标签:style blog http color io os 使用 ar java
当我们对于数据结构字段不够确定或杂乱无章很难按一个概念去进行抽取的数据适合用使用什么数据库?答案是什么,如果我们使用的传统数据库,肯定留有多余的字段,10个不行,20个,但是这个严重影响了质量。并且如果面对大数据库,pt级别的数据,这种浪费更是严重的,那么我们该使用是什么数据库?hbase数个不错的选择,那么我们对于hbase还存在下列问题:
8.value 是什么类型?
带着以上几个问题去读下面内容:
引言
团队中使用HBase的项目多了起来,对于业务人员而言,通常并不需要从头搭建、维护一套HBase的集群环境,对于其架构细节也不一定要深刻理解(交由HBase集群维护团队负责),迫切需要的是快速理解基本技术来解决业务问题。最近在XX项目轮岗过程中,尝试着从业务人员视角去看HBase,将一些过程记录下来,期望对快速了解HBase、掌握相关技术来开展工作的业务人员有点帮助。我觉得作为一个初次接触HBase的业务开发测试人员,他需要迫切掌握的至少包含以下几点:
深入理解HTable,掌握如何结合业务设计高性能的HTable
掌握与HBase的交互,反正是离不开数据的增删改查,通过HBase Shell命令及Java Api都是需要的
掌握如何用MapReduce分析HBase里的数据,HBase里的数据总要分析的,用MapReduce是其中一种方式
掌握如何测试HBase MapReduce,总不能光写不管正确性吧,debug是需要的吧,看看如何在本机单测debug吧
本系列将围绕以上几点展开,篇幅较长,如果是HBase初学者建议边读边练,对于HBase比较熟练的,可以选读下,比如关注下HBase的MapReduce及其测试方法。
从一个示例说起
传统的关系型数据库想必大家都不陌生,我们将以一个简单的例子来说明使用RDBMS和HBase各自的解决方式及优缺点。
以博文为例,RDBMS的表设计如下:
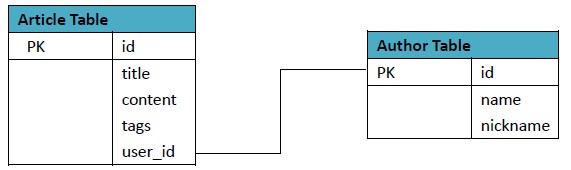
为了方便理解,我们以一些数据示例下
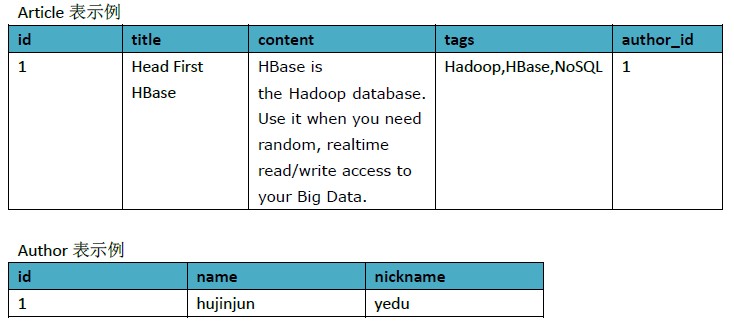
上面的例子,我们用HBase可以按以下方式设计

同样为了方便理解,我们以一些数据示例下,同时用红色标出了一些关键概念,后面会解释
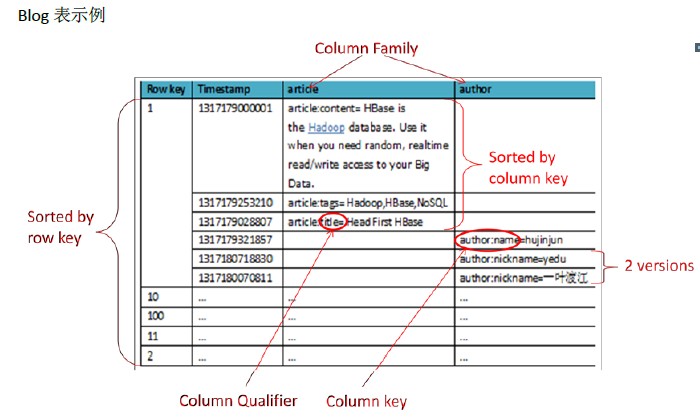
HTable一些基本概念
Row key
行主键,
HBase不支持条件查询和Order by等查询,读取记录只能按Row key(及其range)或全表扫描,因此Row key需要根据业务来设计以利用其存储排序特性(Table按Row key字典序排序如1,10,100,11,2)提高性能。
Column Family(列族)
在表创建时声明,每个Column
Family为一个存储单元。在上例中设计了一个HBase表blog,该表有两个列族:article和author。
Column(列)
HBase的每个列都属于一个列族,以列族名为前缀,如列article:title和article:content属于article列族,author:name和author:nickname属于author列族。
Column不用创建表时定义即可以动态新增,同一Column
Family的Columns会群聚在一个存储单元上,并依Column key排序,因此设计时应将具有相同I/O特性的Column设计在一个Column Family上以提高性能。同时这里需要注意的是:这个列是可以增加和删除的,这和我们的传统数据库很大的区别。所以他适合非结构化数据。
Timestamp
HBase通过row和column确定一份数据,这份数据的值可能有多个版本,不同版本的值按照时间倒序排序,即最新的数据排在最前面,查询时默认返回最新版本。如上例中row
key=1的author:nickname值有两个版本,分别为1317180070811对应的“一叶渡江”和1317180718830对应的“yedu”(对应到实际业务可以理解为在某时刻修改了nickname为yedu,但旧值仍然存在)。Timestamp默认为系统当前时间(精确到毫秒),也可以在写入数据时指定该值。
Value
每个值通过4个键唯一索引,tableName+RowKey+ColumnKey+Timestamp=>value,例如上例中{tableName=’blog’,RowKey=’1’,ColumnName=’author:nickname’,Timestamp=’
1317180718830’}索引到的唯一值是“yedu”。
存储类型
TableName
是字符串
RowKey
和 ColumnName 是二进制值(Java 类型 byte[])
Timestamp
是一个 64 位整数(Java 类型 long)
value
是一个字节数组(Java类型 byte[])。
存储结构
可以简单的将HTable的存储结构理解为

即HTable按Row
key自动排序,每个Row包含任意数量个Columns,Columns之间按Column key自动排序,每个Column包含任意数量个Values。理解该存储结构将有助于查询结果的迭代。
话说什么情况需要HBase
半结构化或非结构化数据
对于数据结构字段不够确定或杂乱无章很难按一个概念去进行抽取的数据适合用HBase。以上面的例子为例,当业务发展需要存储author的email,phone,address信息时RDBMS需要停机维护,而HBase支持动态增加.
记录非常稀疏
RDBMS的行有多少列是固定的,为null的列浪费了存储空间。而如上文提到的,HBase为null的Column不会被存储,这样既节省了空间又提高了读性能。
多版本数据
如上文提到的根据Row
key和Column key定位到的Value可以有任意数量的版本值,因此对于需要存储变动历史记录的数据,用HBase就非常方便了。比如上例中的author的Address是会变动的,业务上一般只需要最新的值,但有时可能需要查询到历史值。
超大数据量
当数据量越来越大,RDBMS数据库撑不住了,就出现了读写分离策略,通过一个Master专门负责写操作,多个Slave负责读操作,服务器成本倍增。随着压力增加,Master撑不住了,这时就要分库了,把关联不大的数据分开部署,一些join查询不能用了,需要借助中间层。随着数据量的进一步增加,一个表的记录越来越大,查询就变得很慢,于是又得搞分表,比如按ID取模分成多个表以减少单个表的记录数。经历过这些事的人都知道过程是多么的折腾。采用HBase就简单了,只需要加机器即可,HBase会自动水平切分扩展,跟Hadoop的无缝集成保障了其数据可靠性(HDFS)和海量数据分析的高性能(MapReduce)。
Hbase学习(五)-hbase常识及habse适合什么场景
标签:style blog http color io os 使用 ar java
原文地址:http://blog.csdn.net/lifuxiangcaohui/article/details/39894265