标签:技术分享 讲解 text 内容 9.png ora 软件 span line
怎么识别PDF图片中的文字呢?相信很多人都在为这个问题而困扰吧。那么,下面我就来给大家讲解一下如何实现PDF图片文字识别吧。
步骤一:打开电脑浏览器,下载并运行捷速OCR文字识别软件。
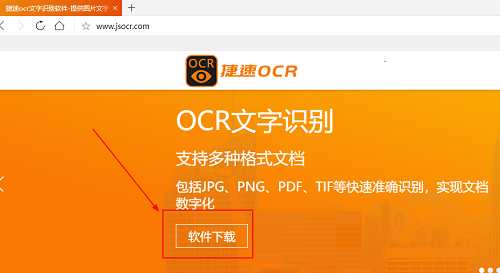
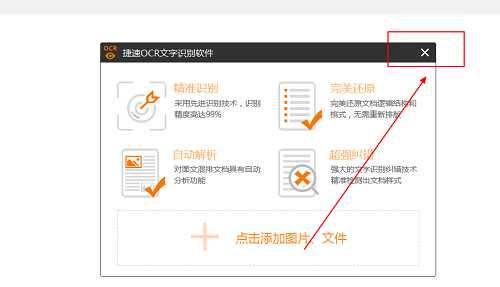
步骤二:打开捷速0CR文字识别软件,点击退出按钮,退出该选项。
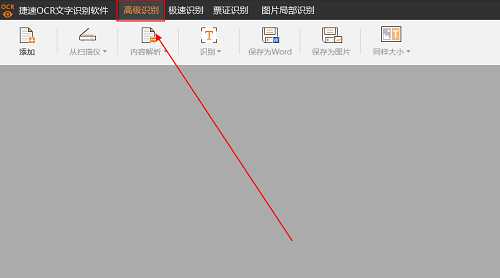
步骤三:点击软件正上方“高级识别”按钮。
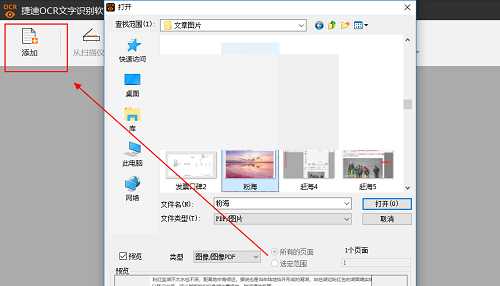
步骤四:随后选择软件左上方“添加”按钮,将自己需要编辑的PDF文件添加进来。
步骤五:文件添加后点击软件上方的“内容解析”按钮,那么软件就会自动对文件进行内容解析操作了。
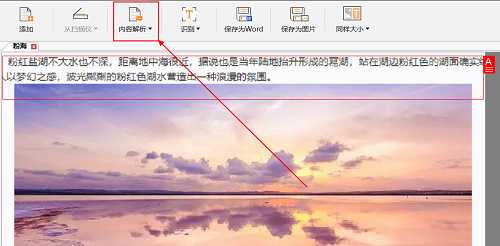
步骤六:选择软件上方的“识别”按钮,软件就会对文件中的文字进行识别,软件所识别的文字是可以修改的,我们可以选中需要修改的文字部分进行修改。
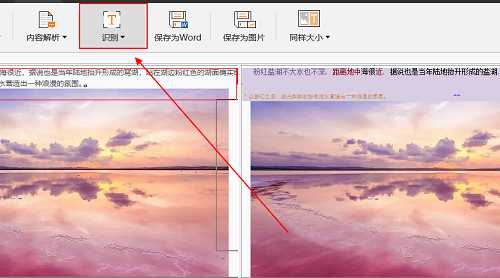
步骤七:点击软件上方的“保存为Word”按钮,将识别后的内容转换成Word格式,然后再对其内容进行编辑即可。
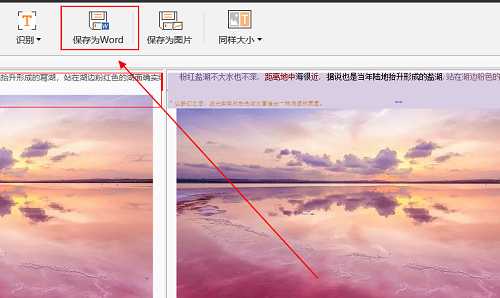
好了,PDF图片文字识别的具体实现步骤已经讲解完了,操作简单,学会了,就再也不用怕PDF图片文字识别了。
心动不如行动,软件下载可前往官网:捷速OCR文字识别软件http://www.jsocr.com
标签:技术分享 讲解 text 内容 9.png ora 软件 span line
原文地址:https://www.cnblogs.com/longlongago666/p/9431726.html
{kind=link}