标签:不重复 hello 国外 disjoint 图解 value 方法 字符串 items
一、 数字类型
1.1 整型int
1、用途: 记录年龄\等级\各种号码
2、定义方式:

age=18
age=int(18)
x=int(‘123‘) #只能将纯数字的字符串转换成整型
print(type(x))
print(int(3.7)) #这个小数部分没有了
3、常用操作+内置的方法 ( 赋值\比较\算术)
该类型总结: 存一个值 ; 不可变(1、可变:值变,id不变。可变==不可hash 2、不可变:值变,id就变。不可变==可hash)
判断是否哈希
print(hash(10))
print(hash([1,2,3]))
1.2 浮点型float
1、用途: 记录身高\体重\薪资
2、定义方式
salary=1.3
#salary=float(1.3)
x=float(‘3.1‘)
print(x,type(x))
1.3、常用操作+内置的方法
赋值\比较\算术
该类型总结: 存一个值 ; 不可变(1、可变:值变,id不变。可变==不可hash 2、不可变:值变,id就变。不可变==可hash)
x=3.1
print(id(x))
x=3.2
print(id(x))
了解:
#复数
x=1-2j
print(x,type(x))
print(x.real)
print(x.imag)
#长整型
#不常见,知道有这个东西就行,至于到哪一位属于长整形,没必要了解
其他进制=>十进制
十进制: 0-9
11 = 1*10^1 + 1*10^0
二进制: 0 1
11 = 1*2^1 + 1*2^0
八进制: 0-7
11 = 1*8^1+1*8^0
十六进制:0-9 A-F
11 = 1*16^1+1*16^0
十进制=>其他进制
print(bin(13)) # 十进制=>二进制
print(oct(13)) # 十进制=>八进制
print(hex(13)) # 十进制=>十六进制
二 、字符串类型
2.1、基本使用
1、用途:记录描述性质的特征,比如名字\地址\性别
2、定义方式:在单引号\双引号\三引号内包含的一串字符
msg=‘aaa"bbb"‘
#msg=str(...)
可以将任意类型转换成字符串
str(1)
str(1.3)
x=str([1,2,3])
print(x,type(x))
3、常用操作+内置的方法
#strip 方法用于移除字符串头尾指定的字符(默认为空格)。
#str.strip([chars]);
# chars移除字符串头尾指定的字符。 这是一个包含的关系
name = "*joker**"
print(name.strip("*"))
print(name.lstrip("*")) #去除左边
print(name.rstrip("*")) #去除右边
#长度len
msg=‘你好啊a‘
print(len(msg))
#成员运算in和not in
msg=‘yangyuanhu 老师是一个非常虎的老师‘
print(‘yangyuanhu‘ in msg)
print(‘虎‘ not in msg)
print(not ‘虎‘ in msg)
#format的三种玩法
print(‘my name is %s my age is %s‘ %(‘egon‘,18))
print(‘my name is %s my age is %s‘ %(18,‘egon‘))
print(‘my name is {name} my age is {age} ‘.format(age=18,name=‘egon‘))
了解
print(‘my name is {} my age is {} ‘.format(18,‘egon‘))
print(‘my name is {0} my age is {1} ‘.format(18,‘egon‘))
print(‘my name is {1} my age is {0} ‘.format(18,‘egon‘))
#startswith,endswith
name = "joker_li"
print(name.endswith("li")) #是否以什么结尾
print(name.startswith("joker")) #是否以什么开头
#replace
name = "joker is good joker boy!"
print(name.replace(‘joker‘,‘li‘)) #所有joker替换li
print(name.replace(‘joker‘,‘li‘,1)) #从左到右替换1次
#find,rfind,index,rindex,count
name = ‘jokerk say hi‘
print(name.find(‘s‘)) #字符串也是可以切片找不到则返回-1不会报错,找到了则显示索引
print(name.count(‘k‘)) #统计包含有多少个
#split
name = ‘root:x:0:0::/root/:bin/bash‘
print(name.split(‘:‘)) #默认分隔符为空格
name = ‘c:/a/b/c/d.txt‘ #想拿到顶级目录
print(name.split(‘/‘,1)) #按多少次切片,从左边
name = ‘a|b|c‘
print(name.rsplit(‘|‘,1)) #按多少次切片,从右边
#join
tag = ‘ ‘
print(tag.join([‘joker‘,‘li‘,‘good‘,‘boy‘])) #可迭代对象必须都是字符串
#也就是说这个方法是将列表转换为字符串,如果tag有变量的话,就会循环加
#center,ljust,rjust,zfill
name = ‘joker‘
print(name.center(10,‘_‘)) #不够10个字符,用_补齐
print(name.ljust(10,‘*‘)) #左对齐
print(name.rjust(10,‘*‘)) #右对齐,注意这个引号内只能是一个字符
print(name.zfill(10)) #右对齐,用0补齐就是
#expandtabs
name = ‘joker\thello‘
print(name)
print(name.expandtabs(4)) #expand扩张的意思,就是将tab建转为多少个空格
#lower,upper
name = ‘joker‘
print(name.lower()) #大写变小写,如果本来就是小写,那就没变化
print(name.upper()) #小写变大写,如果本来就是大写,那就没变化
#capitalize,swapcase,title
name = ‘joker li‘
print(name.capitalize()) #首字母大写
print(name.swapcase()) #大小写对调
print(name.title()) #每个单词的首字母大写
#is数字系列
num1 = b‘4‘ #bytes 类型
print(type(num1))
num2 = u‘4‘ #unicode类型,在3里默认就是这个类型
print(type(num2))
num3 = ‘四‘ #中文数字
num4 = ‘Ⅳ‘ #罗马数字
#isdigt,bytes,unicode
print(num1.isdigit()) #是不是一个整数数字,如果是浮点数就会False
print(num2.isdigit())
print(num3.isdigit()) #False
print(num4.isdigit()) #罗马数字 False ,不是一个整数
#isdecimal,uncicode
#bytes类型无isdecimal方法
print(num2.isdecimal()) #检查字符串是否只包含十进制字符。这种方法只存在于unicode对象
#注意:定义一个十进制字符串,只需要在字符串前添加 ‘u‘ 前缀即可
print(num3.isdecimal())
print(num4.isdecimal())
#isnumberic:unicode,中文数字,罗马数字
#bytes类型无isnumberic方法
print(num2.isnumeric()) #判断是不是数字,包括中文大写数字,罗马数字等
print(num3.isnumeric())
print(num4.isnumeric())
#三者不能判断浮点数
num5=‘4.3‘ #全是false
print(num5.isdigit())
print(num5.isdecimal())
print(num5.isnumeric())
# 最常用的是isdigit,可以判断bytes和unicode类型,这也是最常见的数字应用场景
# 如果要判断中文数字或罗马数字,则需要用到isnumeric
了解的操作
#find,rfind,index,rindex,count
msg=‘hello worldaa‘
print(msg.index(‘wo‘))
print(msg.index(‘wo‘,0,3))
print(msg.find(‘wo‘,0,3))
print(msg.find(‘xxxxxxx‘))
print(msg.index(‘xxxxxxx‘))
print(msg.count(‘l‘))
#center,ljust,rjust,zfill
name=input(‘>>: ‘).strip()
print(‘egon‘.center(50,‘=‘))
print((‘%s‘ %name).center(50,‘-‘))
print(‘egon‘.ljust(50,‘=‘))
print(‘egon‘.rjust(50,‘=‘))
print(‘egon‘.zfill(50))
#expandtabs
print(‘hello\tworld‘.expandtabs(5))
#captalize,swapcase,title
print(‘hello world‘.capitalize())
print(‘Hello world‘.swapcase())
print(‘Hello world‘.title())
#is
print(‘===>‘)
name=‘joker123‘
print(name.isalnum()) #字符串由字母和数字组成
print(name.isalpha()) #字符串只由字母组成
print(name.isidentifier()) #判断是不是一个合法的表示符
print(name.islower()) #判断是不是小写
print(name.isupper()) #是不是大写
print(name.isspace()) #判断是不是空格
print(name.istitle()) #每个单词字母首字母大小
该类型总结:存一个值 ;有序 ; 不可变(1、可变:值变,id不变。可变==不可hash 2、不可变:值变,id就变。不可变==可hash)
三、列表类型
3.1、基本使用
1、用途:记录多个值,比如人的多个爱好
2、定义方式: 在[]内用逗号分隔开多个任意类型的值
li=[1,2,3] # li=list([1,2,3])
x=list(‘hello‘)
x=list({‘a‘:1,‘b‘:2,‘c‘:3})
print(x)
3.2、常用操作+内置的方法
1、按索引存取值(正向存取+反向存取):即可存也可以取
li=[‘a‘,‘b‘,‘c‘,‘d‘]
print(li[-1])
li[-1]=‘D‘
print(li)
li[4]=‘e‘
del li[0]
print(li)
2、切片(顾头不顾尾,步长)
li=[‘a‘,‘b‘,‘c‘,‘d‘]
print(li[0:3])
3、长度
print(len(li))
4、成员运算 in 和 not in
users=[‘egon‘,‘lxx‘,‘yxx‘,‘cxxx‘,[1,2,3]]
print(‘lxx‘ in users)
print([1,2,3] in users)
print(1 in users)
5、追加
li=[‘a‘,‘b‘,‘c‘,‘d‘]
print(id(li))
li.append(‘e‘)
li.append([1,2,3])
print(li,id(li))
6、删除
li=[‘a‘,‘b‘,‘c‘,‘d‘]
#按照元素值去单纯地删除某个元素
del li[1]
res=li.remove(‘c‘)
print(li)
print(res)
#按照元素的索引去删除某个元素并且拿到该元素作为返回值
res=li.pop(1)
print(li)
print(res)
7、循环
li=[‘a‘,‘b‘,‘c‘,‘d‘]
for item in li:
print(item)
该类型总结:存多个值 ;有序 ; 可变(1、可变:值变,id不变。可变==不可hash 2、不可变:值变,id就变。不可变==可hash)
print(hash([1,2,3]))
列表常用方法:
li=[‘a‘,‘b‘,‘c‘,‘d‘,‘c‘,‘e‘]
print(li.count(‘c‘)) #计算li中字符c的个数
li.extend([1,2,3]) #把括号里列表里的元素添加到li
li.append([1,2,3]) #把括号里的列表增加到列表末尾
print(li)
print(li.index(‘z‘)) #打印出z的索引值
print(li.index(‘b‘))
print(li.index(‘d‘,0,3))
li.insert(1,‘egon‘) #在索引值1处插入字符串egon
print(li)
li=[3,1,9,11]
li.reverse() #翻转列表的顺序
print(li)
li.sort(reverse=True) #按照数字或字母顺序排序
print(li)
练习,模拟堆栈和队列
队列: 先进先出
q=[]
入队
q.append(‘first‘)
q.append(‘second‘)
q.append(‘third‘)
print(q)
出队
print(q.pop(0))
print(q.pop(0))
print(q.pop(0))
堆栈: 先进后出
q=[]
入栈
q.append(‘first‘)
q.append(‘second‘)
q.append(‘third‘)
出栈
print(q.pop(-1))
print(q.pop(-1))
print(q.pop(-1))
四 元组类型
元组其实跟列表差不多,也是存一组数,只不是它一旦创建,便不能再修改,所以又叫只读列表,用于存放多个值,当存放的多个值只有读的需求没有改的需求时用元组最合适
定义方式 : 在()内用逗号分隔开多个任意类型的值
t=(1,3.1,‘aaa‘,(1,2,3),[‘a‘,‘b‘]) # t=tuple(...)
print(type(t))
res=tuple(‘hello‘)
res=tuple({‘x‘:1,‘y‘:2})
print(res)
4.1、常用操作+内置的方法
优先掌握的操作:
1、按索引取值(正向取+反向取):只能取
t=(‘a‘,‘b‘,1)
t[0]=111
2、切片(顾头不顾尾,步长)
t=(‘h‘,‘e‘,‘l‘,‘l‘,‘o‘)
res=t[1:3]
print(res)
print(t)
3、长度
t=(‘h‘,‘e‘,‘l‘,‘l‘,‘o‘)
print(len(t))
4、成员运算in和not in
t=(‘h‘,‘e‘,‘l‘,‘l‘,‘o‘)
print(‘h‘ in t)
5、循环
t=(‘h‘,‘e‘,‘l‘,‘l‘,‘o‘)
for item in t:
print(item)
该类型总结 :存多个值,有序,不可变(1、可变:值变,id不变。可变==不可hash 2、不可变:值变,id就变。不可变==可hash)
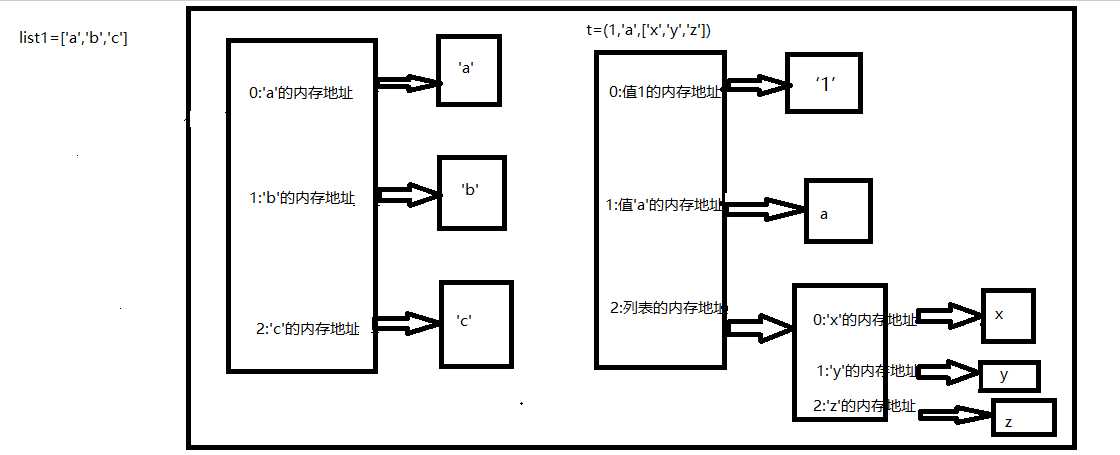
t=(1,‘a‘,[‘x‘,‘y‘,‘z‘])
# print(id(t[2]))
# print(id(t))
t[2][0]=‘X‘
print(t)
print(id(t))
print(id(t[2]))
list1=[‘a‘,‘b‘,‘c‘]
print(id(list1[0]))
print(id(list1[1]))
print(id(list1[2]))
print(‘=‘*50)
list1[1]=‘B‘
print(id(list1[0]))
print(id(list1[1]))
print(id(list1[2]))
t=(‘a‘,‘b‘,‘a‘)
print(t.index(‘a‘))
t.index(‘xxx‘)
4.2 、可变类型与不可变类型图解分析
五、字典类型
字典的特性:
增加

>>> info["stu1104"] = "苍井空"
>>> info
{‘stu1102‘: ‘LongZe Luola‘, ‘stu1104‘: ‘苍井空‘, ‘stu1103‘: ‘XiaoZe Maliya‘, ‘stu1101‘: ‘TengLan Wu‘}
修改
>>> info[‘stu1101‘] = "武藤兰"
>>> info
{‘stu1102‘: ‘LongZe Luola‘, ‘stu1103‘: ‘XiaoZe Maliya‘, ‘stu1101‘: ‘武藤兰‘}
删除
>>> info
{‘stu1102‘: ‘LongZe Luola‘, ‘stu1103‘: ‘XiaoZe Maliya‘, ‘stu1101‘: ‘武藤兰‘}
>>> info.pop("stu1101") #标准删除姿势
‘武藤兰‘
>>> info
{‘stu1102‘: ‘LongZe Luola‘, ‘stu1103‘: ‘XiaoZe Maliya‘}
>>> del info[‘stu1103‘] #换个姿势删除
>>> info
{‘stu1102‘: ‘LongZe Luola‘}
>>>
>>>
>>>
>>> info = {‘stu1102‘: ‘LongZe Luola‘, ‘stu1103‘: ‘XiaoZe Maliya‘}
>>> info
{‘stu1102‘: ‘LongZe Luola‘, ‘stu1103‘: ‘XiaoZe Maliya‘} #随机删除
>>> info.popitem()
(‘stu1102‘, ‘LongZe Luola‘)
>>> info
{‘stu1103‘: ‘XiaoZe Maliya‘}
查找
>>> info = {‘stu1102‘: ‘LongZe Luola‘, ‘stu1103‘: ‘XiaoZe Maliya‘}
>>>
>>> "stu1102" in info #标准用法
True
>>> info.get("stu1102") #获取
‘LongZe Luola‘
>>> info["stu1102"] #同上,但是看下面
‘LongZe Luola‘
>>> info["stu1105"] #如果一个key不存在,就报错,get不会,不存在只返回None
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: ‘stu1105‘
多级字典嵌套及操作
av_catalog = {
"欧美":{
"www.youporn.com": ["很多免费的,世界最大的","质量一般"],
"www.pornhub.com": ["很多免费的,也很大","质量比yourporn高点"],
"letmedothistoyou.com": ["多是自拍,高质量图片很多","资源不多,更新慢"],
"x-art.com":["质量很高,真的很高","全部收费,屌比请绕过"]
},
"日韩":{
"tokyo-hot":["质量怎样不清楚,个人已经不喜欢日韩范了","听说是收费的"]
},
"大陆":{
"1024":["全部免费,真好,好人一生平安","服务器在国外,慢"]
}
}
av_catalog["大陆"]["1024"][1] += ",可以用爬虫爬下来"
print(av_catalog["大陆"]["1024"])
#ouput
[‘全部免费,真好,好人一生平安‘, ‘服务器在国外,慢,可以用爬虫爬下来‘]
其他操作
#values
>>> info.values()
dict_values([‘LongZe Luola‘, ‘XiaoZe Maliya‘])
#keys
>>> info.keys()
dict_keys([‘stu1102‘, ‘stu1103‘])
#setdefault
#setdefault:key不存在则设置默认值,并且将默认值添加到values中
#key存在则不设置默认,并且返回已经有的值
>>> info.setdefault("stu1106","Alex")
‘Alex‘
>>> info
{‘stu1102‘: ‘LongZe Luola‘, ‘stu1103‘: ‘XiaoZe Maliya‘, ‘stu1106‘: ‘Alex‘}
>>> info.setdefault("stu1102","龙泽萝拉")
‘LongZe Luola‘
>>> info
{‘stu1102‘: ‘LongZe Luola‘, ‘stu1103‘: ‘XiaoZe Maliya‘, ‘stu1106‘: ‘Alex‘}
#update
>>> info
{‘stu1102‘: ‘LongZe Luola‘, ‘stu1103‘: ‘XiaoZe Maliya‘, ‘stu1106‘: ‘Alex‘}
>>> b = {1:2,3:4, "stu1102":"龙泽萝拉"}
>>> info.update(b)
>>> info
{‘stu1102‘: ‘龙泽萝拉‘, 1: 2, 3: 4, ‘stu1103‘: ‘XiaoZe Maliya‘, ‘stu1106‘: ‘Alex‘}
#items
info.items()
dict_items([(‘stu1102‘, ‘龙泽萝拉‘), (1, 2), (3, 4), (‘stu1103‘, ‘XiaoZe Maliya‘), (‘stu1106‘, ‘Alex‘)])
#通过一个列表生成默认dict,有个没办法解释的坑,少用吧这个
>>> dict.fromkeys([1,2,3],‘testd‘)
{1: ‘testd‘, 2: ‘testd‘, 3: ‘testd‘}
循环dict
#方法1
for key in info:
print(key,info[key])
#方法2
for k,v in info.items(): #因为会先把dict转成list,速度慢,数据里大时莫用
print(k,v)
六 、集合
a = t | s # t 和 s的并集
b = t & s # t 和 s的交集
c = t – s # 求差集(项在t中,但不在s中)
d = t ^ s # 对称差集(项在t或s中,但不会同时出现在二者中)
# set 无序,不重复序列
# 创建
# se = {‘123‘,345}
# print(type(se))
# s = set() # 创建一个空集合
# # 对比,之前我们把元祖转换成列表的方法
# l = list((1,2,3))
# print(l) # [1, 2, 3] 实际里面运行了for循环,也就是init方法
#
# s1 = set(l)
# print(s1) # {1, 2, 3} 集合还有一个机制就是,如果有相同的就会去除
# 功能
# s = set()
# s.add(1)
# s.add(1)
# print(s) # {1}
# s.clear()
# print(s) # 清空
# 差集
s1 = {11,22,33}
s2 = {22,33,44}
# s3= s1.difference(s2) # s1中存在,s2中不存在 {11}
# s1.difference_update(s2) 更新到s1里面,不需要创建新的集合
# print(s3)
# 对称差集
# s3 = s1.symmetric_difference(s2) # 对称差集 {11, 44}
# s1.symmetric_difference_update(s2) 更新到s1里面,不需要创建新的集合
# print(s3)
# 删除
# s1.discard(11)
# print(s1) # {33, 22} 移除指定元素,不存在不报错
# s1.remove(11)
# print(s1) {33, 22} ,不存在报错
# ret = s1.pop() 随机的,有返回值
# print(ret)
# 交集
# ret = s1.intersection(s2)
# print(ret) {33, 22}
# s1.intersection_update(s2)
# ret = s1.isdisjoint(s2)
# print(ret) # 没有交集返回true,有交集返回true
# s1.issubset() # 是否是子序列,包含的关系
# s1.issuperset() # 是否是父序列,被包含的关系
# 并集
# ret = s1.union(s2)
# print(ret) {33, 22, 11, 44} 并集
# li = [1,2,3]
# s1.update(li) # 接收一个可迭代的相比add,它可以添加个序列,并且循环执行add
#
# print(s1) # {33, 2, 3, 1, 11, 22}
6.1、什么是集合
在{}内用逗号分隔开多个值,集合的特点:
1. 每个值必须是不可变类型
2. 集合无序
3. 集合内元素不能重复
6.2、 为何要用集合
1. 用于做关系运算
2. 去重
集合的第一大用途: 关系运算
pythons={‘egon‘,‘张铁蛋‘,‘李铜蛋‘,‘赵银弹‘,‘王金蛋‘,‘艾里克斯‘}
linuxs={‘欧德博爱‘,‘李铜蛋‘,‘艾里克斯‘,‘lsb‘,‘ysb‘,‘wsb‘}
求同时报名两门课程的学生姓名:交集
print(pythons & linuxs)
print(pythons.intersection(linuxs))
pythons=pythons & linuxs
print(pythons) #{‘李铜蛋‘, ‘艾里克斯‘}
pythons.intersection_update(linuxs) #pythons=pythons.intersection(linuxs)
print(pythons) #{‘艾里克斯‘, ‘李铜蛋‘}
求报名学校课程的所有学生姓名:并集
print(pythons | linuxs)
print(pythons.union(linuxs))
求只报名python课程的学生姓名: 差集
print(pythons - linuxs)
print(pythons.difference(linuxs))
print(linuxs - pythons) #求只报名linux课程的学生姓名
print(linuxs.difference(pythons))
求没有同时报名两门课程的学生姓名: 对称差集
print((pythons - linuxs) | (linuxs - pythons))
print(pythons ^ linuxs)
print(pythons.symmetric_difference(linuxs))
父子集:指的是一种包含与被包含的关系
s1={1,2,3}
s2={1,2}
print(s1 >= s2)
print(s1.issuperset(s2))
print(s2.issubset(s1))
情况一:
print(s1 > s2) #>号代表s1是包含s2的,称之为s1为s2的父集
print(s2 < s1)
情况二:
s1={1,2,3}
s2={1,2,3}
print(s1 == s2) #s1如果等于s2,也可以称为s1是s2的父集合
综上:
s1 >= s2 就可以称为s1是s2的父集
s3={1,2,3}
s4={3,2,1}
print(s3 == s4)
s5={1,2,3}
s6={1,2,3}
print(s5 >= s6)
print(s6 >= s5)
集合的第二大用途:去重
集合去重的局限性:
1. 会打乱原值的顺序
2. 只能针对不可变的值去重
stus=[‘egon‘,‘lxx‘,‘lxx‘,‘alex‘,‘alex‘,‘yxx‘]
new_l=list(set(stus))
print(new_l)
old_l=[1,[1,2],[1,2]]
set(old_l)
l = [
{‘name‘: ‘egon‘, ‘age‘: 18, ‘sex‘: ‘male‘},
{‘name‘: ‘alex‘, ‘age‘: 73, ‘sex‘: ‘male‘},
{‘name‘: ‘egon‘, ‘age‘: 20, ‘sex‘: ‘female‘},
{‘name‘: ‘egon‘, ‘age‘: 18, ‘sex‘: ‘male‘},
{‘name‘: ‘egon‘, ‘age‘: 18, ‘sex‘: ‘male‘},
]
new_l=[]
for dic in l:
if dic not in new_l:
new_l.append(dic)
print(new_l)
需要掌握的操作:
s1 = {1, 2, 3}
s1.update({3,4,5})
print(s1)
print(s1.pop())
print(s1)
s1.remove(2)
print(s1)
s1={1,2,3}
print(id(s1))
s1.add(4)
print(s1)
print(id(s1))
s1={1,2,3}
s1.discard(4)
s1.remove(4)
print(s1)
s1={1,2,3}
s2={4,5}
print(s1.isdisjoint(s2))
总结 : 存多个值 ; 无序 ; set可变
标签:不重复 hello 国外 disjoint 图解 value 方法 字符串 items
原文地址:https://www.cnblogs.com/596014054-yangdongsheng/p/9664982.html