标签:code XML last 占用 mys 序列 .sh utf-8 对比
Elastic-Job是当当网大牛基于Zookepper,Quartz开发并且开源的Java分布式定时任务,解决Quartz不支持分布式的弊端。它由两个相互独立的子项目Elastic-Job-Lite和Elastic-Job-Cloud组成。
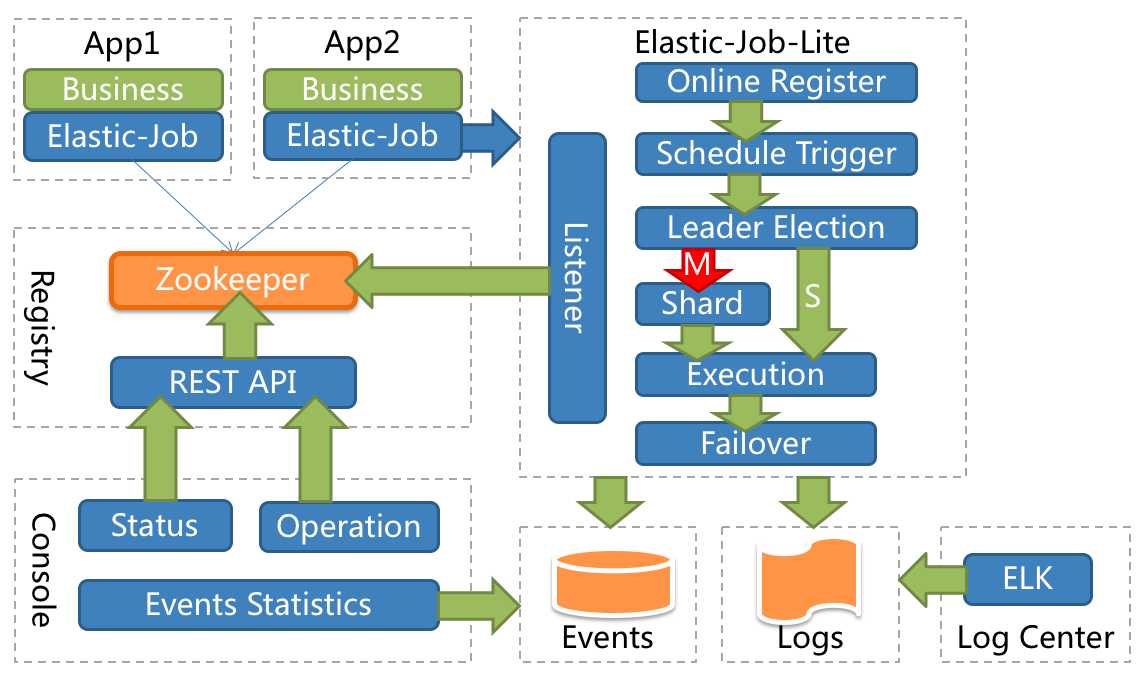
Elastic-Job采用去中心化设计,主要分为注册中心、数据分片、分布式协调、定时任务处理和定制化流程型任务等模块。
| 中心化 | 去中心化 | |
| 实现难度 | 难 | 易 |
| 部署难度 | 难 | 易 |
| 触发时间统一控制 | 可以 | 不可以 |
| 触发延迟 | 有 | 无 |
| 异构语言支持 | 容易 | 困难 |
Elastic-Job提供Simple、Dataflow和Script 3种作业类型。方法参数shardingContext包含作业配置、片和运行时信息。可通过getShardingTotalCount(), getShardingItem()等方法分别获取分片总数,运行在本作业服务器的分片序列号等。
<!-- 引入elastic-job-lite核心模块 -->
<dependency>
<groupId>io.elasticjob</groupId>
<artifactId>elastic-job-lite-core</artifactId>
<version>${latest.release.version}</version>
</dependency>
<!-- 使用springframework自定义命名空间时引入 -->
<dependency>
<groupId>io.elasticjob</groupId>
<artifactId>elastic-job-lite-spring</artifactId>
<version>${latest.release.version}</version>
</dependency>
Elasti-Job配置分成3个层级,Core, Type和Root。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:reg="http://www.dangdang.com/schema/ddframe/reg"
xmlns:job="http://www.dangdang.com/schema/ddframe/job"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.dangdang.com/schema/ddframe/reg
http://www.dangdang.com/schema/ddframe/reg/reg.xsd
http://www.dangdang.com/schema/ddframe/job
http://www.dangdang.com/schema/ddframe/job/job.xsd
">
<!--配置作业注册中心-->
<reg:zookeeper id="regCenter" server-lists="127.0.0.1:2181" namespace="dd-job" base-sleep-time-milliseconds="1000" max-sleep-time-milliseconds="3000" max-retries="3" />
<!-- 配置简单作业-->
<job:simple id="simpleElasticJob" class="xxx.MySimpleElasticJob" registry-center-ref="regCenter" cron="0/10 * * * * ?" sharding-total-count="3" sharding-item-parameters="0=A,1=B,2=C" />
<bean id="yourRefJobBeanId" class="xxx.MySimpleRefElasticJob">
<property name="fooService" ref="xxx.FooService"/>
</bean>
<!-- 配置关联Bean作业-->
<job:simple id="simpleRefElasticJob" job-ref="yourRefJobBeanId" registry-center-ref="regCenter" cron="0/10 * * * * ?" sharding-total-count="3" sharding-item-parameters="0=A,1=B,2=C" />
<!-- 配置数据流作业-->
<job:dataflow id="throughputDataflow" class="xxx.MyThroughputDataflowElasticJob" registry-center-ref="regCenter" cron="0/10 * * * * ?" sharding-total-count="3" sharding-item-parameters="0=A,1=B,2=C" />
<!-- 配置脚本作业-->
<job:script id="scriptElasticJob" registry-center-ref="regCenter" cron="0/10 * * * * ?" sharding-total-count="3" sharding-item-parameters="0=A,1=B,2=C" script-command-line="/your/file/path/demo.sh" />
<!-- 配置带监听的简单作业-->
<job:simple id="listenerElasticJob" class="xxx.MySimpleListenerElasticJob" registry-center-ref="regCenter" cron="0/10 * * * * ?" sharding-total-count="3" sharding-item-parameters="0=A,1=B,2=C">
<job:listener class="xx.MySimpleJobListener"/>
<job:distributed-listener class="xx.MyOnceSimpleJobListener" started-timeout-milliseconds="1000" completed-timeout-milliseconds="2000" />
</job:simple>
<!-- 配置带作业数据库事件追踪的简单作业-->
<job:simple id="eventTraceElasticJob" class="xxx.MySimpleListenerElasticJob" registry-center-ref="regCenter" cron="0/10 * * * * ?" sharding-total-count="3" sharding-item-parameters="0=A,1=B,2=C" event-trace-rdb-data-source="yourDataSource">
</job:simple>
</beans>
补充:启动zookepper,通过spring启动配置,作业就能加载。
标签:code XML last 占用 mys 序列 .sh utf-8 对比
原文地址:https://www.cnblogs.com/yushangzuiyue/p/9655847.html