标签:ubantu channels 分享 ack 来源 像素 nsf rand leveldb
在深度学习零率,caffe是一个非常高效的的图像处理框架,结合了nvidia的cuda,cudnn加速技术,非常适合进行AI CNN方向的图像分类,回归,分割等。
但是由于caffe的教程较少,而且配置比较复杂,可能用的人没有tf那么广泛。
昨天在Ubantu14.04上配置了caffe, CUDA8.0, Cudnn5.1等,从今天开始进行caffe的学习记录总结。
跑完make all runtest后,如果运行成功,表示caffe环境配置好了。
首先测试一下minist60000+10000
没问题:
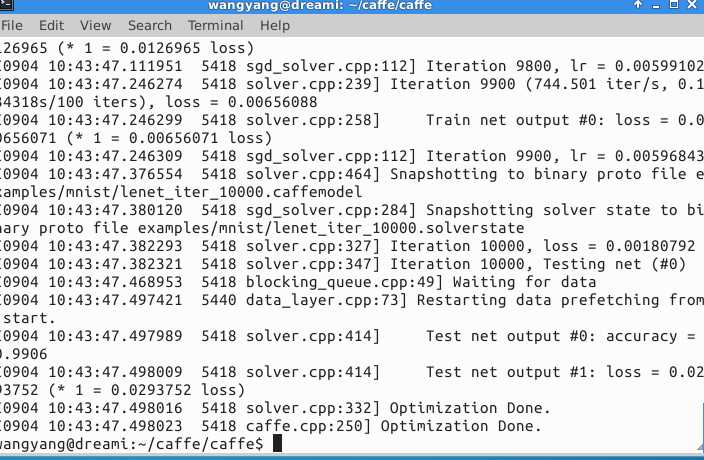
然后用caffe自带的框架测试一下cifar分类。下载一个cifar10的数据。
cd ~caffe的root路径
./data/cifar10/get_cifar10 下载数据
./example/cifar10/create_cifar10.sh
然后
./example/cifar10/train_quick.sh 进行训练
这个时候发现一个error: 5232 db_lmdb.hpp:15] check failed : mdb_status == 0(2 vs. 0) No such file or directory 找不到路径
解决方案:
要运行caffe,首先需要有模型,也就是model,AlexNet,GoogleNet等。由多个layer组成,所有参数定义在caffe.proto中,层之间数据流动是以Blobs的方式进行
比如示例代码:
layer { name: "cifar" type: "Data" top: "data" top: "label" include { phase: TRAIN } transform_param { mean_file: "examples/cifar10/mean.binaryproto" } data_param { source: "examples/cifar10/cifar10_train_lmdb" batch_size: 100 backend: LMDB } }
name: layer name
type: layer type, Data表示数据来源为LevelDB or LMDB
top: 输出层,如果有两个top,则为(data,label)配对模型
bottm: input stuff
include:训练的阶段,实在train 还是test
Transformations: 数据预处理,比如设置scale = 0.00390625,实际是1/255, 讲像素区变为0-1区间
transform_param { scale: 0.00390625 mean_file_size: "examples/cifar10/mean.binaryproto" # 用一个配置文件来进行均值操作 mirror: 1 # 1表示开启镜像,0表示关闭,也可用ture和false来表示 # 剪裁一个 227*227的图块,在训练阶段随机剪裁,在测试阶段从中间裁剪 crop_size: 227 }
1. 数据来源为数据库
data_param部分:
source:数据来源,数据库目录名称
batch_size:批处理数量
可选参数 data param:
rand_skip: SGD use
backend: 采用LevelDB or LMDB, default: leveldb
2.数据来源为内存:
layer { top: "data" top: "label" name: "memory_data" type: "MemoryData" memory_data_param{ batch_size: 2 height: 100 width: 100 channels: 1 } transform_param { scale: 0.0078125 mean_file: "mean.proto" mirror: false } }
3.数据来源为HDF5:
layer { name: "data" type: "HDF5Data" top: "data" top: "label" hdf5_data_param { source: "examples/hdf5_classification/data/train.txt" batch_size: 10 } }
4.数据来源图片:
layer { name: "data" type: "ImageData" top: "data" top: "label" transform_param { mirror: false crop_size: 227 mean_file: "data/ilsvrc12/imagenet_mean.binaryproto" } image_data_param { source: "examples/_temp/file_list.txt" batch_size: 50 new_height: 256 new_width: 256 } }
必须设置的参数:
source: 一个文本文件的名字,每一行给定一个图片文件的名称和标签(label)
batch_size: 每一次处理的数据个数,即图片数
可选参数:
rand_skip: 在开始的时候,路过某个数据的输入。通常对异步的SGD很有用。
shuffle: 随机打乱顺序,默认值为false
new_height,new_width: 如果设置,则将图片进行resize
5.数据来源为windows:
layer { name: "data" type: "WindowData" top: "data" top: "label" include { phase: TRAIN } transform_param { mirror: true crop_size: 227 mean_file: "data/ilsvrc12/imagenet_mean.binaryproto" } window_data_param { source: "examples/finetune_pascal_detection/window_file_2007_trainval.txt" batch_size: 128 fg_threshold: 0.5 bg_threshold: 0.5 fg_fraction: 0.25 context_pad: 16 crop_mode: "warp" } }
标签:ubantu channels 分享 ack 来源 像素 nsf rand leveldb
原文地址:https://www.cnblogs.com/ChrisInsistPy/p/9583040.html