标签:style blog http color io os ar for 文件
一.第一步是创建一个scrapy项目
sh-3.2# scrapy startproject liuyifeiImage
sh-3.2# chmod -R 777 liuyifeiImage/
二.分析图片特征
1.解决分页url部分:
我们爬虫的start_url是"http://movie.douban.com/celebrity/1049732/photos/?type=C&start=0&sortby=vote&size=a&subtype=a",
第二页地址是"http://movie.douban.com/celebrity/1049732/photos/?type=C&start=40&sortby=vote&size=a&subtype=a",
第三页是"http://movie.douban.com/celebrity/1049732/photos/?type=C&start=80&sortby=vote&size=a&subtype=a",能显而易见得到豆瓣图片的分页规则,因此我们的start_urls可以用一个for循环把所有的页面的url放进来。
start_urls = []; for i in range(0,1120,40): start_urls.append(‘http://movie.douban.com/celebrity/1049732/photos/ type=C&start=%d&sortby=vote&size=a&subtype=a‘%i)
2.解决每一页的图片url部分:
我们在"http://movie.douban.com/celebrity/1049732/photos/?type=C&start=0&sortby=vote&size=a&subtype=a"这一页来分析,审查第一张图片的页面元素
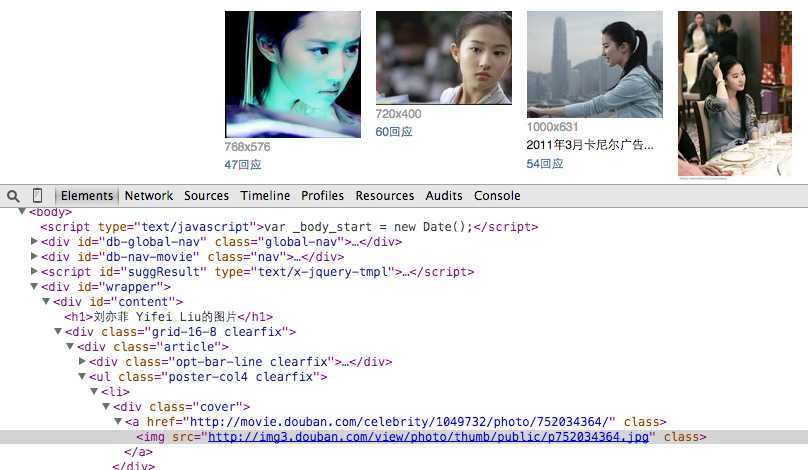
href对应的是每张图的大图地址,而<img src对应的是缩略图地址,我们来看看原图地址链接,
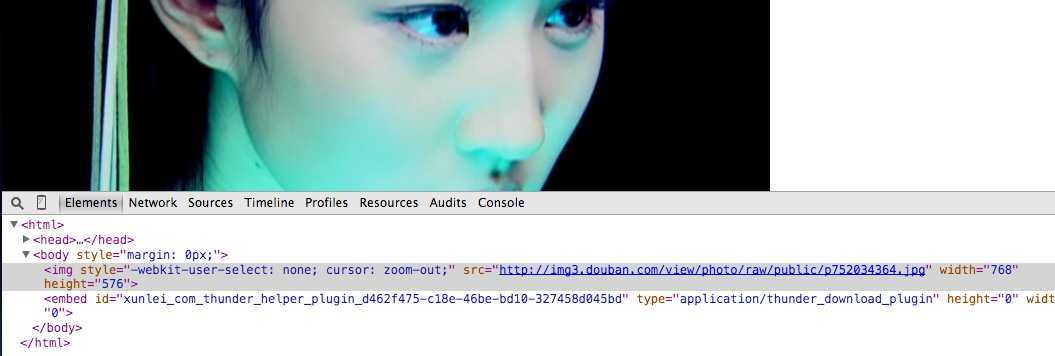
而根据href地址进入的页面图片地址为:
<img src="http://img3.douban.com/view/photo/photo/public/p752034364.jpg">
因此,显而易见,如果想要得到原图地址,只要吧".../view/photo/thumb/public/..."中的"thumb"替换成"photo"或者"raw"即可。
所以spider中的parse部分对应为:
def parse(self,response):
hxs=HtmlXPathSelector(response) sites=hxs.select(‘//ul/li/div/a/img/@src‘).extract()
for site in sites:
#site=site.replace(‘thumb‘,‘photo‘)
site=site.replace(‘thumb‘,‘raw‘)
三.保存生成的url列表
在这里用了两种保存方式json和txt
1.先来看看txt保存方式:
f=open(‘liuyifei_pic_address.txt‘,‘wb‘) def parse(self,response): hxs=HtmlXPathSelector(response) sites=hxs.select(‘//ul/li/div/a/img/@src‘).extract() items=[] for site in sites: site=site.replace(‘thumb‘,‘raw‘) self.f.write(site) self.f.write(‘\r\n‘)
2.json保存:
直接在命令行里用参数执行即可:
scrapy crawl liuyifei -o image.json -t json
这样就能把url列表放置在本地文件image.json中,当然,运行scrapy时也是这条命令。
四.接下来,看看这个scrapy的全貌吧,主要修改的文件就是item.py和liuyifei.py(自己创建的spider文件)。
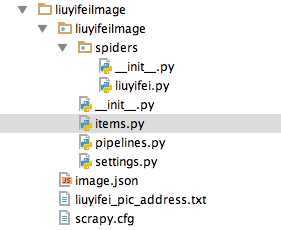
以下是items.py文件
#items.py from scrapy.item import Item,Field class LiuyifeiimageItem(Item): # define the fields for your item here like: # name = scrapy.Field() ImageAddress = Field() pass
以下是liuyifei.py文件:
#liuyifei.py from scrapy.spider import BaseSpider from scrapy.selector import HtmlXPathSelector from liuyifeiImage.items import LiuyifeiimageItem ‘‘‘http://movie.douban.com/celebrity/1049732/photos/‘‘‘ class liuyifeiImage(BaseSpider): name=‘liuyifei‘ allowed_domain=["douban.com"] start_urls=[] f=open(‘liuyifei_pic_address.txt‘,‘wb‘) for i in range(0,1120,40): start_urls.append(‘http://movie.douban.com/celebrity/1049732/photos/?type=C&start=%d&sortby=vote&size=a&subtype=a‘%i) def parse(self,response): hxs=HtmlXPathSelector(response) sites=hxs.select(‘//ul/li/div/a/img/@src‘).extract() items=[] for site in sites: site=site.replace(‘thumb‘,‘raw‘) self.f.write(site) self.f.write(‘\r\n‘) item=LiuyifeiimageItem() item[‘ImageAddress‘]=site items.append(item) return items
最后,运行scrapy,以下是部分打印结果。

sh-3.2# scrapy crawl liuyifei -o image.json -t json /Users/lsf/PycharmProjects/liuyifeiImage/liuyifeiImage/spiders/liuyifei.py:8: ScrapyDeprecationWarning: liuyifeiImage.spiders.liuyifei.liuyifeiImage inherits from deprecated class scrapy.spider.BaseSpider, please inherit from scrapy.spider.Spider. (warning only on first subclass, there may be others) class liuyifeiImage(BaseSpider): 2014-10-04 12:57:37+0800 [scrapy] INFO: Scrapy 0.24.4 started (bot: liuyifeiImage) 2014-10-04 12:57:37+0800 [scrapy] INFO: Optional features available: ssl, http11 2014-10-04 12:57:37+0800 [scrapy] INFO: Overridden settings: {‘NEWSPIDER_MODULE‘: ‘liuyifeiImage.spiders‘, ‘FEED_FORMAT‘: ‘json‘, ‘SPIDER_MODULES‘: [‘liuyifeiImage.spiders‘], ‘FEED_URI‘: ‘image.json‘, ‘BOT_NAME‘: ‘liuyifeiImage‘} 2014-10-04 12:57:37+0800 [scrapy] INFO: Enabled extensions: FeedExporter, LogStats, TelnetConsole, CloseSpider, WebService, CoreStats, SpiderState 2014-10-04 12:57:37+0800 [scrapy] INFO: Enabled downloader middlewares: HttpAuthMiddleware, DownloadTimeoutMiddleware, UserAgentMiddleware, RetryMiddleware, DefaultHeadersMiddleware, MetaRefreshMiddleware, HttpCompressionMiddleware, RedirectMiddleware, CookiesMiddleware, ChunkedTransferMiddleware, DownloaderStats 2014-10-04 12:57:37+0800 [scrapy] INFO: Enabled spider middlewares: HttpErrorMiddleware, OffsiteMiddleware, RefererMiddleware, UrlLengthMiddleware, DepthMiddleware 2014-10-04 12:57:37+0800 [scrapy] INFO: Enabled item pipelines: 2014-10-04 12:57:37+0800 [liuyifei] INFO: Spider opened 2014-10-04 12:57:37+0800 [liuyifei] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min) 2014-10-04 12:57:37+0800 [scrapy] DEBUG: Telnet console listening on 127.0.0.1:6026 2014-10-04 12:57:37+0800 [scrapy] DEBUG: Web service listening on 127.0.0.1:6083 2014-10-04 12:57:38+0800 [liuyifei] DEBUG: Crawled (200) <GET http://movie.douban.com/celebrity/1049732/photos/?type=C&start=240&sortby=vote&size=a&subtype=a> (referer: None) /Users/lsf/PycharmProjects/liuyifeiImage/liuyifeiImage/spiders/liuyifei.py:17: ScrapyDeprecationWarning: scrapy.selector.HtmlXPathSelector is deprecated, instantiate scrapy.Selector instead. hxs=HtmlXPathSelector(response) /Users/lsf/PycharmProjects/liuyifeiImage/liuyifeiImage/spiders/liuyifei.py:18: ScrapyDeprecationWarning: Call to deprecated function select. Use .xpath() instead. sites=hxs.select(‘//ul/li/div/a/img/@src‘).extract() /Library/Python/2.7/site-packages/Scrapy-0.24.4-py2.7.egg/scrapy/selector/unified.py:106: ScrapyDeprecationWarning: scrapy.selector.HtmlXPathSelector is deprecated, instantiate scrapy.Selector instead. for x in result] 2014-10-04 12:57:38+0800 [liuyifei] DEBUG: Scraped from <200 http://movie.douban.com/celebrity/1049732/photos/?type=C&start=240&sortby=vote&size=a&subtype=a> {‘ImageAddress‘: u‘http://img3.douban.com/view/photo/raw/public/p2179423125.jpg‘} 2014-10-04 12:57:38+0800 [liuyifei] DEBUG: Scraped from <200 http://movie.douban.com/celebrity/1049732/photos/?type=C&start=240&sortby=vote&size=a&subtype=a> {‘ImageAddress‘: u‘http://img3.douban.com/view/photo/raw/public/p2179423105.jpg‘} 2014-10-04 12:57:38+0800 [liuyifei] DEBUG: Scraped from <200 http://movie.douban.com/celebrity/1049732/photos/?type=C&start=240&sortby=vote&size=a&subtype=a> {‘ImageAddress‘: u‘http://img3.douban.com/view/photo/raw/public/p2179423084.jpg‘} ... 2014-10-04 13:34:17+0800 [liuyifei] DEBUG: Scraped from <200 http://movie.douban.com/celebrity/1049732/photos/?type=C&start=1040&sortby=vote&size=a&subtype=a> {‘ImageAddress‘: u‘http://img3.douban.com/view/photo/raw/public/p958573512.jpg‘} 2014-10-04 13:34:17+0800 [liuyifei] DEBUG: Scraped from <200 http://movie.douban.com/celebrity/1049732/photos/?type=C&start=1040&sortby=vote&size=a&subtype=a> {‘ImageAddress‘: u‘http://img5.douban.com/view/photo/raw/public/p958572938.jpg‘} 2014-10-04 13:34:17+0800 [liuyifei] INFO: Closing spider (finished) 2014-10-04 13:34:17+0800 [liuyifei] INFO: Stored json feed (1120 items) in: image.json 2014-10-04 13:34:17+0800 [liuyifei] INFO: Dumping Scrapy stats: {‘downloader/request_bytes‘: 8331, ‘downloader/request_count‘: 28, ‘downloader/request_method_count/GET‘: 28, ‘downloader/response_bytes‘: 221405, ‘downloader/response_count‘: 28, ‘downloader/response_status_count/200‘: 28, ‘finish_reason‘: ‘finished‘, ‘finish_time‘: datetime.datetime(2014, 10, 4, 5, 34, 17, 736723), ‘item_scraped_count‘: 1120, ‘log_count/DEBUG‘: 1150, ‘log_count/INFO‘: 8, ‘response_received_count‘: 28, ‘scheduler/dequeued‘: 28, ‘scheduler/dequeued/memory‘: 28, ‘scheduler/enqueued‘: 28, ‘scheduler/enqueued/memory‘: 28, ‘start_time‘: datetime.datetime(2014, 10, 4, 5, 34, 14, 681268)} 2014-10-04 13:34:17+0800 [liuyifei] INFO: Spider closed (finished)
以下是json文件和txt文件:
image.json:

liuyifei_pic_address.txt
标签:style blog http color io os ar for 文件
原文地址:http://www.cnblogs.com/alexkn/p/4005960.html
