标签:hdfs 客户端 ted 文件写入 ash 通信 大于 节点 -name
HDFS(Hadoop Distributed FileSystem), 是一种被设计成适合运行在通用硬件上的分布式文件系统。HDFS是一个高度容错性的系统,适合部署在廉价的 机器上。它能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。
HDFS以流式数据访问模式来存储超大文件,运行于普通硬件集群上。
超大文件
“超大文件”,指具有几百MB、几百GB甚至几百TB大小的文件。
流式数据访问
HDFS的构建思路:一次写入、多次读取是最高效的访问模式。每次分析都将涉及对应数据集的大部分数据甚至全部,因此读取整个数据集的时间延迟比读取第一条记录的时间延迟更重要。
普通商用硬件
Hadoo不需要运行在昂贵且高可用的硬件上。它是设计运行在普通商用硬件的集群上的,因此至少对于庞大的集群来说,节点故障的几率还是非常高的。HDFS遇到上述故障时,能够继续运行并且用户不会感觉到明显的中断。
Hadoop目前不适合以下的使用场景:
低时间延迟的数据访问
HDFS是为高数据吞吐量应用优化的,这可能会以提高时间延迟为代价。目前,对于低延迟的访问需求,HBase是更好的选择。
大量的小文件
由于namenode将文件系统的元数据存储在内存中,因此HDFS所能存储的文件总数受限于namenode的内存容量。
多用户写入,任意修改文件
HDFS中的文件写入只支持单个写入者,而且写操作总是以“只添加”的方式在文件末尾写数据。它不支持多个写入者的操作,也不支持在文件的任意位置进行修改。
HDFS上的文件被划分为块大小的多个分块,作为独立的存储单元,称为数据块,默认大小是128MB。与面向单一磁盘的文件系统不同的是,HDFS中小于一个块大小的文件不会占据整个块的空间。
使用数据块的好处是:
一个文件的大小可以大于网络中任意一个磁盘的容量。文件的所有块不需要存储在同一个磁盘上,因此它们可以利用集群上的任意一个磁盘进行存储。
简化了存储子系统的设计,将存储子系统控制单元设置为块,可简化存储管理,同时元数据就不需要和块一同存储,用一个单独的系统就可以管理这些块的元数据。
数据块适合用于数据备份进而提供数据容错能力和提高可用性。
HDFS的块比磁盘的块大,其目的是为了最小化寻址开销。如果块足够大,从磁盘传输数据的时间会明显大于定位这个块开始位置所需的时间。因此,传输一个块组成的大文件的时间取决于磁盘传输速率。
但是,块的大小也不能设置得过大。MapReduce中map任务通常一次只处理一个块中的数据,因此如果任务数太少,作业的运行速度就会比较慢。
HDFS中的fsck指令可以显示块信息:
$ hdfs fsck / -files -blocks Connecting to namenode via http://localhost:50070/fsck?ugi=user11&files=1&blocks=1&path=%2F FSCK started by user11 (auth:SIMPLE) from /127.0.0.1 for path / at Wed May 02 08:54:38 CST 2018 / <dir> /user <dir> /user/user11 <dir> /user/user11/MAC安装包.zip 282524717 bytes, 3 block(s): Under replicated BP-133310625-192.168.199.207-1524790475938:blk_1073741826_1002. Target Replicas is 3 but found 1 live replica(s), 0 decommissioned replica(s), 0 decommissioning replica(s). .... Status: HEALTHY Total size: 282985147 B Total dirs: 3 Total files: 2 Total symlinks: 0 Total blocks (validated): 4 (avg. block size 70746286 B) Minimally replicated blocks: 4 (100.0 %) Over-replicated blocks: 0 (0.0 %) Under-replicated blocks: 4 (100.0 %) Mis-replicated blocks: 0 (0.0 %) Default replication factor: 3 Average block replication: 1.0 Corrupt blocks: 0 Missing replicas: 8 (66.666664 %) Number of data-nodes: 1 Number of racks: 1 FSCK ended at Wed May 02 08:54:38 CST 2018 in 1 milliseconds
HDFS集群有两类节点以管理节点-工作节点模式运行,即一个namenode(管理节点)和datanode(工作节点)。namenode管理文件系统的命名空间,它维护着文件系统树及整棵树内所有的文件和目录。namenode也记录着每个文件中各个块所在的数据节点信息,但它并不永久保存块的位置信息,因为这些信息会在系统启动时根据数据节点信息重建。
datanode是文件系统的工作节点。它们根据需要存储并检索数据块,并且定期向namenode发送它们所存储的块的列表。
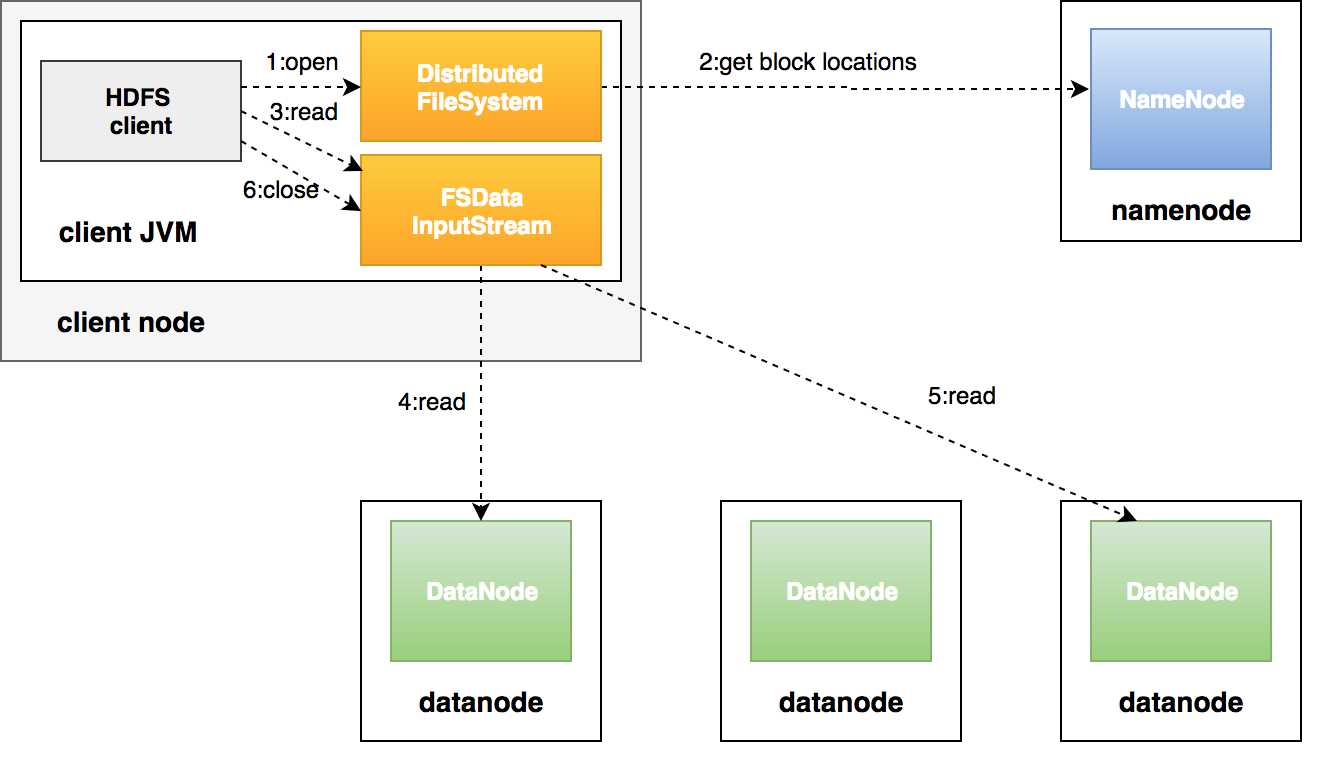
过程描述:
客户端调用FileSystem对象的open()方法在分布式文件系统中打开要读取的文件;
分布式文件系统通过使用RPC(远程过程调用)来调用namenode,确定文件起始块的位置;
分布式文件系统的DistributedFileSystem类返回一个支持文件定位的输入流FSDataInputStream对象,FSDataInputStream对象接着封装DFSInputStream对象(存储着文件起始几个块的datanode地址),客户端对这个输入流调用read()方法;
DFSInputStream连接距离最近的datanode,通过反复调用read方法,将数据从datanode传输到客户端;
到达块的末端时,DFSInputStream关闭与该datanode的连接,寻找下一个块的最佳datanode;
客户端完成读取,对FSDataInputStream调用close()方法关闭连接。
上述过程中的需要注意的地方是:客户端可以直接连接到datanode检索数据,且namenode告知客户端每个块所在的最佳datanode。由于数据流分散在集群中的所有datanode,所以这种设计能使HDFS扩展到大量的并发客户端。
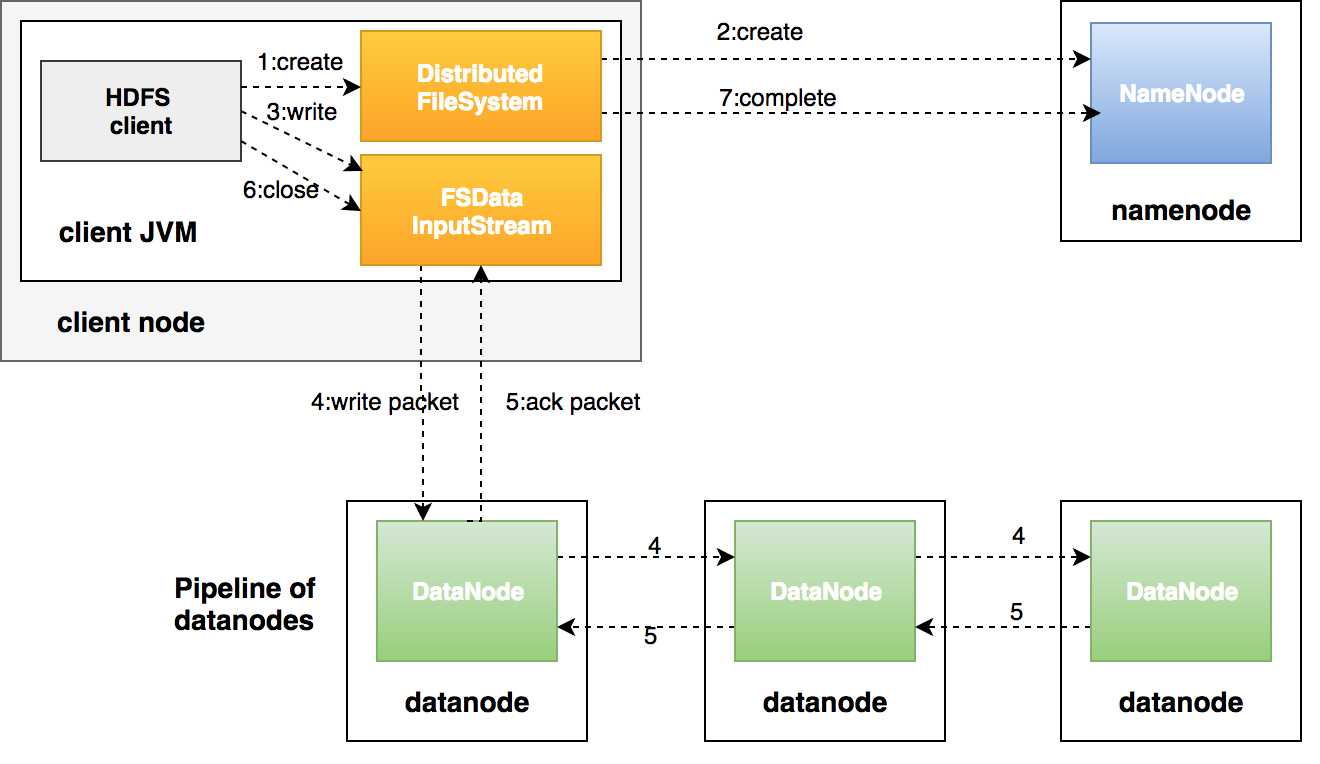
过程描述:
客户端通过对DistributedFileSystem对象调用create()来新建文件;
分布式文件系统对namenod创建一个RPC调用,在文件系统的命名空间中新建一个文件,此时文件中还没有相应的数据块;
Namenode对新建文件进行检查无误后,分布式文件系统返回给客户端一个FSDataOutputStream对象,FSDataOutputStream对象封装一个DFSoutPutstream对象,负责处理namenode和datanode之间的通信;
在客户端写入数据时,FSDataOutputStream将数据分成一个一个的数据包,写入内部队列(数据队列),DataStreamer负责将数据包依次流式传输到由一组datanode构成的管线中;
DFSOutputStream维护着确认队列来等待datanode收到确认回执,收到管道中所有datanode确认后,数据包从确认队列删除;
客户端完成数据的写入,对数据流调用close()方法,该操作将剩余的所有数据包写入datanode管线,并在联系到namenode告知其文件写入完成之前,等待确认;
namenode确认完成。
标签:hdfs 客户端 ted 文件写入 ash 通信 大于 节点 -name
原文地址:https://www.cnblogs.com/pugongying017/p/9616105.html