标签:ignore ado apt visual ati 分享图片 different lan The
Link of the Paper: https://arxiv.org/abs/1805.09019
Innovations:
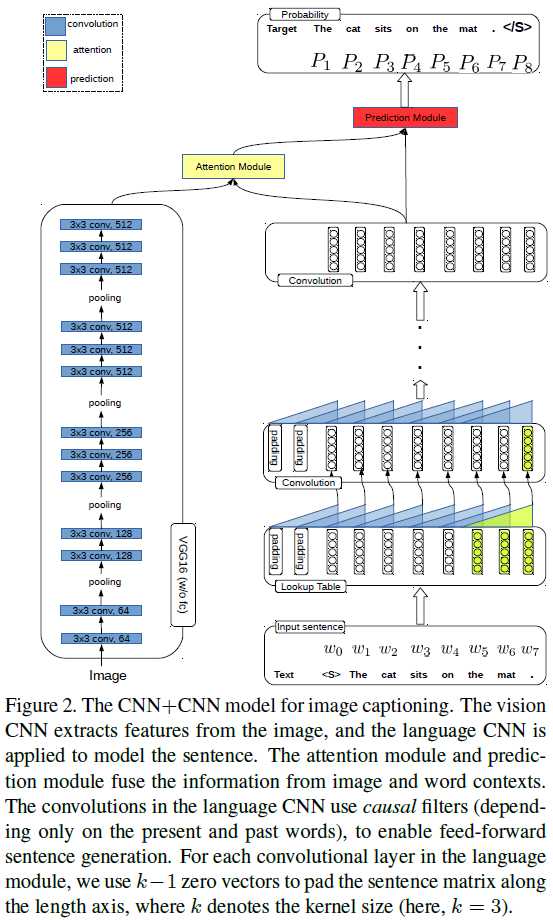
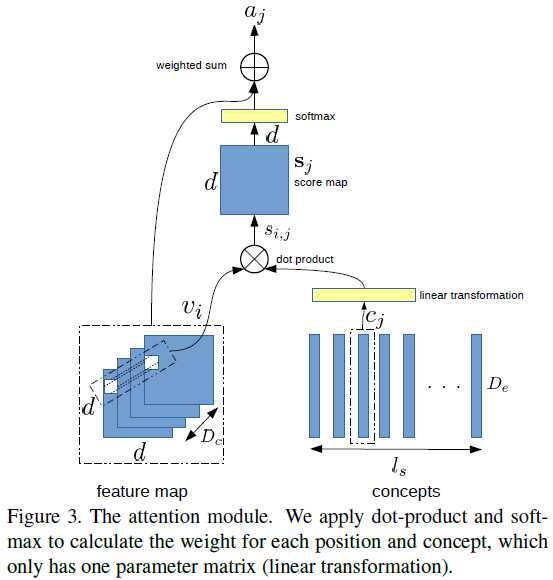
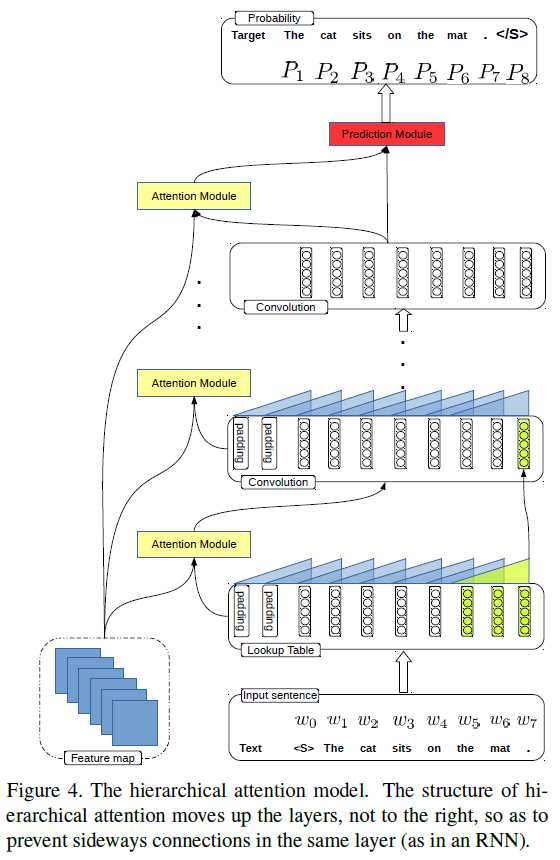
General Points:
Paper Reading - CNN+CNN: Convolutional Decoders for Image Captioning
标签:ignore ado apt visual ati 分享图片 different lan The
原文地址:https://www.cnblogs.com/zlian2016/p/9542632.html