标签:tcp sleep 简单 线程 迁移 使用 富裕 计数 多次
概述
机器负载是否正常,经常需要监控的指标有如下4个:
<1> cpu
<2> memory
<3> IO
<4> network
关于cpu的监控
a. load average,cpu的负载
linux进程的状态分类可以粗略地分为 blocking process, runnable process,running process。分别为等待IO资源,或者自己调用了wait和sleep系列的函数被挂起的进程;所有资源都就位了,就等cpu的进程;正在cpu上跑的进程。cpu的 load average 是根据特定时间段内,runnable process 和 running process 综合统计情况。在单核cpu上,如果 load average 在 0 到 1 之间表示 cpu 还有剩余资源,进程运行通畅。等于1表示系统已经没有剩余的cpu资源了,对于多个进程满打满算刚够用。如果超过1,则说明系统此时正在超负荷运行。load average 一般维持在0.7左右比较好。对于2个cpu核心的机器,那么load average超过2才说明系统正在超负荷运行。其他的以此类推。可以获得 load average 的方法很多,比如
top命令

uptime命令

查看cpu核数

load average 的3个数字展示的分别是1分钟,5分钟,15分钟的统计数据。可以看到我的cpu是24核的,但是 load average 没有达到1,说明cpu资源很富裕,基本没有等待cpu资源的进程,cpu资源永远是等待被使用的。
b. cpu utilization, cpu的利用率
在linux下,cpu的状态可以分为用户态,内核态和空闲态。当cpu运行的是用户的代码时,cpu处于用户态。当代码发生系统调用或者发生其他一些中断时,cpu就会运行内核的代码,此时cpu处于内核态。现在cpu的执行速度是很快的,所以正常情况下,有很大一部分时间内linux系统中所有进程都是被挂起的,这时候cpu会运行系统内的零号进程。这个零号进程在早期是空循环,后来为了节约资源,有了高级电源管理,这个零号进程的主要干的事就是调用高级电源管理相关功能,把cpu主频降下来,降低发热和损耗。cpu运行零号进程时,就处于空闲态。在linux系统中同样存在很多命令去查看特定时间段内,cpu这几种状态所占的比例,
top命令

vmstat命令

cpu utilization 的计算方式是: cpu% = cpu非零号进程的时间 / cpu执行时间的总和。
所以 cpu utilization 展示的是cpu的运行状态。如果 cpu utilization 一直处于100%,说明cpu一直处于用户态或者内核态,没有时间去执行零号进程去降低主频去休息。
cpu utilization 的概念和 cpu load average 很容易混淆。cpu load average 侧重的是cpu资源的争夺情况,比如进程/线程多,但是cpu核数不够使,load average 就会高。cpu utilzation 侧重的是cpu真实地执行逻辑运算的情况。比如现在有100个进程,但是只有1个cpu,但是这100个进程里面有大量的网络IO或者磁盘IO, 在这时 cpu average 会很高,但是 cpu utilzation 不一定高,因为IO只需要cpu执行很少的逻辑运算,大部分时间在等待。举个例子就明白了,比如写了这样一个代码:while(1) { i = i + 1; }, 假设这台机器上只有这样的一个进程,那么只要这个进程起来, cpu utilization 就会飙到很高,因为执行了大量的逻辑运算。但是 cpu load average 反而会很低,因为没有进程等待使用CPU。
c. cpu csr, csr 即 context switch rate, cpu上下文切换率。
上下文切换很好理解。上下文切换本质上就是进程或者线程的切换。发生进程/线程的切换笼统地来说,一般有两种情况,进程的cpu时间片用完了,进程阻塞了或者中断到来了,这时候会发生进程/线程的切换,也就是上下文切换。得到系统每秒上下文切换次数的信息一般用以下放法:
vmstat 1, 表示每1秒采集一次信息,直到手动ctrl-c
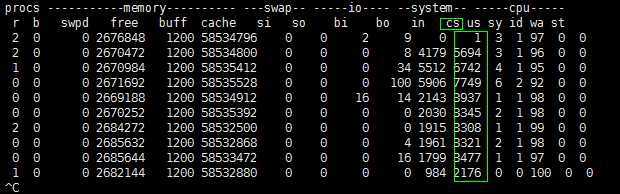
这个值一般情况下越小越好。因为如果这个值很大,cpu cs 很大,说明cpu很多时间都浪费在进程/线程的切换上,而不是执行进程/线程本身的逻辑。
看cpu的资源是否够用一般需要灵活使用这3个参数。
如果sy很高,但是us很低,同时cs较高,则代码此时正在进行大量的系统调用,这个时候要好好考察一下代码逻辑了,是否真的需要那么多次的系统调用,因为很多cpu时间都会浪费到上下文切换中。
再比如,如果只是 cpu cs 很高,但是 cpu utilization 不高,这种情况也是可以接受的。说明有很多进程/线程同时在运行,但是计算密集度并不高,cpu也并没有压力山大。
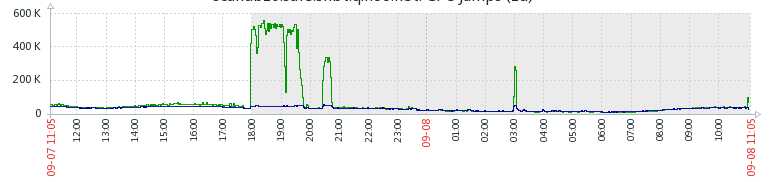
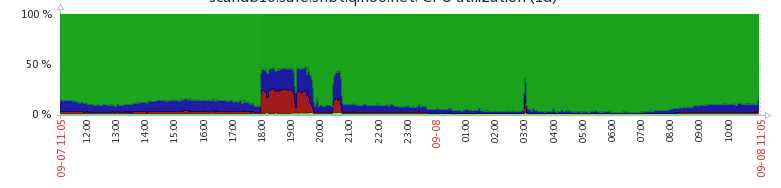
再比如我们线上最近出的一次事故,mysql突然很慢,但是运行的代码逻辑并没有改变。后来查到原因是,增加了这套代码运行的进程个数,导致mysql那台机器上线程数过多,cpu在做疯狂地上下文切换,导致mysql性能降低。从下面的zabbix监控图中也可以看出,平时cs很低,但是增加了进程个数之后,cs突然变得很高,同时 cpu utilization 也变得很高
关于memory的监控
memory主要监控的指标就是剩余内存的量。因为很多代码会发生内存泄漏的问题,这样就会导致代码跑的时间越长,机器内存越少,最后代码因为申请不到内存而停止工作或者直接死掉。
主要使用到的命令是free。
调用free命令会输出如下信息

Mem这一行很容易理解。total就是所有内存,used是已经使用的内存,free是剩余的内存。shared是进程间的共享内存,一般用不到。buffer是已经分配但是未使用的buffer大小。cached也一样,已经分配但是未使用的cache大小。free命令输出的buffer和cache可以这样理解,buffer是内存和块设备之间的速度均衡器,cache是cpu和内存之间的速度均衡器。linux从磁盘读取出来的内容会缓存在内存cache中,如果再用到就不用再从磁盘中读取。buffer会把一些随机的小的IO缓存起来,通过计算形成尽量连续的IO,减少磁盘频繁寻道,提高IO效率。 -/+ buffer/cache这一行就令人费解了。注意,Mem这一行中和-/+buffers/cache这一行中,都是used+free=total。那么-/+ buffer/cache这一行到底怎么理解。如果不深究,有一种比较简单的理解方法:Mem是从系统的角度来看待内存的使用的,used包括分配给应用程序和buffer/cache的物理内存,free就是真真实实没有使用的物理内存。而-/+buffers/cache是从应用程序的角度看的,因为应用程序认为分配给buffer/cache的物理内存如果需要用的话,可以直接回收,所以-/+buffers/cache中的free要比Mem中的free小得多。一般监控-/+buffers/cache这一行,看系统中的内存是否够用。
swap也是一个监控指标,如果swap这一行额used不为0,就说明机器上内存不够用了。这时候就要考虑改进应用程序或者迁移应用程序到内存更大的机器上。
关于IO的监控
一般使用sar命令来查看磁盘的IO性能。
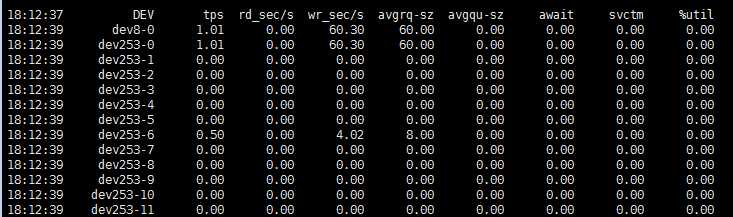
await是一次IO等待的时间,可以近似认为是一次IO的时间,毫秒
svctm是每次IO的操作中,IO操作的服务时间,主要是磁盘性能,并且CPU,内存负载也可能在一定程度上增加svctm的值
util,一秒钟之内有百分之几用于IO操作。
await值的大小一般取决与svctm的值和I/O队列长度以及I/O请求模式,如果svctm的值与await很接近,表示几乎没有I/O等待,磁盘性能很好,如果await的值远高于svctm的值,则表示I/O队列等待太长,系统上运行的应用程序将变慢,此时可以通过更换更快的硬盘来解决问题。
%util项的值也是衡量磁盘I/O的一个重要指标,如果%util接近100%,表示磁盘产生的I/O请求太多,I/O系统已经满负荷的在工作,该磁盘可能存在瓶颈。长期下去,势必影响系统的性能,可以通过优化程序或者通过更换更高、更快的磁盘来解决此问题。参考自:http://88fly.blog.163.com/blog/static/1226803902012514710581/
关于network的监控
关于网络的监控我认为需要注意2点:
1. 写代码的时候需要注意的问题,之前写过这样的一个代码:
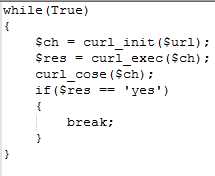
可以注意到,如果$url那边的服务出错,我这边会while死循环 curl_init + curl_close。 但是主动关闭TCP连接会进入TIME_WAIT状态,所以我的机器上就出现了大量TIME_WAIT的socket,直接把机器的文件描述符资源耗尽了。
2. 正儿八经的监控
netstat -lnu

主要看Recv-Q和Send-Q中有没有积压的数据。如果网络状态良好,这两个值一般为0。如果长时间不为0,则可能有问题。如果Recv-Q满了,但是还有人往这个UDP端口发送数据,那么内核就会把接收到的数据丢弃了。UDP也没有重传机制,这样数据就算是丢了,而且对端在UDP这一层毫无感知。或者通过netstat -su, 会输出一个“packet receive errors”的信息,这个信息一般情况下表示的是,网卡收到了,但是应用层没有来得及处理而造成丢的包的个数。
标签:tcp sleep 简单 线程 迁移 使用 富裕 计数 多次
原文地址:https://www.cnblogs.com/MyOnlyBook/p/9610111.html