标签:spark 分享 oca foreach 个数 nbsp 结果 href 处理
一、题目描述
(1)请编写Spark应用程序,该程序可以在分布式文件系统HDFS中生成一个数据文件peopleage.txt,数据文件包含若干行(比如1000行,或者100万行等等)记录,每行记录只包含两列数据,第1列是序号,第2列是年龄。效果如下:
1 89 2 67 3 69 4 78
(2)请编写Spark应用程序,对分布式文件系统HDFS中的数据文件peopleage.txt的数据进行处理,计算出所有人口的平均年龄。
二、实现
1、在分布式文件系统HDFS中生成一个数据文件peopleage.txt
1)启动hadoop
start-dfs.sh
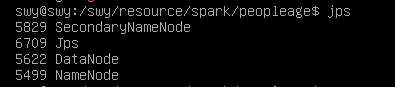
2)在HDFS中创建程序存放目录
hdfs dfs -mkdir -p /swy/resource/peopleage
3)编辑生成peopleage.txt的程序GeneratePeopleAgeHDFS.scala

代码:
import org.apache.spark.SparkConf import org.apache.spark.SparkContext import org.apache.spark.SparkContext._ import scala.util.Random object GeneratePeopleAgeHDFS { def main(args: Array[String]) { val outFile = "hdfs://localhost:9000/swy/resource/peopleage/peopleage.txt" val conf = new SparkConf().setAppName("GeneratePeopleAgeHDFS").setMaster("local[2]") val sc = new SparkContext(conf) val rand = new Random() val array = new Array[String](1000) for(i <- 1 to 1000) { array(i-1) = i +" "+ rand.nextInt(100) } val rdd = sc.parallelize(array) rdd.foreach(println) rdd.saveAsTextFile(outFile) } }
4)打包运行

![]()
5)可以看到HDFS中已经有了peopleage.txt文件
查看:
![]()
2、计算平均年龄
使用前面 创建的CountAvgage.scala文件
运行:
![]()
结果:
![]()
原文:http://dblab.xmu.edu.cn/blog/1756-2/
[spark程序]统计人口平均年龄(HDFS文件)(详细过程)
标签:spark 分享 oca foreach 个数 nbsp 结果 href 处理
原文地址:https://www.cnblogs.com/suwy/p/9350907.html