标签:格式 size logs obj software objdump xeon 其它 效果
标签: 编程 工程 入门
备注:此文最早发表于公司内网,经脱敏处理后,部分内容可能读起来逻辑不太顺,或者残缺部分内容
毕业进厂两年了,在鹅厂两年来的工作中,对编程和工程有了初步的理解和实践,因此决定写下来和大家一起交流,同时正值鹅厂的实习生和毕业生进厂搬砖之际,也希望能给新手们带来一点收获。
总结一下这两年的编程经历(抛开对业务的了解):通过编程和工程实践,对计算机基础的理解不断加深,对程序的掌控力逐步增强。
计算机的世界,是一个以bit(0,1)流为基础,通过各种规则而构建起来的世界,而对于计算机基础的学习,其实就是对规则的学习。编程入门第一关不单是学会一门语言的语法糖,而是意识到自己是一名程序开发者,条件反射一般以程序开发者的角度来重新审视计算机。举一个不是很恰当的例子,我们肯定都接触过word文档,ppt,图片,音视频文件等,在普通人眼里这是各式各类的文件,而在程序开发者眼里这就是一串存放在磁盘上有着各自排列规则的bit(0,1)流,这些文件在被使用之后之所以有不同的表现形式,是因为各自的程序有着各自既定的解析规则。这些规则的制定者同样是程序员,和你我一样。
1 程序结构的理解
在开始在谈程序结构之前,本来还应该提一下编译,链接,程序装载三块(这三块内容每一块都能拿出来长篇大论一番,只讲一些最基本的概念的话意义不大,因此此处不敢染指,推荐相关书籍《程序员的自我修养》),只有了解了自己的二进制文件如何生成,如何装载进内存,其内存布局如何,心里才会更有底气,在出现一些疑难杂症时,也能够更准确快速的定位到根结,篇幅问题,这里不会谈及,但我建议每一位后台开发人员都应该了解。在这里,先上一张老图:
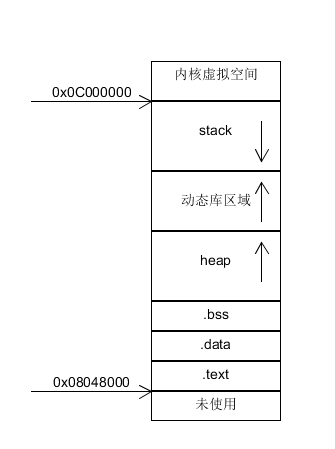
这是描述32位系统下程序大致内存结构的经典老图(64位类似),具体就不赘述了。
很多时候,对于初入编程领域的小白来说,对于知识的理解只是停留在"知道"这一层面(这是可以理解的,毕竟还未经历实践),一般来说也足够应付一般的面试了。我们以一个简单的运用为例:假如一个程序core了,该如何处理。当然,如果有core文件能够追查到其堆栈是最好的,但如果没有core文件呢?此时可以借助dmesg命令,输入后会打印出程序发生错误时的内核错误码和当前的ip寄存器的值,根据此值,我们可以追溯到core发生时的代码。但是此方案存在一个缺陷,如果core是由图中的.text段中的指令引起,那使用dmesg+ip寄存器值我们能直接定位core代码,如果core是第三方的动态库中的指令引起该怎么办?其实也很简单,只要找到该动态库的装载地址,再将ip值减去该地址即得到动态库中的具体core指令地址,再通过objdump将其反汇编即可找到确定位置(编译加了-g时,直接addr2line会更快速)。
再看一张用于描述函数调用栈的经典老图
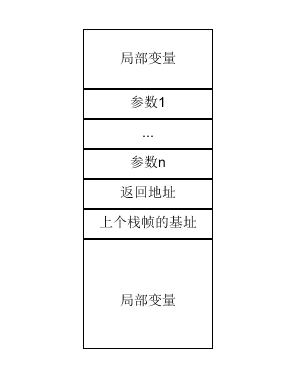
说明一下在x86_64架构下,当寄存器足够存放参数时,是不会对参数进行压栈的,因此图中参数1到n(对应函数参数列表是从右到左)是可选的,当把上个栈帧的基址压入栈中时,新的栈帧就开始了。
相信开发同学们对于函数调用栈的结构早就清楚了,但是有没有想过为什么c/cpp编写的程序函数调用栈长这样?其实没有为什么,只是因为gcc编译器是这么工作的,这是gcc为函数调用设计的规范(更合理的说法应该是编写gcc的大佬们),不过其设计背后的原因其实也不难想到,1是因为各个函数的指令集在物理空间上是独立的,自然需要处理指令的跳转,2是需要解决输入和输出的传递,为什么输入参数少的时候直接用寄存器呢?当然是因为CPU访问寄存器更快,可惜寄存器个数有限,不然我们就不需要缓存和内存了(寄存器也是一片存储空间,不同的寄存器名称只是对不同的地址块的引用而已)。
也就是说gcc帮我们把c/cpp等高级语言编写的代码,按照规范转化为了汇编指令,那如果我们直接用汇编语言编写代码,是不是就可以打破这一规范了?
自然是可以的,下面我们结合协程一起理解。
2 再谈协程的实现
这个话题其实已经被众多同学分析过了,我们以libco为例,只看其核心的协程上下文切换的实现,其关键函数为coctx_swap,这里不过多的谈及其实现过程(有兴趣的同学可以阅读libco协程原理简要分析,libco hook原理简析),只看其开头部分的几条指令:
coctx_swap:
1 leaq 8(%rsp),%rax
2 leaq 112(%rdi),%rsp
3 pushq %rax
4 pushq %rbx
5 pushq %rcx
6 pushq %rdx
7 pushq -8(%rax) //ret func addr
... 为了方便描述,对每一行汇编代码标注了行号,我们只需要关注第一行,第二行和第七行即可。
首先可以确定的是cocox_swap函数肯定不是程序被执行的第一个函数(毕竟main函数也不是程序的入口函数),因此它必然是被某个函数调用而执行的,在它被调用之前,程序已经执行了这些操作(以下所有描述都建立在x86_64架构基础之上):
1 传参,主要是传递给寄存器。当寄存器不够用时,会丛右到左压栈,然后再传参给寄存器
2 将返回地址压栈,该地址一般指向上一函数中的下一条指令
3 修改rip寄存器(指令寄存器)为调用函数的起始地址,新的函数开始了
在谈及第一,二,七行汇编代码前,我们再来看经gcc编译后的c/cpp函数,在函数开始时会做什么事情:
1 将上个函数的栈帧基址(rbp寄存器用于存放栈帧基址)压入栈中
2 将rbp寄存器中的值修改为rsp寄存中的值,即开启了新的栈帧
现在可以看coctx_swap第一,二,七行到底在干了啥:
1 将rsp寄存器中的值加上8得到的地址赋值给rax寄存器
2 修改rsp寄存器中的值为rdi寄存器中的值加上112后的得到的地址,该地址正是其接下来要执行的协程的栈顶地址,此处极为关键,这相当于切换到另一片栈空间去了
7 将rax寄存器中的值减去8得到的地址中的值压如栈中,结合上面所提,rax寄存器减去8得到的地址所存储的值,正是调用coctx_swap的父函数的下一条指令地址。
总结一下,第二行实现了栈空间切换,第七行实现了返回地址的保存,(当然其它行也是在保存协程的上下文,在这里我们不关注),从而进程安心的切换到别的协程去了。
从这里可以看到作者对于c/cpp程序结构的理解和运用。
到现在为止,我们接触到了进程,线程,协程等概念,它们各有差异隐约间又觉得具有共性,追根溯源,有没有更基础的概念来对它们进行统一的描述?有的,本质上它们都属于执行体("执行体"是我自己顺着思路说出的,不对其使用正确性和权威性负责),只不过是执行体的不同表现形式。那什么是执行体呢?
简而言之,执行体就是一段指令和一段私有的地址空间。当然,这段指令本身也将占用一段地址空间。
由于代码段是只读(执行期间不可改变,这点是由操作系统保证)的,那么我们可以不严谨的这样描述:给定下一条指令的地址和一段合法的地址空间,可以确定一个执行体。
我们都知道,一个进程可以创建多个线程,多个线程共享该进程的地址空间,其原理就是这多个线程共享该进程的代码段,以及在该进程的地址空间中专门分配了一段空间用于给该线程使用(当然线程还有一些其它私有变量,这里先忽略)。
另外我们常说的"上下文",对应在执行体上是指什么呢?不严谨的说,对于一个执行体而言,其上下文就是它的地址空间(其执行期间的寄存器值也算入其地址空间中)和下一条指令的地址。
3 软硬结合
首先想问一个问题:进程是操作系统里资源占用的最小单位,这句话有没有毛病?在我还是编程小白时曾在网上看到过这句话,然后记了下来,碰巧还在面试过程中被问到过什么是进程,什么是线程,于是我直接背了出来"进程是操作系统里资源占用的最小单位,线程是CPU执行的最小单元..."。现在回过头来看,其实这句话是有一点别扭,其核心点在于对"资源"一词的理解,其远不止独立的地址空间这么简单,计算机资源理应包括硬件资源。
这一节主要想简单介绍编码过程中经常会遇到跟硬件相关的知识。这一节的内容可深可浅,我也只是掌握一些皮毛而已。另外此部分内容必须结合一些实例来理解。不过我们还是从经典老图出发:
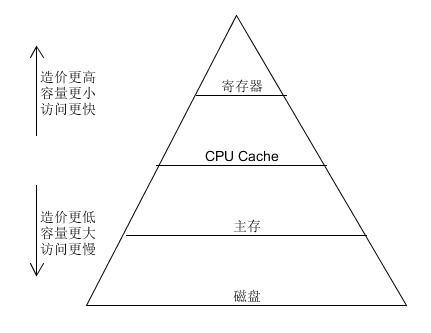
金字塔从上到下,访问速度下降,存储空间更大同时造价更低(金字塔再往下走还有光盘,磁带,由于工作中基本不会接触到,此处就忽略了)。这基本是每个开发人员都知道的东西。一般而言,我们也只需关注磁盘这一块,比如普通硬盘和固态硬盘的硬件结构和读写原理,两者的顺序读写和随机读写的性能差异等,不过磁盘IO这一块基本每一位开发也都十分熟络了。这里就不多谈。
再往上走一层,就到了内存。我认为内存反而是对程序员比较透明的一层,因为操作系统帮我们管理好了,我们能介入的其实不多,大多数时候也就是在用户态层面建立内存池,来进行复用,以及避免小内存的频繁分配产生的系统调用。
再往上走,就到了cache层和寄存器层了,我相信这两块相对于磁盘和内存就显得陌生许多了。由于我们是使用c/cpp编写程序,因此寄存器对我们来说也比较透明(由gcc编译器帮我们进行管理及使用优化),唯一剩下的就是cache层了。
尽管我们很少有机会从编码层面去对cache层的使用做优化,但了解CPU cache结构以及CPU cache的MSEI协议还是很有必要的,对于CPU cache以及MSEI协议,网上已经有很多资料,这里不详述,但还是简要记录一些关键点,以保证此文的完整性。
cache基础
1 cache层次
分为L1 cache,L2 cache,L3 cache,其中L1cache又分为L1 指令cache和L1 数据cache。
在多核CPU中,每个核都有独立的L1和L2cache,但是共享L3cache。
2 cache line
CPU cache是以cache line(缓存段)进行管理的,cache line的大小有32byte,64byte,128byte之分,因CPU差异而不同,现代的x86_64架构的CPU,cache line基本是64byte,由于cache line为CPU cache的最小管理单元,因此每次内存缺失都是以一个cache line的大小从内存中加载数据,以总线位宽64位计算,需要8次内存访问
3 cache 映射
所谓的cache映射,是指主存的地址与cache的地址的映射规则,此处不详述,可以有如下三种方式,全关联映射,直接映射,多路分组映射,实际上现代CPU都是用的多路分组映射。
MSEI协议
上面已经说了,CPU的每个核都有自己的L1cache和L2cache。为什么不共用一套cache呢?因为这样会导致每个指令周期只有一个CPU核能操作cache,其余CPU核必须等待才行(否则就全乱套了),从而使得整个系统都慢了下来。因此为了避免这种情况的发生,我们的每个CPU核都会有一套cache。但多套cache同样带来了一个问题,即如何保证数据的一致性。关于MSEI这里不再赘述,建议读者读完本文再继续往下读:缓存一致性(Cache Coherency)入门。
在了解了cache基础和MSEI协议后,可以开始下面的部分了。
虽说学以致用,但是我相信大部分人即使知道cpu cache的相关知识,却依然不知道该在日常的编程之中能给我们带来什么帮助,包括我自己也好不到哪去。下面谈谈目前为止我仅接触到的一些实际案例(网上也有一些针对CPU cache的例子,不过大多不够贴切现实,基本是对CPU cache的针对性测试)。
1 重新认识死循环
看如下代码段:
int main(){
int cnt = 0;
while(1) cnt++;
return 0;
}如果将其编译链接生成可执行文件运行后,通过top命令,我们大概率会看到有一个CPU核的使用率是100%。这类死循环其实是对cpu和cpu cache的最高利用,我们基本上不可能写出比它还高效的程序了,不过遗憾的是它不能帮我们做任何事情。但是为什么这几行代码能将CPU打满?这说明CPU一直有活可干。这简直是句废话!再往深处想,CPU干活时需要什么基础?自然是指令和数据都能即拿即用,也就是需要执行的指令位于L1 cache或寄存器,需要访问的数据位于L1 cache或寄存器,由于在这个死循环中,指令只有短短几行,数据只有一个int型变量,L1 cache的空间完全足够缓存下它们(事实上编译器很可能进行优化将cnt放到寄存器中),因此CPU才能不间断的干活。在这里我们可以学习到,循环体内的指令和数据都尽量精简,保证L1 cache能全部缓存到(否则会有淘汰,从而产生重复的cache line载入和换出)。不过这一点就跟死循环一样鸡肋,日常工作中,我们的代码基本都是为了快速完成业务需求,多是考虑代码可读性,扩展性,根本不会管一段逻辑的指令/数据工作集有多大。
2 内联函数
在我大学期间学习c++ primer时曾看到关于内联函数的一段话,大意如下:使用内联函数可优化程序性能,但是如果内联函数太长,可能反而会降低程序性能。这句话当初虽然不明白,但也没有深究,直到工作后才理解。
我们都知道内联函数在编译时将会展开,即少了函数调用的那一系列操作(压栈,跳转,出栈,返回等),自然性能会有所提升,那为什么其太长时,可能会降低程序性能?
在学习了CPU cache相关知识之后,其实就很好理解了,当内联函数较长时,由于其将会进行展开,如果多次调用,将导致代码段的膨胀,这有可能导致cache的利用率降低,可能的原因如下:
1 该内联函数的指令同时占用了多份cache空间(因为指令的地址不一样,所以在CPU看来这就是不同的指令)
2 程序整体的工作集变大了,这可能加剧指令cache的淘汰
这一点对于日常工作其实帮助也不大,因为尽管我们可能不知道内联函数为什么太长可能反而会降低程序性能,但实际上我们往往也是遵守这一约定的。
3 缓存行运用
上面有提到CPU cache的MSEI协议,我们知道Share状态的缓存数据,是可能在多个cpu核的cache中存在的,一旦有CPU核需要修改时,需要将其变为Exclusive状态,导致其它cpu核的cache都将失效。这对于我们编程有什么需要注意的地方吗?
当然是有的,比如对于如下一个结构
typedef struct{
char always_read[32];
char always_write[32];
}example;假设我们开辟了一片共享内存(注意,共享内存映射到进程空间的起始地址总是页面大小的整数倍,反向可推出,被分配的example变量其起始地址为64的整数倍)用于存储example结构,系统中有多个进程要对其频繁进行访问。系统的各个进程对其进行访问时,对于always_read成员经常都是读操作,偶尔才有写操作,对于always_write成员总是读写操作。请问这样设计有问题吗?
可以大胆的说,这样当然没有问题。但却不是性能最优,回忆一下上面提到的知识点
1 缓存段的大小一般是64字节(32和128的也存在,跟CPU架构有关,可通过cat /sys/devices/system/cpu/cpu1/cache/index0/coherency_line_size 命令进行查看不同级别cache的缓存段大小)
2 每个cpu核都有一组cache
3 如果某个cpu核对某个cache进行修改后,其余cpu核的对于该cache的缓存段都失效了
对于上面的设计,example结构中的always_read和always_write恰好落在一个缓存段中,即每次有cpu核对always_write改写时,连带着其余cpu核中的always_read也一同失效了,当其余cpu核要对其进行读操作时,必须重新从内存中加载该数据,这会造成很多无意义的缓存缺失情况。
如何解决这种尴尬的情况呢?其实也很简单,我们直接看代码
typedef struct{
char always_read[32];
char padding[32];
char always_write[32];
}example; 如上,我们只需要将always_read和always_write划分到不同的缓存段中即可。
这一点对于平常的工作其实也没什么帮助,但是在设计一些基础组件时(如频率控制)也许能用上。除此之外,由于CPU cache每次载入内存都以cache line为单位的特性,我们可以知道,不合理的条件分支代码也可能降低程序性能,相应的,合理的使用likely和unlikely关键字则可以提升程序性能。其中likely和unlikely的作用便是告诉gcc把相关分支里的指令提前或者移后,以保证cache的命中率。
从编码的角度来看,我暂时接触到的也只有这么一些。在工程入门部分还将会有对CPU cache的应用。
5 原子操作
软件实现部分不提,这里只提硬件支持的原子操作,我们先看一下intel的cpu支持的原子操作:
说明:本段内容截选自[原]原子操作及对C++编程的意义,网上有的资料,这里就不再翻译一遍了:
《Intel 64 and IA-32 Architectures Software Developer`s Manual》Volume3 System Programming Guide,8.1.1 Guaranteed Atomic Operations中讲解的原子操作如下:
Intel486处理器(以及以后生产的处理器)确保以下对基本存储器的操作行为为原子操作:
Reading or writing a byte
读写一个byte
Reading or writing a word aligned on a 16-bit boundary
读写16bit(2byte)内存对齐的字(word)
Reading or writing a doubleword aligned on a 32-bit boundary
读写32bit(4byte)内存对齐的双字(dword)
The Pentium processor (and newer processors since) guarantees that the following additional memory operationswill always be carried out atomically:
Pentium系列处理器(以及以后生产的处理器)确保以下对基本存储器的操作行为为原子操作:
Reading or writing a quadword aligned on a 64-bit boundary
读写64bit(8byte)内存对齐的四字(quadword)
16-bit accesses to uncached memory locations that fit within a 32-bit data bus
使用16bit访问的未缓存的内存,并且这些内存适应32位数据总线(翻译不好)
The P6 family processors (and newer processors since) guarantee that the following additional memory
operationwill always be carried out atomically:
P6系列处理器(以及以后生产的处理器)确保以下对基本存储器的操作行为为原子操作:
Unaligned 16-, 32-, and 64-bit accesses to cached memory that fit within a cache line
对单个cache line中缓存地址的未对齐的16/32/64位访问(非对齐的数据访问非常影响性能)
Accesses to cacheable memory that are split across cache lines and page boundaries are not guaranteed to
beatomic by the Intel Core 2 Duo, Intel?Atom?,Intel Core Duo, Pentium M, Pentium 4, Intel Xeon, P6
family, Pentium, and Intel486 processors. The Intel Core 2 Duo, Intel Atom, Intel Core Duo, Pentium
M,Pentium 4, IntelXeon, and P6 family processors provide bus control signals that permit external memory
subsystems to make splitaccesses atomic; however,nonaligned data accesses will seriously impact the
performance of the processor andshould be avoided.
那些被总线带宽、cache line以及page大小给分隔开了的内存地址的访问不是原子的,你如果想保证这些操作是原子的,你就得求助于机制Bus Lock,对总线发出相应的控制信号才行。
An x87 instruction or an SSE instructions that accesses data larger than a quadword may be implemented
usingmultiple memory accesses. If such an instruction stores to memory, some of the accesses may
complete (writingto memory) while another causes the operation to fault for architectural reasons (e.g.
due an page-table entry thatis marked “not present”). In this case, the effects of the completed
accesses may be visible to software eventhough the overall instruction caused a fault. If TLB
invalidation has been delayed (see Section 4.10.4.4), suchpage faults may occur even if all accesses are
to the same page. 为什么要在编程入门中提原子操作呢?这有助于加深我们对于CPU访问数据的理解,提炼一下关键点:CPU的地址总线宽度,数据总线的宽度,数据总线访问内存时要求的地址对齐(为了降低硬件设计复杂度)。另外其实原子操作在并发编程里实现无锁操作的过程中至关重要,本人之前写过一篇文章:基于nginx的频率控制方案思考和实践,在共享内存的设计过程中,有很多的结构/变量都是保证其内存对齐的,一部分原因自然是因为保证一次内存访问以提升程序性能,更重要的是为了保证其读/写的原子性。
5 再谈TCP/IP
关于TCP/IP的文章实在是太多了,但是同样存在一个问题,大多数的文章都只是在重复的阐述TCP的一些协议内容,缺少一些运用和见解,顺便在这里吐槽一下,网上的资料虽然多,但是存在大量重复无营养的内容,经常导致我们检索一些问题时带来很多无用的点击。正如文章开头所述,计算机基础的学习是对规则的学习,对于规则不能只会背诵,只有理解其设计背后的考量才能灵活运用,本人之前也写过一篇关于TCP的文章:TCP随笔,此文的后半段融入了一些我对TCP部分设计的一些思考和理解。有兴趣的同学可以点击阅读一下,这里就不再赘述了。
6 百练成钢
百练其实是指刷题。刷题是提升/保持编码能力,锤炼逻辑思维最直接有效的手段,而且基本面试的时候都会被问算法题,有了日常积累那就无须再额外花时间去专项练习,一举双得。刷题有两点好处,1是工作中大多数的时候都是在重复的针对某类问题进行编码,如果没有碰上新问题的话,思维很难变得更进一步,而刷题过程中往往能碰到各式各类的题目,百炼才能成钢。2是刷题会让你对输入和输出变得更加敏感,能提升我们(在日常的工作中)对于异常输入的风险意识,进一步降低bug率。因此如果时间充足的话,我认为每天都应该刷刷题(水题即可),时间比较紧张的话,可以一周刷个3,4道。长此以往,编码能力一定能到达/维持在一个较高的水平。
在我工作初期,编码时考虑的只是把这个问题/需求处理掉,这导致我后来负责的不少模块越来越不可维护... 不过随着大量编码和一些系统设计经历,以及在这过程中遇见的一些问题,也让我逐渐开始对工程实践产生思考,当然工程实践是一个很大的话题,以我的水平难以讲出干货。
1 规范
把规范放在第一点,是因为它很重要,但是又很容易被团队轻视的一个点。我认为团队应该形成共同的规范,并整理出文档,以便在我们在编码和项目管理过程中能时时参考,严格遵守,同时新人入伙时,也应该先学习团队的规范,以确保能写出符合团队风格的代码来。不过非常遗憾的是在我入职初期时没有被教育过,自己的这种想法在当时也还不强烈,因此写出的代码非常腊鸡,给团队留下了毒瘤,直到后面我自己也看不下去了。
1.1 项目管理规范
简单来说,这里其实想谈及的是关于目录的划分和代码的存放位置。一个很常见的点是,很多人都喜欢搭"小金库",其实搭小金库也并没有什么,关键是这样很容易导致同一份代码被拷贝至多处,一是这样会导致代码难以维护,比如需要修复某个bug时,很容易就漏掉了别的"备份",二是冗余的代码文件是对整个项目的一种污染。对于具备通用性的代码库,应该尽可能的存放在公共库路径下,而不是搭建小金库,另一点是存放在公共库路径中的代码应尽可能的具备扩展性,以满足不同的需求,这需要比较深厚的编程功底。
其次是项目目录及其代码文件/库的规范管理,分公共库和其它两点来讲。其它包括一些基础项目(如日志系统,配置系统),cgi,logic服务等,对于其它,我们主要关注的是项目的根目录在整个代码库中的路径,及其子目录划分和对应的代码文件存放。
对于公共库的目录管理及代码文件/库的规范管理,在根据代码的功能将其存放在恰当的路径的前提之下,我一直都有一个想法是这样的:是否可以如同godoc一样,为我们的c++公共库自动创建一份文档。有了这样一份文档将为我们的日常开发提供很大的助力。有这种想法的原因是很早之前使用过一段时间golang,发现利用godoc生成的页面来查询包功能,函数功能非常方便。这里只是提出这种想法,真正要实施起来可能有不少东西都可以参考golang的设计(如利用函数首字母大写表示该函数是给调用者使用的从而导出至生成的页面中,比如注释等)。
1.2 命名风格规范
主要是两点,一是目录的命名规范,二是代码的命名规范,命名风格其实是要跟项目管理规范结合在一起来实施的,这里细的部分就不多谈了,命名规范一方面是为了保证代码风格统一,可读性更佳,其实另一方面也可以减少我们的代码出错率,例如在多层循环中使用i,j,k作为下标时,其实很容易用错下标。当我们对一个变量或者文件进行命名时,需要停顿并思考几秒时,说明已经有效果了。
2 系统设计考量
这里不会涉及到诸如可用性,扩展性,灵活性,可维护性,健壮,可靠等概念,正如文章开头所述,属于入门系列,在这里我将描述一下系统设计时的常规流程(当然这只是个人的学习体会和经验之谈),遵照流程进行设计也许不能帮助你设计出牛逼的系统,但是一定能帮你避免不少坑。
首先要确立一个中心思想,借用之前领导常说的两句话:复杂问题简单化,大系统小做。正如没有最好的架构,只有最合适(匹配业务)的架构,我对这两句话的理解是:通过对业务特性/需求背景的深度理解和把控将复杂问题理顺后进行抽象得到简单,辅以层次->模块->功能的合理划分来设计我们的系统。
在系统设计之初,我们首先需要搞清楚的是需求背景和明细。一方面自然是因为它们本身就是系统的功能点,另一方面我们需要尽可能的提前把握好系统未来要扩展的方向,从而在系统设计中考虑进去。
在清楚了需求背景和明细之后,我们需要做的是了解系统将面临的请求压力。第一步自然是预估其qps数,这里虽然是预估,但也必须有可靠的数据支撑,视情况而定,一般系统设计会以当前容量的2~N倍来设计,主要考量点在于业务的增长速度。接下来需要明确的是,系统是属于cpu型还是io型的服务,内存需求如何,硬盘需求如何等等,网卡流量要求等等,在把系统将面临的压力确认之后便可以开始进行初步设计。
在初步设计阶段,我们需要进行技术选型以及设计系统的整体架构。对于技术选型,我们以数据存储为例,是采用文件存储,还是采用redis,还是mysql,还是mongodb等,各项存储技术对于我们的存储需求的读写性能指标是多少,后续如何扩容,以及对不同技术方案的开发成本/机器成本进行预估,进行综合之后得到我们的存储方案,由于技术选型与系统的整体架构是联系在一起的,基本上有了合适的技术方案时,也就有了对应的系统架构。接下来便进入到详细设计阶段。
在详细设计阶段,我们需要对系统的各个角色的关键部分进行详细的设计,将涉及到的问题和难点一一给出详细的解决方案。比如对于有文件存储需求或是(共享)内存需求的服务,我们需要给出详细的数据存储格式,数据更新写入读取的方式等,以保证该方案的可行性。
在详细设计完毕之后,我们需要计算在设计容量和详细设计方案之下,该系统所需要的硬件资源是多少,并根据硬件资源的总/单机需求来选取合适的机型,最后得到系统所需要的机器数量及型号。
到此一个常规的系统设计流程就结束了。
3 开发->运维
在工作职责上,开发和运维的工作内容有着明显的区分度,但是从工程的角度,开发和运维是紧密联系的,它们对我们的系统服务都是至关重要的。此处我以部署优化为例进行讲解(另一块是系统的运维成本,这在系统设计过程中也需要考虑进去)。
常规的部署优化,如避免单点故障,想必大家都很清楚且容易进行运用,除此之外还有一个非常关键但容易被开发同学忽视的部署问题,跨机架/机房/地域下的机器之间的网络延时。公司的机房之间的通信走的是公司自己搭建的骨干网,即便这样,天津与深圳机房的RTT还是高达几十ms,要是走运营商网络耗时必然倍增。从这组数据,可以认识到以下几点
1 机器不同部署情况下的网络延时甚至能对我们的系统设计方案产生影响,跨地域的机房RTT可能比我们的服务一次请求处理的耗时都要高
2 机器部署优化,可以有效降低系统的整体耗时(进而可能降低失败率),提升服务整体质量
3 用户的就近接入的必要性
4 静态资源上cdn(内容分发网,简单来说就是一群靠近用户网络节点的网络节点)的必要性
3 对于业务系统的整体认识
此节较简单,意在每位开发应该对整个业务系统有较清晰的认识,如从用户发出请求到得到返回需要经过的完整链路,整个业务系统中有哪些角色及各自的功能,这能够让我们更清楚自己设计的系统在整体中的定位,从而考虑更加完备。某种程度上来说,这其实也是要求开发需要对整个产品业务有着较清晰的认识。
4 关于后台框架的实现
后台框架是我们实现网络服务的基石,对于后台框架的理解能够加深我们对于网络服务的掌控力,下面我们从零开始,看看后台框架的实现方案。
依然还是从经典老图出发,让我们回顾一下冯·诺伊曼模型
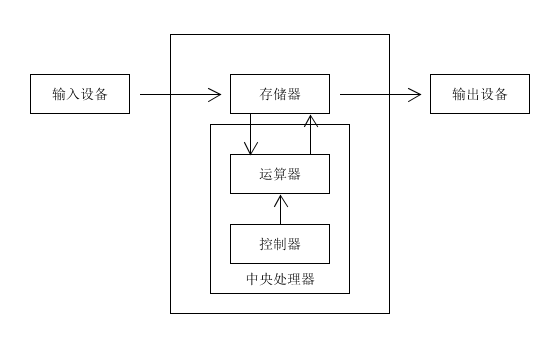
可能读者会疑惑,冯·诺伊曼模型不是计算机的设计理念吗,为什么要放到这里来?我们看下图:
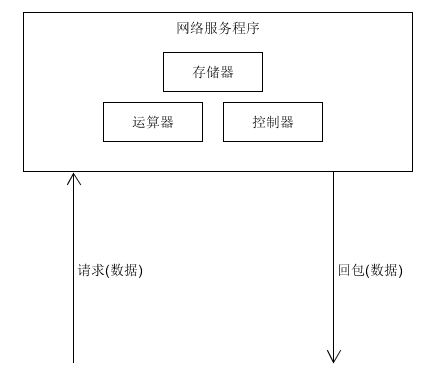
我们的网络服务程序是通过对计算机硬件资源的利用来对数据做加工处理。其核心驱动是什么?是数据。现在我们把硬件元素去掉,看一看常规的网络服务程序的实现模型:
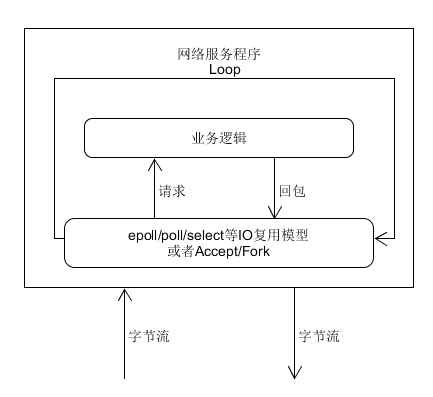
从图中可以认识到:通过IO复用模型,以数据为驱动,执行相关的逻辑。其实这也就是我们后台框架的基础模型了,只不过后台框架是集成了一系列功能模块的程序,如路由模块,日志模块,监控模块等,最后提供人性化的业务逻辑处理接口供开发者使用。
上面的两张图都没有体现进程/线程的概念,不同的后台框架可能会有不同的进程/线程模型,而不同的实现模型自然也会有不同的性能,而评估性能最直截了当的指标就是其对硬件资源的有效利用率,何谓有效利用率?以最简单的Accept-Fork-Exec模型为例,其对硬件资源的有效利用率就非常低,大量的资源浪费在了创建进程/线程和前后的准备工作上。下面我们以使用了IO复用模型,进程/线程均为常驻类型的为例进行讲解,另外,后台框架中都有类似于管理员(Master)的角色(进程/线程),用于对整体后台框架进行监控管理,在这里我们不将其纳入讨论范围。
本质上,我认为后台框架可以分为两类,一类是Proxy And Worker,一类是ProxyWorker。两者的大致结构可以见下图
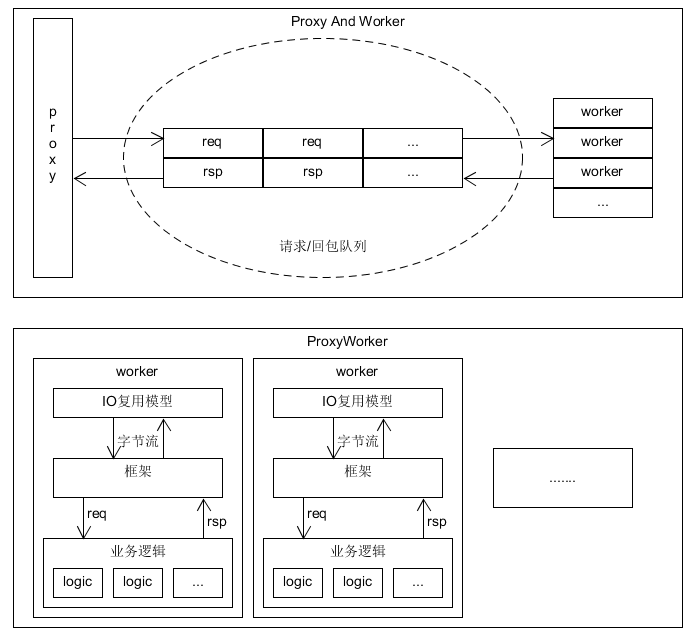
Proxy And Worker类的,其工作模式为有专门的Proxy负责接收请求,待将请求接收完整之后,将请求内容写入请求队列并通知Worker,之后由Worker从队列中取出处理完成后写入回包队列,并通知Proxy,Proxy从回包队列中取出进行回包。
ProxyWorker类的,是将Proxy和Worker的功能集中在了一起,即只有Worker进程,每一个Worker进程既需要监听端口接收请求和回包,也需要处理请求内容。这类后台框架中,典型的就是nginx。
简单分析以下两类框架各自的优劣,对于Proxy And Worker类的,由于Proxy,Worker属于不同的进程,地址空间隔离,因此需要IPC来进行通信,事实上对于请求/回包内容等大数据量的通信,往往都是用的共享内存,因此其至少都会多两次数据拷贝,分别是Proxy到共享内存,再从共享内存到Worker,回包内容则是从worker到共享内存再到proxy。 其次如果Proxy是单进程的,Proxy容易成为程序的性能瓶颈,改良方法自然就是多Proxy。相对的,这种模式下存在以下两种优点,一是由于Proxy负责请求的分发,该模式下对于请求的路由更为可控,可将不同的请求分发给不同类别的Worker(当某类Worker只有一个进程时,则可直接定位到进程,这对提供缓存的服务很有帮助)。二是由于Proxy与Worker分离,整体框架的稳定性较高,即在业务逻辑处理的过程中,部分Worker挂掉了,Proxy不受影响,而Master也可以即时监控到Worker进程异常退出,从而再次拉起Worker进程,在这个过程中,其余Worker没有受到影响。
对于ProxyWorker类的,由于请求监听接收回包与业务逻辑处理同属于一个进程,用的同一片地址空间,因此可以避免掉请求/回包数据的多次拷贝,同时也避免掉了单Proxy的性能瓶颈。从性能上来说,这类框架的性能更加强劲,特别是当运用上协程时,我们可以方便的写出无阻塞操作的代码,此时将每个ProxyWoker进程各自绑定一个cpu核(提升cache命中率),同时提高它们的优先级(进一步将硬件资源有效利用率提升),可以得到最佳的性能,但是这类框架对于请求的路由不可控(因为没有Proxy来分发),无法精确定位到进程,这对缓存类服务的实现带来一定挑战,同时也容易导致请求分配不均匀。在稳定性方面,由于是多进程模型,部分Worker挂掉,依然能提供服务,但是其它Worker进程的负担将会变大,另外正如上面所说请求分配难以均匀,因此稳定性方面稍差。最后是惊群问题,虽然accept的惊群问题已被解决,但是使用IO复用模型后,依然会有惊群问题产生。
由于个人喜好的原因,上面一直没有提到线程,主要是因为我认为对于c
pp类的后台服务而言,多进程+协程是最好的选择,其稳定性/性能都是最佳。(多线程程序的编码难度较大,且由于地址空间共享的原因更容易出错,另外某个线程挂了,整体就挂了)
5 安全
虽然我不是从事安全方面工作的开发,但是我对安全还是持有一定的兴趣。对于安全,我们首先要在脑海里树立一种认知:我们的输入是不可信的。当我们有了这种认知后,我们自然就会在系统设计中将安全考虑进去。
当然毕竟我不是职业做安全的同学,对安全的见解还是比较浅薄的,不过我认为对于开发同学而言,了解了以下两点基本也足够日常应用了。
1 数据安全
数据安全主要是指我们的通信过程是可能被监听的,因此对于敏感的场景,我们需要对通信过程进行加密。在这里,我们需要了解常规加密算法的实现原理,对称加密和非对称加密的区别和优劣,再辅以学习https的通信过程及其设计背后的考量等,这里就不再详述了,网上信息很多。
2 协议安全
协议安全是指在我们的协议设计过程中,需要将安全性考虑进去,设计出安全可靠的协议。以一个简单的例子来说明,比如需要设计一个修改用户昵称的接口,其请求协议如下:
Req {
int64 uid;
string nickname;
} uid即需要被修改的用户的id,nickname为新的昵称。很明显,这个协议是不安全的,用户可以通过这个协议修改任意uid的昵称。如何避免呢?这个场景中的关键点在于我们需要明确操作者是uid本人,因此我们可以这样做:在协议中加上一个access_token字段,该access_token由用户登录后生成(具备时间有效期属性),我们可以根据该access_token换取回uid,再对比请求中的uid是否一致即可确认操作者是否是操作者本人。这里为什么有了access_token后协议里面还需要uid字段呢?从功能角度来看,确实已经没有必要性了,但是我们可以以此监控uid与access_token不一致的请求次数,有必要的话还可以对恶意请求的请求信息进行上报统计打击。
以上是对我在鹅厂两年的编码生涯的一个总结,由于个人水平和认知有限,文中内容也许有不少错误,欢迎指出。
标签:格式 size logs obj software objdump xeon 其它 效果
原文地址:https://www.cnblogs.com/unnamedfish/p/9497232.html