标签:循环 通过 页面 add class .class config 全文检索 大小
lucene相关:
应用领域:
官方网站:http://lucene.apache.org/
版本:lucene4.10.3
Jdk要求:1.7以上
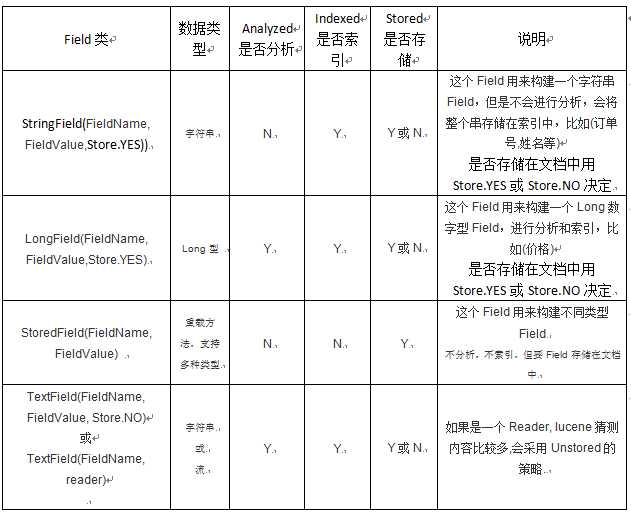
lucene的使用:
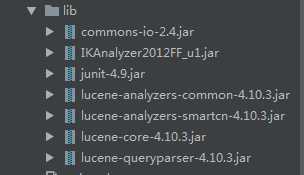
1、导入jar包:
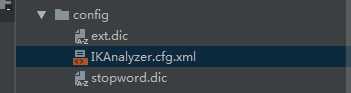
2、这里我们使用的IKAnalyzer分词器,导入相关配置:
3:代码:
新建 IndexManagerTest 类,主要用于新增、删除、修改索引:
1 package com.dengwei.lucene; 2 3 import org.apache.commons.io.FileUtils; 4 import org.apache.lucene.analysis.Analyzer; 5 import org.apache.lucene.document.Document; 6 import org.apache.lucene.document.Field.Store; 7 import org.apache.lucene.document.LongField; 8 import org.apache.lucene.document.TextField; 9 import org.apache.lucene.index.IndexWriter; 10 import org.apache.lucene.index.IndexWriterConfig; 11 import org.apache.lucene.index.Term; 12 import org.apache.lucene.store.Directory; 13 import org.apache.lucene.store.FSDirectory; 14 import org.apache.lucene.util.Version; 15 import org.junit.Test; 16 import org.wltea.analyzer.lucene.IKAnalyzer; 17 18 import java.io.File; 19 import java.util.ArrayList; 20 import java.util.List; 21 22 public class IndexManagerTest { 23 24 /* 25 * testIndexCreate();创建索引,数据来源于txt文件 26 */ 27 @Test 28 public void testIndexCreate() throws Exception{ 29 //创建文档列表,保存多个Docuemnt 30 List<Document> docList = new ArrayList<Document>(); 31 32 //指定txt文件所在目录(需要建立索引的文件) 33 File dir = new File("E:\\searchsource"); 34 //循环文件夹取出文件 35 for(File file : dir.listFiles()){ 36 //文件名称 37 String fileName = file.getName(); 38 //文件内容 39 String fileContext = FileUtils.readFileToString(file); 40 //文件大小 41 Long fileSize = FileUtils.sizeOf(file); 42 43 //文档对象,文件系统中的一个文件就是一个Docuemnt对象 44 Document doc = new Document(); 45 46 //第一个参数:域名 47 //第二个参数:域值 48 //第三个参数:是否存储,是为yes,不存储为no 49 /*TextField nameFiled = new TextField("fileName", fileName, Store.YES); 50 TextField contextFiled = new TextField("fileContext", fileContext, Store.YES); 51 TextField sizeFiled = new TextField("fileSize", fileSize.toString(), Store.YES);*/ 52 53 //是否分词:要,因为它要索引,并且它不是一个整体,分词有意义 54 //是否索引:要,因为要通过它来进行搜索 55 //是否存储:要,因为要直接在页面上显示 56 TextField nameFiled = new TextField("fileName", fileName, Store.YES); 57 58 //是否分词: 要,因为要根据内容进行搜索,并且它分词有意义 59 //是否索引: 要,因为要根据它进行搜索 60 //是否存储: 可以要也可以不要,不存储搜索完内容就提取不出来 61 TextField contextFiled = new TextField("fileContext", fileContext, Store.NO); 62 63 //是否分词: 要, 因为数字要对比,搜索文档的时候可以搜大小, lunene内部对数字进行了分词算法 64 //是否索引: 要, 因为要根据大小进行搜索 65 //是否存储: 要, 因为要显示文档大小 66 LongField sizeFiled = new LongField("fileSize", fileSize, Store.YES); 67 68 //将所有的域都存入文档中 69 doc.add(nameFiled); 70 doc.add(contextFiled); 71 doc.add(sizeFiled); 72 73 //将文档存入文档集合中 74 docList.add(doc); 75 } 76 77 //创建分词器,StandardAnalyzer标准分词器,标准分词器对英文分词效果很好,对中文是单字分词 78 Analyzer analyzer = new IKAnalyzer(); 79 //指定索引和文档存储的目录 80 Directory directory = FSDirectory.open(new File("E:\\dic")); 81 //创建写对象的初始化对象 82 IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer); 83 //创建索引和文档写对象 84 IndexWriter indexWriter = new IndexWriter(directory, config); 85 86 //将文档加入到索引和文档的写对象中 87 for(Document doc : docList){ 88 indexWriter.addDocument(doc); 89 } 90 //提交 91 indexWriter.commit(); 92 //关闭流 93 indexWriter.close(); 94 } 95 96 /* 97 * testIndexDel();删除所有和根据词源进行删除。 98 */ 99 @Test 100 public void testIndexDel() throws Exception{ 101 //创建分词器,StandardAnalyzer标准分词器,标准分词器对英文分词效果很好,对中文是单字分词 102 Analyzer analyzer = new IKAnalyzer(); 103 //指定索引和文档存储的目录 104 Directory directory = FSDirectory.open(new File("E:\\dic")); 105 //创建写对象的初始化对象 106 IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer); 107 //创建索引和文档写对象 108 IndexWriter indexWriter = new IndexWriter(directory, config); 109 110 //删除所有 111 //indexWriter.deleteAll(); 112 113 //根据名称进行删除 114 //Term词元,就是一个词, 第一个参数:域名, 第二个参数:要删除含有此关键词的数据 115 indexWriter.deleteDocuments(new Term("fileName", "apache")); 116 117 //提交 118 indexWriter.commit(); 119 //关闭 120 indexWriter.close(); 121 } 122 123 /** 124 * testIndexUpdate();更新: 125 * 更新就是按照传入的Term进行搜索,如果找到结果那么删除,将更新的内容重新生成一个Document对象 126 * 如果没有搜索到结果,那么将更新的内容直接添加一个新的Document对象 127 * @throws Exception 128 */ 129 @Test 130 public void testIndexUpdate() throws Exception{ 131 //创建分词器,StandardAnalyzer标准分词器,标准分词器对英文分词效果很好,对中文是单字分词 132 Analyzer analyzer = new IKAnalyzer(); 133 //指定索引和文档存储的目录 134 Directory directory = FSDirectory.open(new File("E:\\dic")); 135 //创建写对象的初始化对象 136 IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer); 137 //创建索引和文档写对象 138 IndexWriter indexWriter = new IndexWriter(directory, config); 139 140 141 //根据文件名称进行更新 142 Term term = new Term("fileName", "web"); 143 //更新的对象 144 Document doc = new Document(); 145 doc.add(new TextField("fileName", "xxxxxx", Store.YES)); 146 doc.add(new TextField("fileContext", "think in java xxxxxxx", Store.NO)); 147 doc.add(new LongField("fileSize", 100L, Store.YES)); 148 149 //更新 150 indexWriter.updateDocument(term, doc); 151 152 //提交 153 indexWriter.commit(); 154 //关闭 155 indexWriter.close(); 156 } 157 }
2:新建 IndexSearchTest 类,主要用于搜索索引:
1 package com.dengwei.lucene; 2 3 import java.io.File; 4 5 import org.apache.lucene.analysis.Analyzer; 6 import org.apache.lucene.analysis.standard.StandardAnalyzer; 7 import org.apache.lucene.document.Document; 8 import org.apache.lucene.index.IndexReader; 9 import org.apache.lucene.index.Term; 10 import org.apache.lucene.queryparser.classic.MultiFieldQueryParser; 11 import org.apache.lucene.queryparser.classic.QueryParser; 12 import org.apache.lucene.search.BooleanClause.Occur; 13 import org.apache.lucene.search.BooleanQuery; 14 import org.apache.lucene.search.IndexSearcher; 15 import org.apache.lucene.search.MatchAllDocsQuery; 16 import org.apache.lucene.search.NumericRangeQuery; 17 import org.apache.lucene.search.Query; 18 import org.apache.lucene.search.ScoreDoc; 19 import org.apache.lucene.search.TermQuery; 20 import org.apache.lucene.search.TopDocs; 21 import org.apache.lucene.store.Directory; 22 import org.apache.lucene.store.FSDirectory; 23 import org.junit.Test; 24 import org.wltea.analyzer.lucene.IKAnalyzer; 25 26 public class IndexSearchTest { 27 /* 28 *testIndexSearch() 29 * 根据关键字搜索,并指定默认域 30 */ 31 @Test 32 public void testIndexSearch() throws Exception{ 33 34 //创建分词器(创建索引和所有时所用的分词器必须一致) 35 Analyzer analyzer = new IKAnalyzer(); 36 //创建查询对象,第一个参数:默认搜索域, 第二个参数:分词器 37 //默认搜索域作用:如果搜索语法中指定域名从指定域中搜索,如果搜索时只写了查询关键字,则从默认搜索域中进行搜索 38 QueryParser queryParser = new QueryParser("fileContext", analyzer); 39 //查询语法=域名:搜索的关键字 40 Query query = queryParser.parse("fileName:web"); 41 42 //指定索引和文档的目录 43 Directory dir = FSDirectory.open(new File("E:\\dic")); 44 //索引和文档的读取对象 45 IndexReader indexReader = IndexReader.open(dir); 46 //创建索引的搜索对象 47 IndexSearcher indexSearcher = new IndexSearcher(indexReader); 48 //搜索:第一个参数为查询语句对象, 第二个参数:指定显示多少条 49 TopDocs topdocs = indexSearcher.search(query, 5); 50 //一共搜索到多少条记录 51 System.out.println("=====count=====" + topdocs.totalHits); 52 //从搜索结果对象中获取结果集 53 ScoreDoc[] scoreDocs = topdocs.scoreDocs; 54 55 for(ScoreDoc scoreDoc : scoreDocs){ 56 //获取docID 57 int docID = scoreDoc.doc; 58 //通过文档ID从硬盘中读取出对应的文档 59 Document document = indexReader.document(docID); 60 //get域名可以取出值 打印 61 System.out.println("fileName:" + document.get("fileName")); 62 System.out.println("fileSize:" + document.get("fileSize")); 63 System.out.println("============================================================"); 64 } 65 66 } 67 68 /* 69 *testIndexTermQuery() 70 * 根据关键字进行搜索,需要指定域名,和上面的对比起来,更推荐 71 * 使用上面的(可以指定默认域名的) 72 */ 73 74 @Test 75 public void testIndexTermQuery() throws Exception{ 76 //创建分词器(创建索引和所有时所用的分词器必须一致) 77 Analyzer analyzer = new IKAnalyzer(); 78 //创建词元:就是词, 79 Term term = new Term("fileName", "apache"); 80 //使用TermQuery查询,根据term对象进行查询 81 TermQuery termQuery = new TermQuery(term); 82 83 84 //指定索引和文档的目录 85 Directory dir = FSDirectory.open(new File("E:\\dic")); 86 //索引和文档的读取对象 87 IndexReader indexReader = IndexReader.open(dir); 88 //创建索引的搜索对象 89 IndexSearcher indexSearcher = new IndexSearcher(indexReader); 90 //搜索:第一个参数为查询语句对象, 第二个参数:指定显示多少条 91 TopDocs topdocs = indexSearcher.search(termQuery, 5); 92 //一共搜索到多少条记录 93 System.out.println("=====count=====" + topdocs.totalHits); 94 //从搜索结果对象中获取结果集 95 ScoreDoc[] scoreDocs = topdocs.scoreDocs; 96 97 for(ScoreDoc scoreDoc : scoreDocs){ 98 //获取docID 99 int docID = scoreDoc.doc; 100 //通过文档ID从硬盘中读取出对应的文档 101 Document document = indexReader.document(docID); 102 //get域名可以取出值 打印 103 System.out.println("fileName:" + document.get("fileName")); 104 System.out.println("fileSize:" + document.get("fileSize")); 105 System.out.println("============================================================"); 106 } 107 } 108 109 /* 110 *testNumericRangeQuery(); 111 * 用于搜索价格、大小等数值区间 112 */ 113 @Test 114 public void testNumericRangeQuery() throws Exception{ 115 //创建分词器(创建索引和所有时所用的分词器必须一致) 116 Analyzer analyzer = new IKAnalyzer(); 117 118 //根据数字范围查询 119 //查询文件大小,大于100 小于1000的文章 120 //第一个参数:域名 第二个参数:最小值, 第三个参数:最大值, 第四个参数:是否包含最小值, 第五个参数:是否包含最大值 121 Query query = NumericRangeQuery.newLongRange("fileSize", 100L, 1000L, true, true); 122 123 //指定索引和文档的目录 124 Directory dir = FSDirectory.open(new File("E:\\dic")); 125 //索引和文档的读取对象 126 IndexReader indexReader = IndexReader.open(dir); 127 //创建索引的搜索对象 128 IndexSearcher indexSearcher = new IndexSearcher(indexReader); 129 //搜索:第一个参数为查询语句对象, 第二个参数:指定显示多少条 130 TopDocs topdocs = indexSearcher.search(query, 5); 131 //一共搜索到多少条记录 132 System.out.println("=====count=====" + topdocs.totalHits); 133 //从搜索结果对象中获取结果集 134 ScoreDoc[] scoreDocs = topdocs.scoreDocs; 135 136 for(ScoreDoc scoreDoc : scoreDocs){ 137 //获取docID 138 int docID = scoreDoc.doc; 139 //通过文档ID从硬盘中读取出对应的文档 140 Document document = indexReader.document(docID); 141 //get域名可以取出值 打印 142 System.out.println("fileName:" + document.get("fileName")); 143 System.out.println("fileSize:" + document.get("fileSize")); 144 System.out.println("============================================================"); 145 } 146 } 147 148 /* 149 *testBooleanQuery(); 150 * 组合查询,可以根据多条件进行查询 151 */ 152 @Test 153 public void testBooleanQuery() throws Exception{ 154 //创建分词器(创建索引和所有时所用的分词器必须一致) 155 Analyzer analyzer = new IKAnalyzer(); 156 157 //布尔查询,就是可以根据多个条件组合进行查询 158 //文件名称包含apache的,并且文件大小大于等于100 小于等于1000字节的文章 159 BooleanQuery query = new BooleanQuery(); 160 161 //根据数字范围查询 162 //查询文件大小,大于100 小于1000的文章 163 //第一个参数:域名 第二个参数:最小值, 第三个参数:最大值, 第四个参数:是否包含最小值, 第五个参数:是否包含最大值 164 Query numericQuery = NumericRangeQuery.newLongRange("fileSize", 100L, 1000L, true, true); 165 166 //创建词元:就是词, 167 Term term = new Term("fileName", "apache"); 168 //使用TermQuery查询,根据term对象进行查询 169 TermQuery termQuery = new TermQuery(term); 170 171 //Occur是逻辑条件 172 //must相当于and关键字,是并且的意思 173 //should,相当于or关键字或者的意思 174 //must_not相当于not关键字, 非的意思 175 //注意:单独使用must_not 或者 独自使用must_not没有任何意义 176 query.add(termQuery, Occur.MUST); 177 query.add(numericQuery, Occur.MUST); 178 179 //指定索引和文档的目录 180 Directory dir = FSDirectory.open(new File("E:\\dic")); 181 //索引和文档的读取对象 182 IndexReader indexReader = IndexReader.open(dir); 183 //创建索引的搜索对象 184 IndexSearcher indexSearcher = new IndexSearcher(indexReader); 185 //搜索:第一个参数为查询语句对象, 第二个参数:指定显示多少条 186 TopDocs topdocs = indexSearcher.search(query, 5); 187 //一共搜索到多少条记录 188 System.out.println("=====count=====" + topdocs.totalHits); 189 //从搜索结果对象中获取结果集 190 ScoreDoc[] scoreDocs = topdocs.scoreDocs; 191 192 for(ScoreDoc scoreDoc : scoreDocs){ 193 //获取docID 194 int docID = scoreDoc.doc; 195 //通过文档ID从硬盘中读取出对应的文档 196 Document document = indexReader.document(docID); 197 //get域名可以取出值 打印 198 System.out.println("fileName:" + document.get("fileName")); 199 System.out.println("fileSize:" + document.get("fileSize")); 200 System.out.println("============================================================"); 201 } 202 } 203 204 /* 205 *testMathAllQuery(); 206 * 查询所有: 207 */ 208 @Test 209 public void testMathAllQuery() throws Exception{ 210 //创建分词器(创建索引和所有时所用的分词器必须一致) 211 Analyzer analyzer = new IKAnalyzer(); 212 213 //查询所有文档 214 MatchAllDocsQuery query = new MatchAllDocsQuery(); 215 216 //指定索引和文档的目录 217 Directory dir = FSDirectory.open(new File("E:\\dic")); 218 //索引和文档的读取对象 219 IndexReader indexReader = IndexReader.open(dir); 220 //创建索引的搜索对象 221 IndexSearcher indexSearcher = new IndexSearcher(indexReader); 222 //搜索:第一个参数为查询语句对象, 第二个参数:指定显示多少条 223 TopDocs topdocs = indexSearcher.search(query, 5); 224 //一共搜索到多少条记录 225 System.out.println("=====count=====" + topdocs.totalHits); 226 //从搜索结果对象中获取结果集 227 ScoreDoc[] scoreDocs = topdocs.scoreDocs; 228 229 for(ScoreDoc scoreDoc : scoreDocs){ 230 //获取docID 231 int docID = scoreDoc.doc; 232 //通过文档ID从硬盘中读取出对应的文档 233 Document document = indexReader.document(docID); 234 //get域名可以取出值 打印 235 System.out.println("fileName:" + document.get("fileName")); 236 System.out.println("fileSize:" + document.get("fileSize")); 237 System.out.println("============================================================"); 238 } 239 } 240 241 /* 242 *testMultiFieldQueryParser(); 243 * 从多个域中进行查询 244 */ 245 @Test 246 public void testMultiFieldQueryParser() throws Exception{ 247 //创建分词器(创建索引和所有时所用的分词器必须一致) 248 Analyzer analyzer = new IKAnalyzer(); 249 250 String [] fields = {"fileName","fileContext"}; 251 //从文件名称和文件内容中查询,只有含有apache的就查出来 252 MultiFieldQueryParser multiQuery = new MultiFieldQueryParser(fields, analyzer); 253 //输入需要搜索的关键字 254 Query query = multiQuery.parse("apache"); 255 256 //指定索引和文档的目录 257 Directory dir = FSDirectory.open(new File("E:\\dic")); 258 //索引和文档的读取对象 259 IndexReader indexReader = IndexReader.open(dir); 260 //创建索引的搜索对象 261 IndexSearcher indexSearcher = new IndexSearcher(indexReader); 262 //搜索:第一个参数为查询语句对象, 第二个参数:指定显示多少条 263 TopDocs topdocs = indexSearcher.search(query, 5); 264 //一共搜索到多少条记录 265 System.out.println("=====count=====" + topdocs.totalHits); 266 //从搜索结果对象中获取结果集 267 ScoreDoc[] scoreDocs = topdocs.scoreDocs; 268 269 for(ScoreDoc scoreDoc : scoreDocs){ 270 //获取docID 271 int docID = scoreDoc.doc; 272 //通过文档ID从硬盘中读取出对应的文档 273 Document document = indexReader.document(docID); 274 //get域名可以取出值 打印 275 System.out.println("fileName:" + document.get("fileName")); 276 System.out.println("fileSize:" + document.get("fileSize")); 277 System.out.println("============================================================"); 278 } 279 } 280 }
标签:循环 通过 页面 add class .class config 全文检索 大小
原文地址:https://www.cnblogs.com/dw3306/p/9655331.html