --nolog # 运行起来 设置初始url(默认设置好的)
response.text 就是爬取到的内容 然后进行解析
from scrapy.selector import HtmlXPathSelector #导入内部解析器
解析: 标签对象:xpath(‘/html/body/url/li/a/@href‘) 列表: xpathe(‘/html/body/url/li/a/@href‘).extract() 值: xpathe(‘/html/body/url/li/a/@href‘).extract_first()
3. 爬虫的的架构
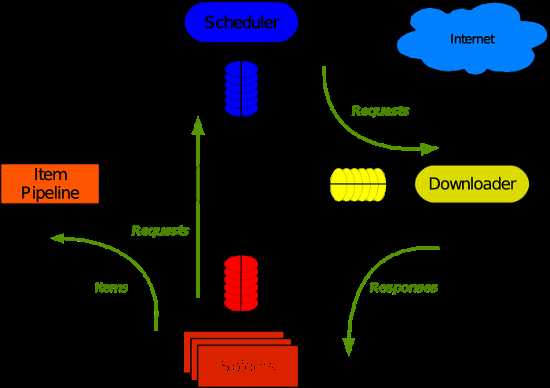
Scrapy主要包括了以下组件:
Scrapy运行流程大概如下:
4.post/请求头/cookie 去重 中间件
post/请求头/cookie
自动登陆抽屉
先访问一个页面 拿到cookie
原始的cookie
print(response.headers.getlist(‘Set-Cookie‘))
解析的cookie
Cookie = cookieJar()
cookie.extract_cookies(response,response.request)
cookie_dic={}
fork,vincookie._cookies.items():
fori,jinv.items():
form,ninj.items():
self.cookie_dic[m]=n.value
print(self.cookie_dic)
req=Request(
url=‘http://dig.chouti.com/login‘,
method=‘POST‘,
headers={‘Content-Type‘:‘application/x-www-form-urlencoded;charset=UTF-8‘},
body=‘phone=8613503851931&password=abc1234&oneMonth=1‘,
cookies=self.cookie_dic,
callback=self.parse_check,
)
yieldreq
利用meta={‘cookiejar‘:True} 自动操作cookie
defstart_requests(self):
forurlinself.start_urls:
yieldRequest(url=url,callback=self.parse_index,meta={‘cookiejar‘:True})
req=Request(
url=‘http://dig.chouti.com/login‘,
method=‘POST‘,
headers={‘Content-Type‘:‘application/x-www-form-urlencoded;charset=UTF-8‘},
body=‘phone=8613503851931&password=abc1234&oneMonth=1‘,
meta={‘cookiejar‘:True},
callback=self.parse_check,
)
Yield req
开启关闭cookie 配置文件里
#COOKIES_ENABLED=False
避免重复访问
scrapy默认使用 scrapy.dupefilter.RFPDupeFilter 进行去重,相关配置有:
1 DUPEFILTER_CLASS = ‘scrapy.dupefilter.RFPDupeFilter‘
2 DUPEFILTER_DEBUG = False
3 JOBDIR = "保存范文记录的日志路径,如:/root/" # 最终路径为 /root/requests.seen
来自 <http://www.cnblogs.com/wupeiqi/articles/6229292.html>
中间件
对所有请求在请求的时候自动添加请求头
配置
DOWNLOADER_MIDDLEWARES={
‘day710.middlewares.Day710DownloaderMiddleware‘:543,
}
先写这么多 待更新
标签:class nbsp src pip3 obd call header first 设置
原文地址:https://www.cnblogs.com/iamdi/p/9297448.html