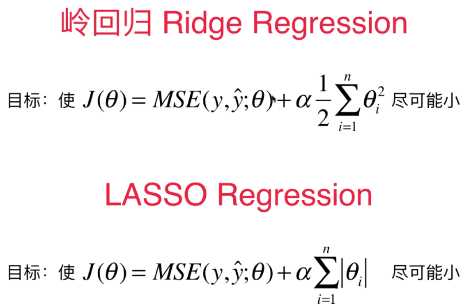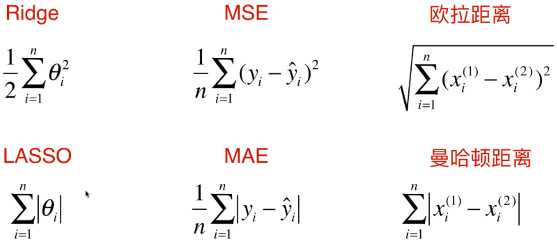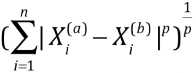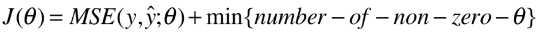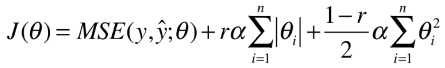标签:缺点 不同 也会 条件 理论 曲线 考试题 需要 考试
Ridge、LASSO:衡量模型正则化;
MSE、MAE:衡量回归结果的好坏;
欧拉距离、曼哈顿距离:衡量两点之间距离的大小;
其它
2)现实中,在进行正则化的过程中,通常要先使用 岭回归
3)当特征非常多时,应先考虑使用 弹性网
机器学习:模型泛化(L1、L2 和弹性网络)
原文地址:https://www.cnblogs.com/volcao/p/9306821.html